How to deploy Mistral models with Azure Machine Learning studio
In this article, you learn how to use Azure Machine Learning studio to deploy the Mistral family of models as serverless APIs with pay-as-you-go token-based billing.
Mistral AI offers two categories of models in Azure Machine Learning studio. These models are available in the model catalog.
- Premium models: Mistral Large (2402), Mistral Large (2407), Mistral Large (2411), Mistral Small, and Ministral-3B.
- Open models: Mistral Nemo, Mixtral-8x7B-Instruct-v01, Mixtral-8x7B-v01, Mistral-7B-Instruct-v01, and Mistral-7B-v01.
All the premium models and Mistral Nemo (an open model) can be deployed as serverless APIs with pay-as-you-go token-based billing. The other open models can be deployed to managed computes in your own Azure subscription.
You can browse the Mistral family of models in the model catalog by filtering on the Mistral collection.
Mistral family of models
Mistral Large models are Mistral AI's most advanced Large Language Models (LLM). They can be used on any language-based task, thanks to their state-of-the-art reasoning, knowledge, and coding capabilities. Several Mistral Large model variants are available:
- Mistral Large (2402), also abbreviated as Mistral Large
- Mistral Large (2407)
- Mistral Large (2411)
Attributes of Mistral Large (2402), also abbreviated as Mistral Large, include:
- Specialized in RAG. Crucial information isn't lost in the middle of long context windows (up to 32-K tokens).
- Strong in coding. Code generation, review, and comments. Supports all mainstream coding languages.
- Multi-lingual by design. Best-in-class performance in French, German, Spanish, Italian, and English. Dozens of other languages are supported.
- Responsible AI compliant. Efficient guardrails baked in the model and extra safety layer with the safe_mode option.
Attributes of Mistral Large (2407) include:
- Multi-lingual by design. Supports dozens of languages, including English, French, German, Spanish, and Italian.
- Proficient in coding. Trained on more than 80 coding languages, including Python, Java, C, C++, JavaScript, and Bash. Also trained on more specific languages such as Swift and Fortran.
- Agent-centric. Possesses agentic capabilities with native function calling and JSON outputting.
- Advanced in reasoning. Demonstrates state-of-the-art mathematical and reasoning capabilities.
Attributes of Mistral Large (2411) include the same as Mistral Large (2407) with the following additional attributes:
- System prompts are injected before each conversation.
- Better performance on long content.
- Improved function calling capabilities.
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
Deploy Mistral family of models as a serverless API
Certain models in the model catalog can be deployed as a serverless API with pay-as-you-go billing. This kind of deployment provides a way to consume models as an API without hosting them on your subscription, while keeping the enterprise security and compliance that organizations need. This deployment option doesn't require quota from your subscription.
Mistral Large, Mistral Large (2407), Mistral Large (2411), Mistral Small, and Mistral Nemo can be deployed as a serverless API with pay-as-you-go billing and are offered by Mistral AI through the Microsoft Azure Marketplace. Mistral AI can change or update the terms of use and pricing of these models.
Prerequisites
An Azure subscription with a valid payment method. Free or trial Azure subscriptions won't work. If you don't have an Azure subscription, create a paid Azure account to begin.
An Azure Machine Learning workspace. If you don't have a workspace, use the steps in the Quickstart: Create workspace resources article to create one. The serverless API model deployment offering for eligible models in the Mistral family is only available in workspaces created in these regions:
- East US
- East US 2
- North Central US
- South Central US
- West US
- West US 3
- Sweden Central
For a list of regions that are available for each of the models supporting serverless API endpoint deployments, see Region availability for models in serverless API endpoints
Azure role-based access controls (Azure RBAC) are used to grant access to operations in Azure Machine Learning. To perform the steps in this article, your user account must be assigned the Azure AI Developer role on the resource group. For more information on permissions, see Manage access to an Azure Machine Learning workspace.
Create a new deployment
The following steps demonstrate the deployment of Mistral Large, but you can use the same steps to deploy Mistral Nemo or any of the premium Mistral models by replacing the model name.
To create a deployment:
Select the workspace in which you want to deploy your model. To use the serverless API model deployment offering, your workspace must belong to one of the regions listed in the prerequisites.
Choose the model you want to deploy, for example the Mistral Large model, from the model catalog.
Alternatively, you can initiate deployment by going to your workspace and selecting Endpoints > Serverless endpoints > Create.
On the model's overview page in the model catalog, select Deploy to open a serverless API deployment window for the model.
Select the checkbox to acknowledge the Microsoft purchase policy.
