Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V předchozí fázi tohoto kurzu jsme získali datovou sadu, pomocí které budeme trénovat model analýzy dat pomocí PyTorchu. Teď je čas tato data použít.
Pokud chcete vytrénovat model analýzy dat pomocí PyTorchu, musíte provést následující kroky:
- Načtěte data. Pokud jste provedli předchozí krok tohoto kurzu, už jste to zvládli.
- Definujte neurální síť.
- Definujte funkci ztráty.
- Natrénujte model na trénovacích datech.
- Otestujte síť na testovacích datech.
Definování neurální sítě
V tomto kurzu vytvoříte základní model neurální sítě se třemi lineárními vrstvami. Struktura modelu je následující:
Linear -> ReLU -> Linear -> ReLU -> Linear
Lineární vrstva aplikuje lineární transformaci na příchozí data. Musíte zadat počet vstupních funkcí a počet výstupních funkcí, které by měly odpovídat počtu tříd.
Vrstva ReLU je aktivační funkce, která definuje všechny příchozí funkce, které mají být 0 nebo vyšší. Když se tedy použije vrstva ReLU, změní se jakékoli číslo menší než 0 na nulu, zatímco ostatní se zachovávají stejně. Aktivační vrstvu použijeme na dvě skryté vrstvy a na poslední lineární vrstvě nebudeme aktivovat.
Parametry modelu
Parametry modelu závisí na našem cíli a trénovacích datech. Velikost vstupu závisí na počtu funkcí, které model podáváme – čtyři v našem případě. Velikost výstupu je tři, protože existují tři možné typy Irises.
S třemi lineárními vrstvami (4,24) -> (24,24) -> (24,3)bude mít síť 744 váhy (96+576+72).
Rychlost učení (lr) určuje, jak moc upravujete váhy naší sítě s ohledem na gradient ztráty. Tím nižším je, tím pomalejší bude trénování. V tomto kurzu nastavíte lr na hodnotu 0.01.
Jak síť funguje?
Tady vytváříme dopřednou neuronovou síť. Během trénování síť zpracuje vstup přes všechny vrstvy, vypočítá ztrátu, aby pochopila, jak daleko se předpovězený popisek obrázku liší od správného, a propašuje gradienty zpět do sítě za účelem aktualizace váhy vrstev. Iterací nad obrovskou datovou sadou vstupů se síť "naučí" nastavit své váhy, aby dosáhla nejlepších výsledků.
Funkce forward vypočítá hodnotu funkce ztráty a zpětná funkce vypočítá přechody zjistitelných parametrů. Když vytváříte naši neurální síť pomocí PyTorchu, stačí definovat funkci forward. Zpětná funkce bude automaticky definována.
- Zkopírujte do souboru v sadě Visual Studio následující kód
DataClassifier.py, který definuje parametry modelu a neurální síť.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Budete také muset definovat spouštěcí zařízení na základě dostupného zařízení na vašem počítači. PyTorch nemá vyhrazenou knihovnu pro GPU, ale můžete ručně definovat spouštěcí zařízení. Zařízení bude gpu Nvidia, pokud na vašem počítači existuje, nebo procesor, pokud ho nemáte.
- Zkopírujte následující kód, který definuje spouštěcí zařízení:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Jako poslední krok definujte funkci pro uložení modelu:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Poznámka:
Zajímá vás další informace o neurální síti pomocí PyTorchu? Projděte si dokumentaci k PyTorchu.
Definování funkce ztráty
Funkce ztráty vypočítá hodnotu, která odhaduje, jak daleko je výstup od cíle. Hlavním cílem je snížit hodnotu funkce ztráty změnou hodnot vektoru hmotnosti prostřednictvím zpětného šíření v neurálních sítích.
Hodnota ztráty se liší od přesnosti modelu. Funkce ztráty představuje, jak dobře se náš model chová po každé iteraci optimalizace trénovací sady. Přesnost modelu se vypočítá na testovacích datech a zobrazuje procento předpovědí, které jsou správné.
V PyTorch obsahuje balíček neurální sítě různé funkce ztráty, které tvoří stavební bloky hlubokých neurálních sítí. Pokud se chcete dozvědět více o těchto specifikách, začněte s výše uvedenou poznámkou. Tady použijeme existující funkce optimalizované pro klasifikaci a použijeme funkci ztráty křížové entropie pro klasifikaci a optimalizátor Adam. V optimalizátoru nastaví rychlost učení (lr) kontrolu nad tím, jak moc upravujete váhy sítě vzhledem k gradientu ztráty. Tady ji nastavíte jako 0,001 – tím nižší je, tím pomalejší bude trénování.
- Zkopírujte do
DataClassifier.pysouboru v sadě Visual Studio následující kód, který definuje funkci ztráty a optimalizátor.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Natrénujte model na trénovacích datech.
Pokud chcete model vytrénovat, musíte procházet přes iterátor dat, předat vstupy do sítě a optimalizovat. Pokud chcete ověřit výsledky, jednoduše porovnáte předpovězené popisky se skutečnými popisky v ověřovací datové sadě po každé epochě trénování.
