How to deploy JAIS with Azure Machine Learning studio
In this article, you learn how to use Azure Machine Learning studio to deploy the JAIS model as a service with pay-as you go billing.
The JAIS model is available in Azure Machine Learning studio with pay-as-you-go token based billing with Models as a Service.
You can find the JAIS model in the model catalog by filtering on the JAIS collection.
Prerequisites
An Azure subscription with a valid payment method. Free or trial Azure subscriptions won't work. If you don't have an Azure subscription, create a paid Azure account to begin.
An Azure Machine Learning workspace. If you don't have these, use the steps in the Quickstart: Create workspace resources article to create them. The serverless API model deployment offering for JAIS is only available with workspaces created in these regions:
- East US
- East US 2
- North Central US
- South Central US
- West US
- West US 3
- Sweden Central
For a list of regions that are available for each of the models supporting serverless API endpoint deployments, see Region availability for models in serverless API endpoints.
Azure role-based access controls (Azure RBAC) are used to grant access to operations in Azure AI Foundry portal. To perform the steps in this article, your user account must be assigned the Azure AI Developer role on the resource group. For more information on permissions, see Role-based access control in Azure AI Foundry portal.
JAIS 30b Chat
JAIS 30b Chat is an auto-regressive bi-lingual LLM for Arabic & English. The tuned versions use supervised fine-tuning (SFT). The model is fine-tuned with both Arabic and English prompt-response pairs. The fine-tuning datasets included a wide range of instructional data across various domains. The model covers a wide range of common tasks including question answering, code generation, and reasoning over textual content. To enhance performance in Arabic, the Core42 team developed an in-house Arabic dataset as well as translating some open-source English instructions into Arabic.
Context length: JAIS 30b Chat supports a context length of 8K.
Input: Model input is text only.
Output: Model generates text only.
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Deploy with pay-as-you-go
Certain models in the model catalog can be deployed as a service with pay-as-you-go, providing a way to consume them as an API without hosting them on your subscription, while keeping the enterprise security and compliance organizations need. This deployment option doesn't require quota from your subscription.
The previously mentioned JAIS 30b Chat model can be deployed as a service with pay-as-you-go, and is offered by Core42 through the Microsoft Azure Marketplace. Core42 can change or update the terms of use and pricing of this model.
Create a new deployment
To create a deployment:
Select the workspace in which you want to deploy your models. To use the pay-as-you-go model deployment offering, your workspace must belong to the EastUS2 or Sweden Central region.
Search for JAIS and select the Jais-30b-chat model from the model catalog.
On the model's overview page in the model catalog, select Deploy.

In the deployment wizard, select the link to Azure Marketplace Terms to learn more about the terms of use.
You can also select the Pricing and terms tab to learn about pricing for the selected model.
If this is your first time deploying the model in the workspace, you have to subscribe your workspace for the particular offering of the model. This step requires that your account has the Azure AI Developer role permissions on the Resource Group, as listed in the prerequisites. Each workspace has its own subscription to the particular Azure Marketplace offering, which allows you to control and monitor spending. Select Subscribe and Deploy. Currently you can have only one deployment for each model within a workspace.
