Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Denne artikel er beregnet til alle, der planlægger at udrulle en datagateway i det lokale miljø i et forretningskritisk scenarie. En datagateway i det lokale miljø er forretningskritisk, hvis den er vigtig for din virksomheds normale drift og håndterer forretningskritiske data.
Hvis forretningskritiske gateways ikke administreres korrekt, kan du opleve mislykkede forespørgsler eller langsom ydeevne. Når du planlægger, skalerer og vedligeholder din forretningskritiske gatewayløsning korrekt, kan sandsynligheden for et problem, der påvirker virksomheden, minimeres.
Terminologi
Følgende vigtige ord bruges i hele denne artikel:
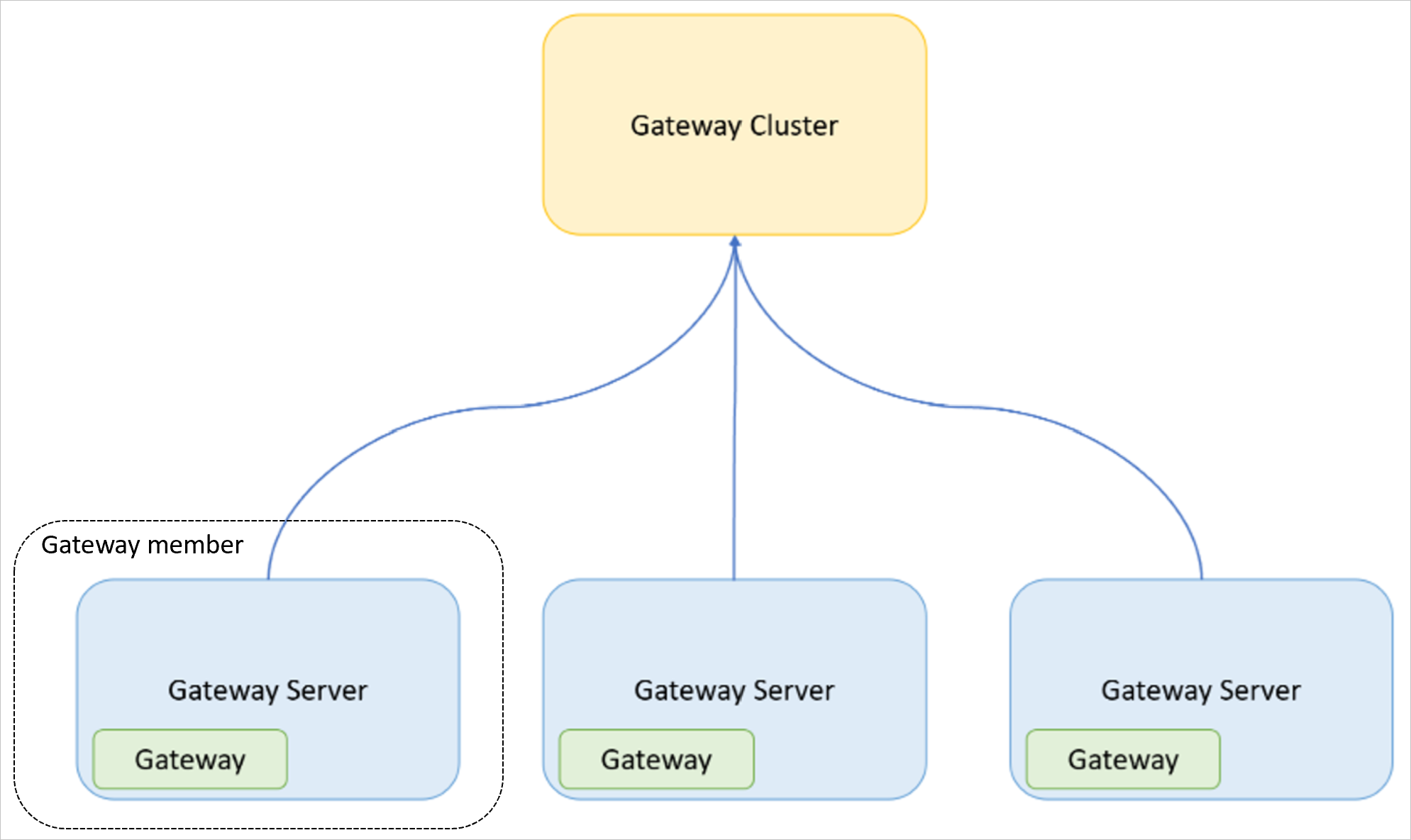
- Gateway: Det lokale datagatewayprogram, der er installeret på en computer.
- Gatewayserver: En Windows-computer (virtuel maskine eller fysisk computer/server), hvor programmet til datagatewayen i det lokale miljø er installeret.