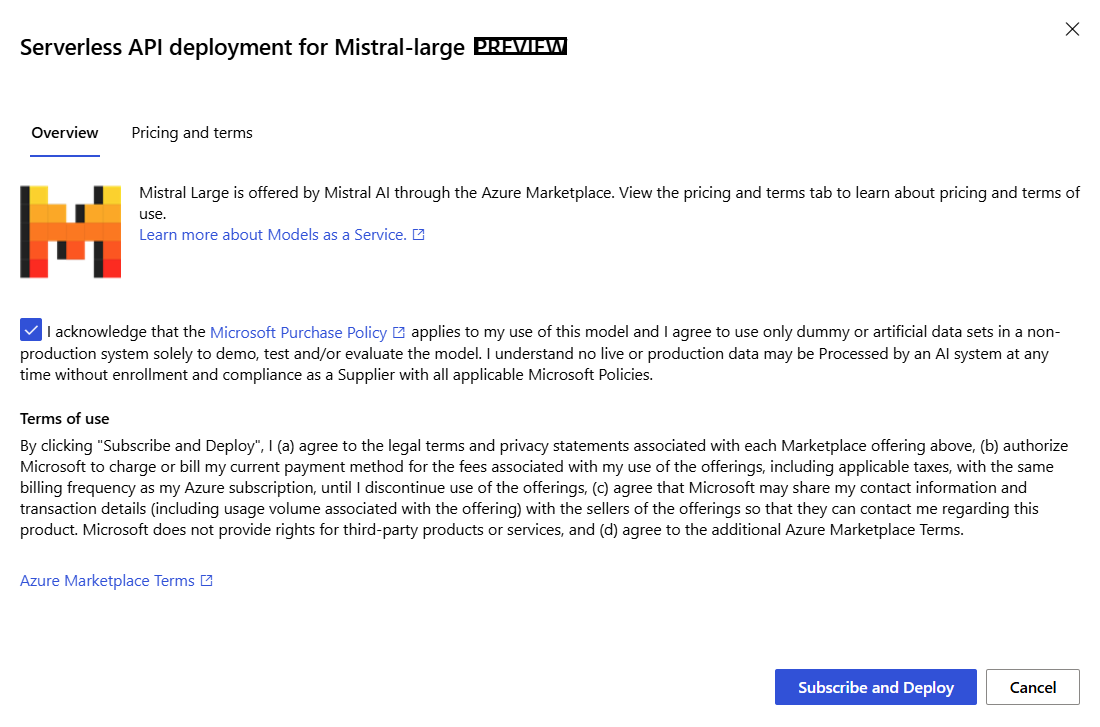
In the deployment wizard, select the link to Azure Marketplace Terms to learn more about the terms of use.
You can also select the Pricing and terms tab to learn about pricing for the selected model.
If this is your first time deploying the model in the workspace, you have to subscribe your workspace for the particular offering (for example, Mistral Large). This step requires that your account has the Azure AI Developer role permissions on the Resource Group, as listed in the prerequisites. Each workspace has its own subscription to the particular Azure Marketplace offering, which allows you to control and monitor spending. Select Subscribe and Deploy. Currently you can have only one deployment for each model within a workspace.
Once you subscribe the workspace for the particular Azure Marketplace offering, subsequent deployments of the same offering in the same workspace don't require subscribing again. If this scenario applies to you, you'll see a Continue to deploy option to select.

Give the deployment a name. This name becomes part of the deployment API URL. This URL must be unique in each Azure region.

Select Deploy. Wait until the deployment is finished and you're redirected to the serverless endpoints page.
Select the endpoint to open its Details page.
Select the Test tab to start interacting with the model.
You can always find the endpoint's details, URL, and access keys by navigating to Workspace > Endpoints > Serverless endpoints.



To learn about billing for Mistral models deployed as a serverless API with pay-as-you-go token-based billing, see Cost and quota considerations for Mistral family of models deployed as a service.
Consume the Mistral family of models as a service
You can consume Mistral models by using the chat API.
- In the workspace, select Endpoints > Serverless endpoints.
- Find and select the deployment you created.
- Copy the Target URL and the Key token values.
- Make an API request using to either the Azure AI Model Inference API on the route
/chat/completionsand the native Mistral Chat API on/v1/chat/completions.
For more information on using the APIs, see the reference section.
Reference for Mistral family of models deployed as a service
Mistral models accept both the Azure AI Model Inference API on the route /chat/completions and the native Mistral Chat API on /v1/chat/completions.
Azure AI Model Inference API
The Azure AI Model Inference API schema can be found in the reference for Chat Completions article and an OpenAPI specification can be obtained from the endpoint itself.
Mistral Chat API
Use the method POST to send the request to the /v1/chat/completions route:
Request
POST /v1/chat/completions HTTP/1.1
Host: <DEPLOYMENT_URI>
Authorization: Bearer <TOKEN>
Content-type: application/json
Request schema
Payload is a JSON formatted string containing the following parameters:
| Key | Type | Default | Description |
|---|---|---|---|
messages |
string |
No default. This value must be specified. | The message or history of messages to use to prompt the model. |
stream |
boolean |
False |
Streaming allows the generated tokens to be sent as data-only server-sent events whenever they become available. |
max_tokens |
integer |
8192 |
The maximum number of tokens to generate in the completion. The token count of your prompt plus max_tokens can't exceed the model's context length. |
top_p |
float |
1 |
An alternative to sampling with temperature, called nucleus sampling, where the model considers the results of the tokens with top_p probability mass. So 0.1 means only the tokens comprising the top 10% probability mass are considered. We generally recommend altering top_p or temperature, but not both. |
temperature |
float |
1 |
The sampling temperature to use, between 0 and 2. Higher values mean the model samples more broadly the distribution of tokens. Zero means greedy sampling. We recommend altering this parameter or top_p, but not both. |
ignore_eos |
boolean |
False |
Whether to ignore the EOS token and continue generating tokens after the EOS token is generated. |
safe_prompt |
boolean |
False |
Whether to inject a safety prompt before all conversations. |
The messages object has the following fields:
| Key | Type | Value |
|---|---|---|
content |
string |
The contents of the message. Content is required for all messages. |
role |
string |
The role of the message's author. One of system, user, or assistant. |
Request example
Body
{
"messages":
[
{
"role": "system",
"content": "You are a helpful assistant that translates English to Italian."
