Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Shell obor názvů uspořádává systém souborů a další objekty spravované Shellem do jediné stromové hierarchie. Koncepčně se jedná o větší a inkluzivnější verzi systému souborů.
Úvod
Jednou z hlavních zodpovědností Shellu je správa a poskytnutí přístupu k široké škále objektů, které tvoří systém. Nejčetnějšími a známými těmito objekty jsou složky a soubory, které se nacházejí na diskových jednotkách počítače. Prostředí však spravuje celou řadu systémových souborů nebo virtuálních objektů. Mezi příklady patří:
- Síťové tiskárny
- Jiné síťové počítače
- Aplikace Ovládacích panelů
- Koš
Některé virtuální objekty vůbec nezahrnují fyzické úložiště. Například objekt tiskárny obsahuje kolekci odkazů na síťové tiskárny. Jiné virtuální objekty, například Koš, můžou obsahovat data uložená na diskové jednotce, ale musí se zpracovávat jinak než běžné soubory. Například virtuální objekt lze použít k reprezentaci dat uložených v databázi. Z hlediska oboru názvů se různé položky v databázi můžou v Průzkumníku Windows objevit jako samostatné objekty, i když jsou všechny uloženy v jednom souboru disku.
Virtuální objekty se můžou nacházet i ve vzdálených počítačích. Například pro usnadnění roamingu můžou být soubory dokumentů uživatele uložené na serveru. Pokud chcete uživatelům udělit přístup ke svým souborům z více stolních počítačů, bude složka Dokumenty na stolním počítači, kterou aktuálně používají, odkazovat na server, nikoli na pevný disk stolního počítače. Jeho cesta bude obsahovat buď mapovanou síťovou jednotku, nebo název cesty UNC.
Stejně jako systém souborů obsahuje obor názvů dva základní typy objektů: složky a soubory. Objekty složek jsou uzly stromu; jsou kontejnery pro objekty souborů a další složky. Objekty souboru jsou listy stromu; jedná se o normální diskové soubory nebo virtuální objekty, jako jsou například odkazy na tiskárny. Složky, které nejsou součástí systému souborů, se někdy označují jako virtuální složky.
Stejně jako složky systému souborů se kolekce virtuálních složek obecně liší od systému po systém. Existují tři třídy virtuálních složek:
- Standardní virtuální složky, jako je koš, které se nacházejí ve všech systémech.
- Volitelné virtuální složky, které mají standardní názvy a funkce, ale nemusí být přítomné ve všech systémech.
- Nestandardní složky, které uživatel instaluje.
Na rozdíl od složek souborového systému nemohou uživatelé sami vytvářet nové virtuální složky. Můžou instalovat jenom ty, které vytvořili vývojáři jiných výrobců než Microsoft. Počet virtuálních složek je tedy obvykle mnohem menší než počet složek v souborovém systému. Diskuzi o tom, jak implementovat virtuální složky, naleznete v tématu Rozšíření oboru názvů.
Na panelu Průzkumníka Windows můžete vidět vizuální znázornění struktury oboru názvů. Například následující snímek obrazovky Průzkumníka Windows ukazuje relativně jednoduchý obor názvů.
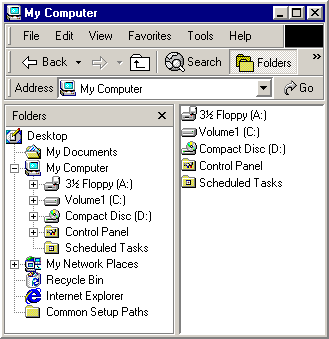
Nejvyšší úroveň hierarchie oboru názvů je pracovní plocha. Bezprostředně pod kořenem je několik virtuálních složek, jako je Můj počítač a Koš.
Systémy souborů různých diskových jednotek mohou být podmnožinou větší hierarchie oborů názvů. Kořeny těchto systémů souborů jsou podsložky složky Můj počítač. Tento počítač obsahuje také kořeny všech namapovaných síťových jednotek. Další uzly ve stromu, například Dokumenty, jsou virtuální složky.
Identifikace objektů jmenného prostoru
Než budete moct použít objekt oboru názvů, musíte ho nejdřív identifikovat. Objekt v systému souborů může mít název, například MyFile.htm. Vzhledem k tomu, že můžou existovat jiné soubory s tímto názvem jinde v systému, vyžaduje jedinečná identifikace souboru nebo složky plně kvalifikovanou cestu, například "C:\MyDocs\MyFile.htm". Tato cesta je v podstatě uspořádaný seznam všech složek v cestě od kořenového adresáře systému souborů C:\, končícího souborem.
V kontextu oboru názvů jsou cesty stále docela užitečné pro identifikaci objektů umístěných v části systému souborů oboru názvů. Nelze je však použít pro virtuální objekty. Místo toho Shell poskytuje alternativní způsob identifikace, který lze použít s libovolným objektem v rámci oboru názvů.
