Použití Sparku v poznámkových blocích
Ve Sparku můžete spouštět mnoho různých druhů aplikací, včetně kódu ve skriptech Pythonu nebo Scala, kódu Java zkompilovaného jako Java Archive (JAR) a dalších. Spark se běžně používá ve dvou typech úloh:
- Úlohy dávkového zpracování nebo zpracování datových proudů za účelem ingestování, čištění a transformace dat – často běží jako součást automatizovaného kanálu.
- Interaktivní analytické relace pro zkoumání, analýzu a vizualizaci dat
Základy úprav poznámkového bloku & kódu
Poznámkové bloky Databricks jsou primárním pracovním prostorem pro datové vědy, inženýrství a analýzy. Jsou postavené na buňkách, které můžou obsahovat kód nebo formátovaný text (Markdown). Tento přístup založený na buňkách usnadňuje experimentování, testování a vysvětlení práce na jednom místě. Můžete spustit jednu buňku, skupinu buněk nebo celý poznámkový blok s výstupy, jako jsou tabulky, grafy nebo prostý text, které se zobrazují přímo pod spuštěnou buňkou. Buňky se dají uspořádat, sbalit nebo vymazat, aby byl poznámkový blok uspořádaný a čitelný.
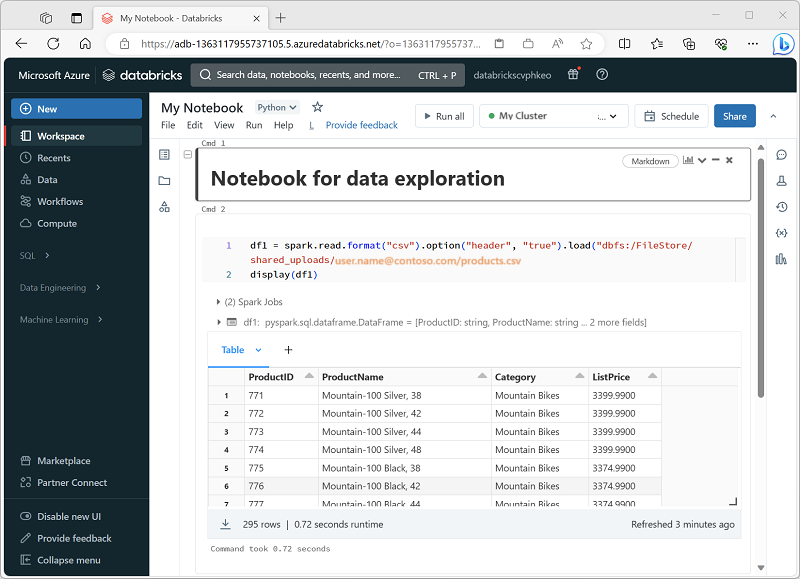
Hlavní síla poznámkových bloků Databricks je podpora více jazyků. I když je výchozí často Python, můžete v rámci stejného poznámkového bloku přepnout na JAZYK SQL, Scala nebo R pomocí příkazů magic, jako jsou %sql nebo %scala. Tato flexibilita znamená, že můžete psát logiku ETL v SQL, kód strojového učení v Pythonu a pak vizualizovat výsledky pomocí jazyka R – to vše v jednom pracovním postupu. Databricks také poskytuje automatické dokončování a zvýrazňování syntaxe, což usnadňuje zachycení chyb a zrychlení kódování.
Před spuštěním jakéhokoli kódu musí být poznámkový blok připojený ke clusteru. Bez připojeného clusteru nelze buňky kódu spustit. Z panelu nástrojů poznámkového bloku můžete vybrat existující cluster nebo vytvořit nový a poznámkové bloky můžete podle potřeby snadno odpojit a znovu připojit. Toto připojení umožňuje vašemu notebooku využívat distribuovaný výpočetní výkon na Azure Databricks.
Použití nástroje Databricks Assistant
Databricks Assistant je průvodce kódováním založený na umělé inteligenci integrovaný přímo do poznámkových bloků. Jeho cílem je pomoct vám efektivněji psát, pochopit a zlepšit kód využitím kontextu z poznámkového bloku a pracovního prostoru. Může generovat nový kód z výzev přirozeného jazyka, vysvětlit složitou logiku, navrhovat opravy chyb, optimalizovat výkon a dokonce refaktorovat nebo formátovat kód pro čitelnost. To je cenné nejen pro začátečníky, kteří se učí Spark nebo SQL, ale také pro zkušené uživatele, kteří chtějí urychlit vývoj a snížit opakující se práci.
Pomocník je kontextově vnímavý, což znamená, že může používat informace o vašem poznámkovém bloku, clusteru a datovém prostředí, aby poskytoval přizpůsobené návrhy. Pokud má váš pracovní prostor například povolený katalog Unity, může při psaní dotazů SQL načíst metadata, jako jsou názvy tabulek, názvy sloupců a schémata. To vám umožní zeptat se na něco jako "Vybrat průměrnou částku prodeje podle oblasti z prodejní tabulky" a získat funkční kód SQL, který odpovídá vašemu skutečnému datovému modelu. Podobně můžete v Pythonu požádat o vytvoření transformací dat nebo úloh Sparku, aniž byste museli odvolat každý podpis funkce z paměti.
S asistentem komunikujete dvěma hlavními způsoby:
Výzvy v přirozeném jazyce – v rozhraní podobném chatu můžete psát jednoduché pokyny v angličtině a kód se vloží do poznámkového bloku.
Příkazy lomítkem – rychlé příkazy, například
/explain,/fixnebo/optimize, které umožňují pracovat s vybraným kódem. Například rozdělí složitou funkci do jednodušších kroků,/explainmůže se pokusit vyřešit chyby syntaxe nebo modulu runtime a/fixnavrhne vylepšení výkonu,/optimizejako je opětovné rozdělení nebo použití efektivních funkcí Sparku.