Program zobrazí ztrátu trénování, ztrátu ověření a přesnost modelu pro každou epochu nebo pro každou úplnou iteraci v trénovací sadě. Uloží model s nejvyšší přesností a po 10 epochách program zobrazí konečnou přesnost.
- Do souboru přidejte následující kód
DataClassifier.py.
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Otestujte model na testovacích datech.
Teď, když jsme model vytrénovali, můžeme model otestovat pomocí testovací datové sady.
Přidáme dvě testovací funkce. První testuje model, který jste uložili v předchozí části. Otestuje model s testovací datovou sadou z 45 položek a zobrazí přesnost modelu. Druhá je volitelná funkce, která testuje důvěru modelu při předpovídání každého ze tří druhů duhovky reprezentované pravděpodobností úspěšné klasifikace jednotlivých druhů.
- Do souboru
DataClassifier.pypřidejte následující kód.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Nakonec přidáme hlavní kód. Tím zahájíte trénování modelu, uložíte ho a zobrazíte výsledky na obrazovce. Na trénovací sadě spustíme jenom dvě iterace [num_epochs = 25] , takže proces trénování nebude trvat příliš dlouho.
- Do souboru
DataClassifier.pypřidejte následující kód.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Pojďme test spustit! Ujistěte se, že jsou rozevírací nabídky na horním panelu nástrojů nastavené na Debug. Změňte Solution Platform na x64 pro spuštění projektu na vašem místním počítači, pokud je vaše zařízení 64bitové, nebo na x86, pokud je 32bitové.
- Pokud chcete projekt spustit, klikněte na
Start Debuggingtlačítko na panelu nástrojů nebo stiskněteF5.
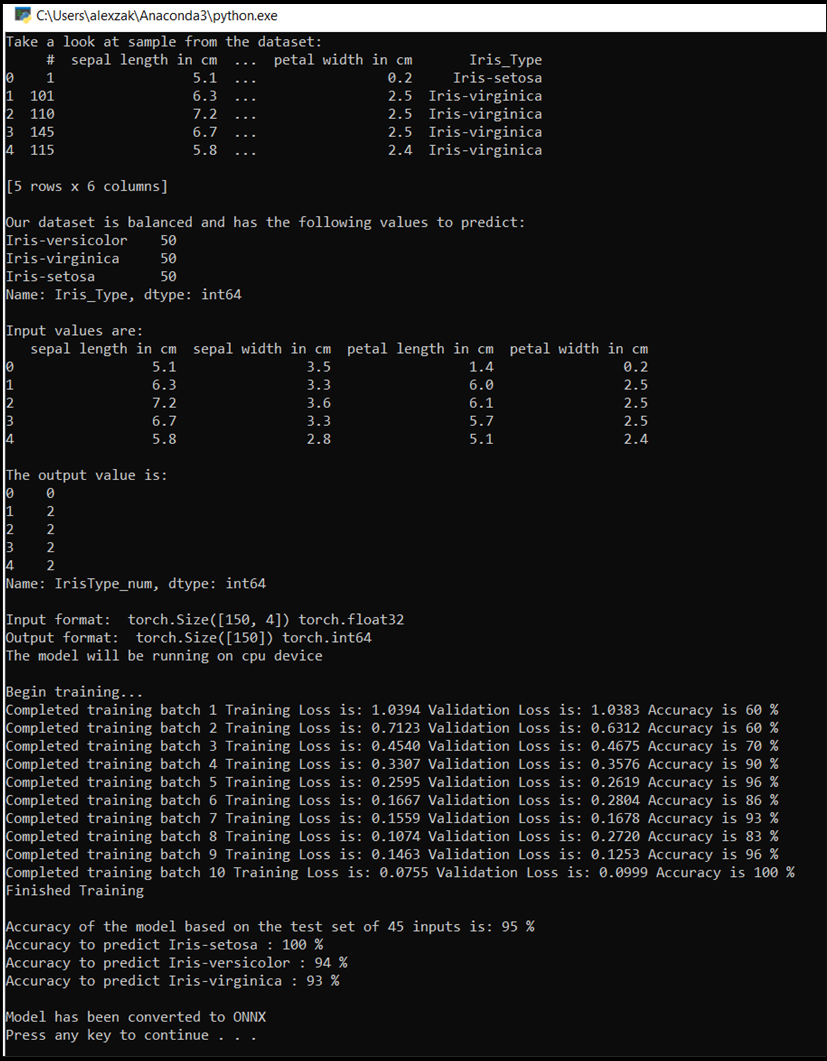
Otevře se okno konzoly a uvidíte proces trénování. Jak jste definovali, hodnota ztráty se vytiskne každou epochu. Očekává se, že se hodnota ztráty sníží s každým cyklem.
Po dokončení trénování byste měli očekávat, že uvidíte výstup podobný následujícímu. Vaše čísla nebudou úplně stejná – výcvik závisí na mnoha faktorech a nebude vždy vracet identické výsledky, ale měly by vypadat podobně.
Další kroky
Teď, když máme klasifikační model, je dalším krokem převod modelu do formátu ONNX.