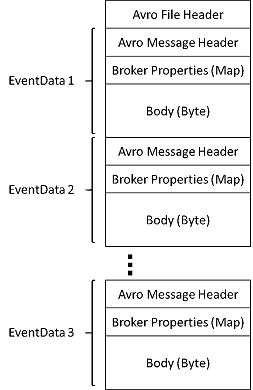
This article provides the schema for Avro files captured by Azure Event Hubs and a few tools to explore the files.
Schema
The Avro files produced by Event Hubs Capture have the following Avro schema:
Azure Storage Explorer
You can verify that captured files were created in the Azure Storage account using tools such as Azure Storage Explorer. You can download files locally to work on them.
An easy way to explore Avro files is by using the Avro Tools jar from Apache. You can also use Apache Spark to perform complex distributed processing on the ingested data.
Use Apache Spark
Apache Spark is a "unified analytics engine for large-scale data processing." It supports different languages, including SQL, and can easily access Azure Blob storage. There are a few options to run Apache Spark in Azure, and each provides easy access to Azure Blob storage:
Avro Tools are available as a jar package. After you download the jar file, you can see the schema of a specific Avro file by running the following command:
shell
java -jar avro-tools-1.9.1.jar getschema <name of capture file>
You can also use Avro Tools to convert the file to JSON format and perform other processing.
To perform more advanced processing, download and install Avro for your choice of platform. At the time of this writing, there are implementations available for C, C++, C#, Java, NodeJS, Perl, PHP, Python, and Ruby.
Event Hubs Capture is the easiest way to get data into Azure. Using Azure Data Lake, Azure Data Factory, and Azure HDInsight, you can perform batch processing and other analytics using familiar tools and platforms of your choosing, at any scale you need. See the following articles to learn more about this feature.
Demonstrer forståelsen af almindelige datatekniske opgaver for at implementere og administrere arbejdsbelastninger til datakonstruktion på Microsoft Azure ved hjælp af en række Azure-tjenester.