Výkonnou funkcí je režim úprav, ve kterém může asistent navrhovat větší strukturální změny ve více buňkách. Může například refaktorovat opakovanou logiku do jedné opakovaně použitelné funkce nebo změnit strukturu pracovního postupu pro lepší čitelnost. Vždy máte kontrolu: návrhy nejsou nedestruktivní, což znamená, že je můžete před použitím změn v poznámkovém bloku zkontrolovat a přijmout nebo odmítnout.
Sdílení a modularizace kódu
Aby se zabránilo duplikování a zlepšení udržovatelnosti, Databricks podporuje vložení opakovaně použitelného kódu do souborů (například modulů .py) v pracovním prostoru, který můžou poznámkové bloky importovat. Existují mechanismy pro orchestraci poznámkových bloků (tj. spouštění poznámkových bloků z jiných poznámkových bloků nebo úloh s více úlohami), takže můžete vytvářet pracovní postupy, které používají sdílené funkce nebo moduly. Použití %run je jednodušší způsob, jak zahrnout jiný poznámkový blok, i když s určitými omezeními.
Ladění, historie verzí a vrácení chyb zpět
Databricks nabízí integrovaný interaktivní ladicí program pro poznámkové bloky Pythonu: můžete nastavit zarážky, krokovat provádění, kontrolovat proměnné a krok za krokem navigovat kódem. To pomáhá izolovat chyby efektivněji než ladění pomocí výpisů/záznamů.

Notebooky také automaticky udržují historii verzí: můžete zobrazit minulé snímky, přičíst popisy k verzím, obnovit staré verze nebo vymazat historii. Pokud používáte integraci Gitu, můžete synchronizovat poznámkové bloky a soubory verze v úložišti.

Návod
Další informace o práci s poznámkovými bloky v Azure Databricks najdete v článku Poznámkové bloky v dokumentaci k Azure Databricks.