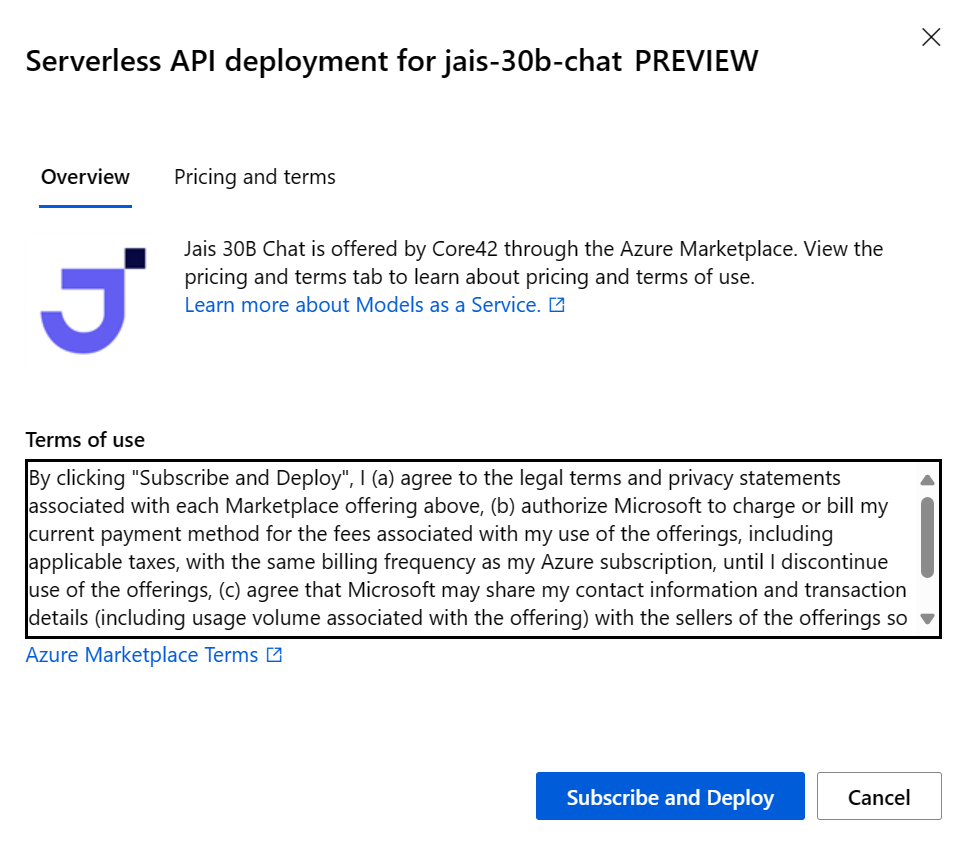
Once you subscribe the workspace for the particular Azure Marketplace offering, subsequent deployments of the same offering in the same workspace don't require subscribing again. If this scenario applies to you, there's a Continue to deploy option to select.

Give the deployment a name. This name becomes part of the deployment API URL. This URL must be unique in each Azure region.

Select Deploy. Wait until the deployment is finished and you're redirected to the serverless endpoints page.
Select the endpoint to open its Details page.
Select the Test tab to start interacting with the model.
You can always find the endpoint's details, URL, and access keys by navigating to Workspace > Endpoints > Serverless endpoints.
Take note of the Target URL and the Secret Key. For more information on using the APIs, see the reference section.




To learn about billing for models deployed with pay-as-you-go, see Cost and quota considerations for JAIS models deployed as a service.
Consume the JAIS 30b Chat model as a service
These models can be consumed using the chat API.
In your workspace, select Endpoints tab on the left.
Go to the Serverless endpoints tab.
Select your deployment for JAIS 30b Chat.
You can test the deployment in the Test tab.
To use the APIs, copy the Target URL and the Key value.
For more information on using the APIs, see the reference section.