ID položek
V rámci složky má každý objekt ID položky, což je funkční ekvivalent názvu souboru nebo složky. ID položky je ve skutečnosti struktura SHITEMID:
typedef struct _SHITEMID {
USHORT cb;
BYTE abID[1];
} SHITEMID, * LPSHITEMID;
abID člen je identifikátor objektu. Délka abID není definována a její hodnota je určena složkou, která obsahuje objekt. Vzhledem k tomu, že neexistuje žádná standardní definice, jak abID hodnoty jsou přiřazeny složkami, jsou smysluplné pouze pro přidružený objekt složky. Aplikace by je měly jednoduše považovat za token, který identifikuje objekt v určité složce. Protože délka abID se různí, člen cb obsahuje velikost struktury SHITEMID, vyjádřenou v bajtech.
Vzhledem k tomu, že ID položek nejsou užitečná pro účely zobrazení, přiřadí složka obsahující objekt obvykle zobrazovaný název. Toto je název, který používá Průzkumník Windows při zobrazení obsahu složky. Další informace o tom, jak se zobrazované názvy zpracovávají, najdete v tématu Získání informací ze složky.
Seznamy ID položky
ID položky se zřídka používá samostatně. Za normálních okolností je součástí seznamu ID položky, který slouží stejnému účelu jako cesta k systému souborů. Ovšem místo znakového řetězce používaného pro cesty je seznam ID položky strukturou typu ITEMIDLIST. Tato struktura je seřazená posloupnost jednoho nebo více ID položky, ukončená dvojbajtovou hodnotou NULL. Každé ID položky v seznamu ID položky odpovídá objektu oboru názvů. Jejich pořadí definuje cestu v oboru názvů, podobně jako cesta k systému souborů.
Následující obrázek znázorňuje schéma struktury ITEMIDLIST, která odpovídá C:\MyDocs\MyFile.htm. Nad každým ID položky je zobrazen jeho název. Různé šířky členů abID jsou nahodilé; ilustrují skutečnost, že velikost členů se může lišit.

PIDLs
Pro rozhraní API prostředí jsou objekty oboru názvů obvykle identifikovány ukazatelem na jejich ITEMIDLIST struktury nebo ukazatelem na seznam identifikátorů položek (PIDL). Termín PIDL bude pro usnadnění používání obecně odkazovat v této dokumentaci na samotnou strukturu, nikoli na ukazatel na ni.
PIDL zobrazený na předchozím obrázku se označuje jako úplnánebo absolutní, PIDL. Úplný PIDL začíná na ploše a obsahuje ID položek všech zprostředkujících složek v cestě. Končí ID položky objektu následované ukončovacím dvoubajtovým NULL. Úplné PIDL je podobné plně kvalifikované cestě a jednoznačně identifikuje objekt v oboru názvů Shell.
Úplné PIDL se používají zřídka. Mnoho funkcí a metod očekává relativníPIDL . Kořen relativního PIDL je složka, nikoli pracovní plocha. Stejně jako u relativních cest definuje řada ID položek, které tvoří strukturu, cestu v oboru názvů mezi dvěma objekty. I když objekt jednoznačně neidentifikují, jsou obvykle menší než úplná piDL a dostatečná pro mnoho účelů.
Nejčastěji používané relativní PIDLy, jednoúrovňové PIDLy, jsou ve vztahu k nadřazené složce objektu. Obsahují pouze ID položky objektu a ukončující NULL. Víceúrovňové PIDLs se používají také pro mnoho účelů. Obsahují dvě nebo více ID položek a obvykle definují cestu z nadřazené složky k objektu prostřednictvím řady jedné nebo více podsložek. Všimněte si, že jednoúrovňový PIDL může být stále plně kvalifikovaný PIDL. Konkrétně objekty na ploše jsou její podřízené objekty, takže jejich plně kvalifikované PIDLs obsahují pouze jednu ID položky.
Jak je popsáno v tématu Získání ID složky, rozhraní API prostředí poskytuje řadu způsobů, jak načíst PIDL objektu. Jakmile ho budete mít, obvykle ho použijete k identifikaci objektu při volání dalších funkcí a metod rozhraní API prostředí. V tomto kontextu je interní obsah PIDL neprůhlený a irelevantní. Pro účely této diskuze si pidly představte jako tokeny, které představují konkrétní objekty oboru názvů, a zaměřte se na jejich použití pro běžné úlohy.
Přidělování PIDLů
I když PIDLy mají určitou podobnost s cestami, jejich použití vyžaduje odlišný přístup. Hlavním rozdílem je v tom, jak přidělit a uvolnit paměť pro ně.
Podobně jako řetězec použitý pro cestu musí být paměť přidělena pro PIDL. Pokud aplikace vytvoří PIDL, musí přidělit dostatečnou paměť pro ITEMIDLIST struktury. Ve většině zde probíraných případů vytvoří PIDL prostředí Shell a zpracuje přidělení paměti. Bez ohledu na to, co přidělilo PIDL, aplikace je obvykle zodpovědná za uvolnění PIDL, když už není potřeba.
Pomocí funkce CoTaskMemAlloc přidělte PIDL a funkci CoTaskMemFree uvolněte.