},
{
"role": "user",
"content": "Translate the following sentence from English to Italian: I love programming."
}
],
"temperature": 0.8,
"max_tokens": 512,
}
Response schema
The response payload is a dictionary with the following fields.
| Key | Type | Description |
|---|---|---|
id |
string |
A unique identifier for the completion. |
choices |
array |
The list of completion choices the model generated for the input messages. |
created |
integer |
The Unix timestamp (in seconds) of when the completion was created. |
model |
string |
The model_id used for completion. |
object |
string |
The object type, which is always chat.completion. |
usage |
object |
Usage statistics for the completion request. |
Tip
In the streaming mode, for each chunk of response, finish_reason is always null, except from the last one which is terminated by a payload [DONE]. In each choices object, the key for messages is changed by delta.
The choices object is a dictionary with the following fields.
| Key | Type | Description |
|---|---|---|
index |
integer |
Choice index. When best_of > 1, the index in this array might not be in order and might not be 0 to n-1. |
messages or delta |
string |
Chat completion result in messages object. When streaming mode is used, delta key is used. |
finish_reason |
string |
The reason the model stopped generating tokens: - stop: model hit a natural stop point or a provided stop sequence. - length: if max number of tokens have been reached. - content_filter: When RAI moderates and CMP forces moderation - content_filter_error: an error during moderation and wasn't able to make decision on the response - null: API response still in progress or incomplete. |
logprobs |
object |
The log probabilities of the generated tokens in the output text. |
The usage object is a dictionary with the following fields.
| Key | Type | Value |
|---|---|---|
prompt_tokens |
integer |
Number of tokens in the prompt. |
completion_tokens |
integer |
Number of tokens generated in the completion. |
total_tokens |
integer |
Total tokens. |
The logprobs object is a dictionary with the following fields:
| Key | Type | Value |
|---|---|---|
text_offsets |
array of integers |
The position or index of each token in the completion output. |
token_logprobs |
array of float |
Selected logprobs from dictionary in top_logprobs array. |
tokens |
array of string |
Selected tokens. |
top_logprobs |
array of dictionary |
Array of dictionary. In each dictionary, the key is the token and the value is the prob. |
Response example
The following JSON is an example response:
{
"id": "12345678-1234-1234-1234-abcdefghijkl",
"object": "chat.completion",
"created": 2012359,
"model": "",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Sure, I\'d be happy to help! The translation of ""I love programming"" from English to Italian is:\n\n""Amo la programmazione.""\n\nHere\'s a breakdown of the translation:\n\n* ""I love"" in English becomes ""Amo"" in Italian.\n* ""programming"" in English becomes ""la programmazione"" in Italian.\n\nI hope that helps! Let me know if you have any other sentences you\'d like me to translate."
}
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 40,
"completion_tokens": 30
}
}
More inference examples
| Sample Type | Sample Notebook |
|---|---|
| CLI using CURL and Python web requests | webrequests.ipynb |
| OpenAI SDK (experimental) | openaisdk.ipynb |
| LangChain | langchain.ipynb |
| Mistral AI | mistralai.ipynb |
| LiteLLM | litellm.ipynb |
Cost and quotas
Cost and quota considerations for Mistral family of models deployed as a service
Mistral models deployed as a service are offered by Mistral AI through Azure Marketplace and integrated with Azure Machine Learning studio for use. You can find Azure Marketplace pricing when deploying the models.
Each time a workspace subscribes to a given model offering from Azure Marketplace, a new resource is created to track the costs associated with its consumption. The same resource is used to track costs associated with inference; however, multiple meters are available to track each scenario independently.
For more information on how to track costs, see Monitor costs for models offered through the Azure Marketplace.
Quota is managed per deployment. Each deployment has a rate limit of 200,000 tokens per minute and 1,000 API requests per minute. However, we currently limit one deployment per model per workspace. Contact Microsoft Azure Support if the current rate limits aren't sufficient for your scenarios.
Content filtering
Models deployed as a service with pay-as-you-go are protected by Azure AI content safety. With Azure AI content safety enabled, both the prompt and completion pass through an ensemble of classification models aimed at detecting and preventing the output of harmful content. The content filtering (preview) system detects and takes action on specific categories of potentially harmful content in both input prompts and output completions. Learn more about Azure AI Content Safety.