Chat API reference for JAIS deployed as a service
v1/chat/completions
Request
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
v1/chat/completions request schema
JAIS 30b Chat accepts the following parameters for a v1/chat/completions response inference call:
| Property | Type | Default | Description |
|---|---|---|---|
messages |
array |
None |
Text input for the model to respond to. |
max_tokens |
integer |
None |
The maximum number of tokens the model generates as part of the response. Note: Setting a low value might result in incomplete generations. If not specified, generates tokens until end of sequence. |
temperature |
float |
0.3 |
Controls randomness in the model. Lower values will make the model more deterministic and higher values will make the model more random. |
top_p |
float |
None |
The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling, defaults to null. |
top_k |
integer |
None |
The number of highest probability vocabulary tokens to keep for top-k-filtering, defaults to null. |
A System or User Message supports the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
role |
enum |
Required | role=system or role=user. |
content |
string |
Required | Text input for the model to respond to. |
An Assistant Message supports the following properties:
| Property | Type | Default | Description |
|---|---|---|---|
role |
enum |
Required | role=assistant |
content |
string |
Required | The contents of the assistant message. |
v1/chat/completions response schema
The response payload is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
id |
string |
A unique identifier for the completion. |
choices |
array |
The list of completion choices the model generated for the input messages. |
created |
integer |
The Unix timestamp (in seconds) of when the completion was created. |
model |
string |
The model_id used for completion. |
object |
string |
chat.completion. |
usage |
object |
Usage statistics for the completion request. |
The choices object is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
index |
integer |
Choice index. |
messages or delta |
string |
Chat completion result in messages object. When streaming mode is used, delta key is used. |
finish_reason |
string |
The reason the model stopped generating tokens. |
The usage object is a dictionary with the following fields:
| Key | Type | Description |
|---|---|---|
prompt_tokens |
integer |
Number of tokens in the prompt. |
completion_tokens |
integer |
Number of tokens generated in the completion. |
total_tokens |
integer |
Total tokens. |
Examples
Arabic
Request:
"messages": [
{
"role": "user",
"content": "ما هي الأماكن الشهيرة التي يجب زيارتها في الإمارات؟"
}
]
Response:
{
"id": "df23b9f7-e6bd-493f-9437-443c65d428a1",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "هناك العديد من الأماكن المذهلة للزيارة في الإمارات! ومن أشهرها برج خليفة في دبي وهو أطول مبنى في العالم ، ومسجد الشيخ زايد الكبير في أبوظبي والذي يعد أحد أجمل المساجد في العالم ، وصحراء ليوا في الظفرة والتي تعد أكبر صحراء رملية في العالم وتجذب الكثير من السياح لتجربة ركوب الجمال والتخييم في الصحراء. كما يمكن للزوار الاستمتاع بالشواطئ الجميلة في دبي وأبوظبي والشارقة ورأس الخيمة، وزيارة متحف اللوفر أبوظبي للتعرف على تاريخ الفن والثقافة العالمية"
}
}
],
"created": 1711734274,
"model": "jais-30b-chat",
"object": "chat.completion",
"usage": {
"prompt_tokens": 23,
"completion_tokens": 744,
"total_tokens": 767
}
}
English
Request:
"messages": [
{
"role": "user",
"content": "List the emirates of the UAE."
}
]
Response:
{
"id": "df23b9f7-e6bd-493f-9437-443c65d428a1",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "The seven emirates of the United Arab Emirates are: Abu Dhabi, Dubai, Sharjah, Ajman, Umm Al-Quwain, Fujairah, and Ras Al Khaimah."
}
}
],
"created": 1711734274,
"model": "jais-30b-chat",
"object": "chat.completion",
"usage": {
"prompt_tokens": 23,
"completion_tokens": 60,
"total_tokens": 83
}
}
More inference examples
| Sample Type | Sample Notebook |
|---|---|
| CLI using CURL and Python web requests | webrequests.ipynb |
| OpenAI SDK (experimental) | openaisdk.ipynb |
| LiteLLM | litellm.ipynb |
Cost and quotas
Cost and quota considerations for models deployed as a service
JAIS 30b Chat is deployed as a service are offered by Core42 through the Azure Marketplace and integrated with Azure AI Foundry for use. You can find the Azure Marketplace pricing when deploying the model.
Each time a project subscribes to a given offer from the Azure Marketplace, a new resource is created to track the costs associated with its consumption. The same resource is used to track costs associated with inference; however, multiple meters are available to track each scenario independently.
For more information on how to track costs, see monitor costs for models offered throughout the Azure Marketplace.
Quota is managed per deployment. Each deployment has a rate limit of 200,000 tokens per minute and 1,000 API requests per minute. However, we currently limit one deployment per model per project. Contact Microsoft Azure Support if the current rate limits aren't sufficient for your scenarios.
Content filtering
Models deployed as a service with pay-as-you-go are protected by Azure AI Content Safety. With Azure AI content safety, both the prompt and completion pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering (preview) system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions. Learn more about content filtering here.