Apache Spark operations supported by Hive Warehouse Connector in Azure HDInsight
This article shows spark-based operations supported by Hive Warehouse Connector (HWC). All examples shown will be executed through the Apache Spark shell.
Prerequisite
Complete the Hive Warehouse Connector setup steps.
Getting started
To start a spark-shell session, do the following steps:
Use ssh command to connect to your Apache Spark cluster. Edit the command by replacing CLUSTERNAME with the name of your cluster, and then enter the command:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netFrom your ssh session, execute the following command to note the
hive-warehouse-connector-assemblyversion:ls /usr/hdp/current/hive_warehouse_connectorEdit the code with the
hive-warehouse-connector-assemblyversion identified above. Then execute the command to start the spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseAfter you start the spark-shell, a Hive Warehouse Connector instance can be started using the following commands:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Creating Spark DataFrames using Hive queries
The results of all queries using the HWC library are returned as a DataFrame. The following examples demonstrate how to create a basic hive query.
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
The results of the query are Spark DataFrames, which can be used with Spark libraries like MLIB and SparkSQL.
Writing out Spark DataFrames to Hive tables
Spark doesn't natively support writing to Hive's managed ACID tables. However, using HWC, you can write out any DataFrame to a Hive table. You can see this functionality at work in the following example:
Create a table called
sampletable_coloradoand specify its columns using the following command:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()Filter the table
hivesampletablewhere the columnstateequalsColorado. This hive query returns a Spark DataFrame and result is saved in the Hive tablesampletable_coloradousing thewritefunction.hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()View the results with the following command:
hive.table("sampletable_colorado").show()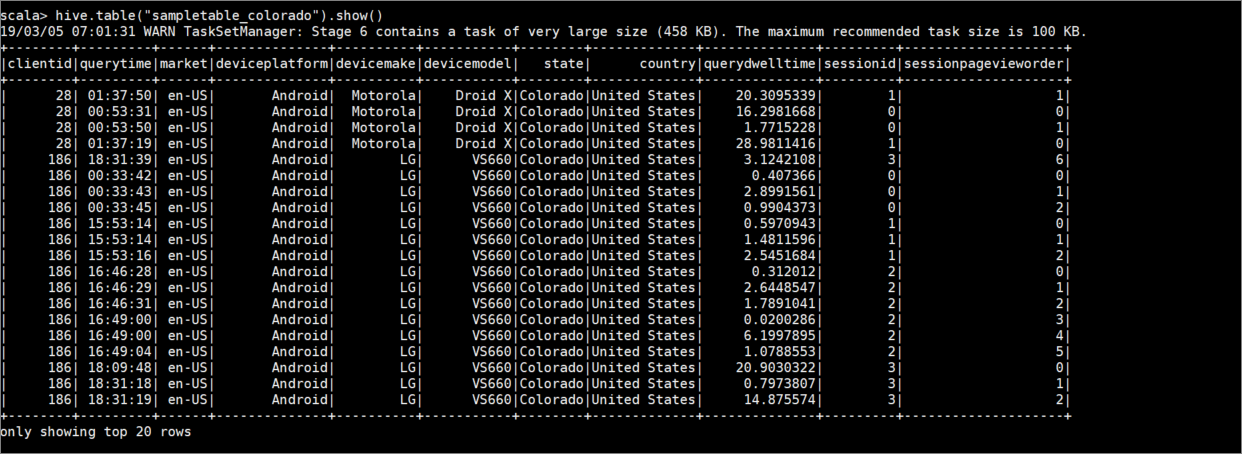
Structured streaming writes
Using Hive Warehouse Connector, you can use Spark streaming to write data into Hive tables.
Important
Structured streaming writes are not supported in ESP enabled Spark 4.0 clusters.
Follow the steps to ingest data from a Spark stream on localhost port 9999 into a Hive table via. Hive Warehouse Connector.
From your open Spark shell, begin a spark stream with the following command:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()Generate data for the Spark stream that you created, by doing the following steps:
- Open a second SSH session on the same Spark cluster.
- At the command prompt, type
nc -lk 9999. This command uses thenetcatutility to send data from the command line to the specified port.
Return to the first SSH session and create a new Hive table to hold the streaming data. At the spark-shell, enter the following command:
hive.createTable("stream_table").column("value","string").create()Then write the streaming data to the newly created table using the following command:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()Important
The
metastoreUrianddatabaseoptions must currently be set manually due to a known issue in Apache Spark. For more information about this issue, see SPARK-25460.Return to the second SSH session and enter the following values:
foo HiveSpark barReturn to the first SSH session and note the brief activity. Use the following command to view the data:
hive.table("stream_table").show()
Use Ctrl + C to stop netcat on the second SSH session. Use :q to exit spark-shell on the first SSH session.