- Gatewayklynge: Et sæt gateways, der arbejder sammen (og kan være belastningsafbalancerede).
- Gatewaymedlem: En gateway, der er en del af en gatewayklynge.
På følgende billede vises relationen mellem de begreber, der er defineret ovenfor.
Anbefalinger til forretningskritiske gateways
For forretningskritiske gateways skal gateways udrulles og administreres korrekt for at sikre høj tilgængelighed, god ydeevne og skalerbarhed, der kan vedligeholdes. Forkert installation af gateways kan resultere i dårlig ydeevne, mislykkede forespørgsler og problemer med at diagnosticere potentielle problemer. Det kan også forhindre din mulighed for at skalere gateways op og ud i takt med, at forbruget vokser.
Følg anbefalingerne i de næste afsnit for at sikre optimal skalerbarhed, ydeevne og gennemløb.
Kend alle genoprettelsesnøgler til din gateway
Sørg for, at alle gatewaygendannelsesnøgler er kendt og opbevaret et sikkert sted. Uden en genoprettelsesnøgle kan gateways ikke gendannes eller nedgraderes. Denne begrænsning er tilsigtet. Hvis du mister dine genoprettelsesnøgler, er den eneste mulighed at oprette nye gateways og genoprette datakilderne. Du kan heller ikke føje nye gateways til klyngen uden genoprettelsesnøglen, hvilket vil begrænse den fremtidige skalerbarhed.
Gem dine genoprettelsesnøgler et sikkert sted, på samme måde som du gemmer administrative legitimationsoplysninger, f.eks. et adgangskodesikkert sted, som kun godkendte administratorer kan få adgang til.
Hvis du i øjeblikket ikke kender alle dine genoprettelsesnøgler til gatewayen, er dette en betydelig forretningsrisiko. Opret straks nye gatewayklynger, og begynd at overføre arbejdsbelastninger til de nye gatewayklynger.
Udviklingsarbejdsbelastninger og forretningskritiske arbejdsbelastninger
Adskil udviklingsarbejdsbelastninger fra forretningskritiske arbejdsbelastninger ved at konfigurere en eller flere udviklingsgatewayklynger og en eller flere produktionsgatewayklynger.
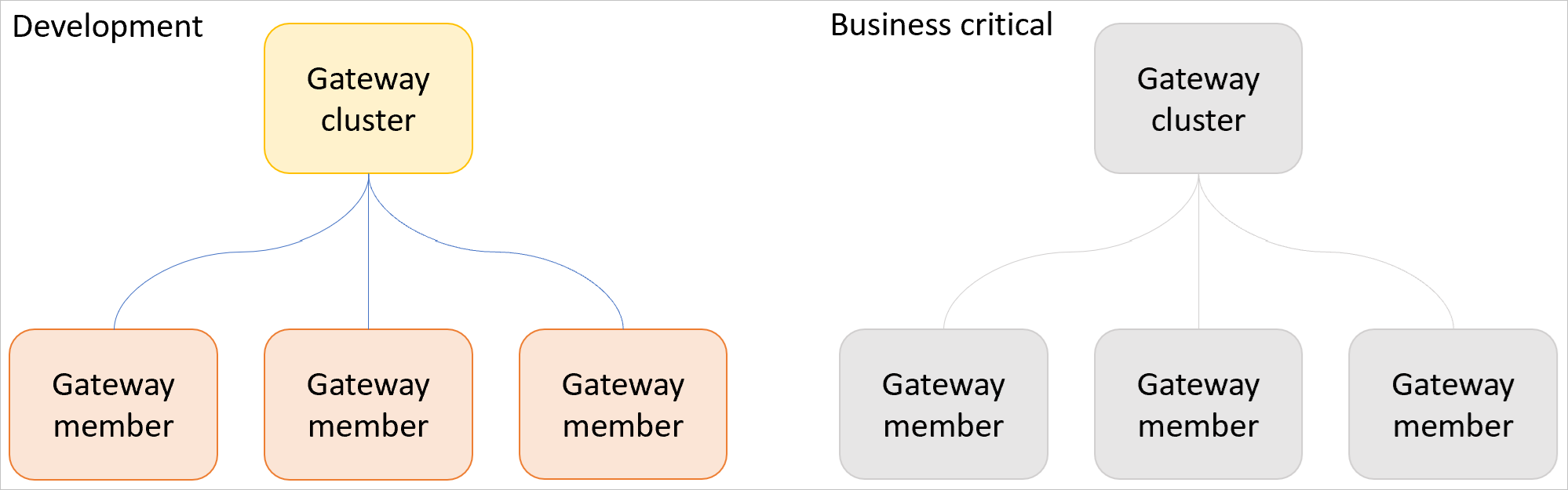
Brug en klynge til udviklingsgatewayen til at teste nye semantiske modeller, rapporter, forespørgsler osv. Når en ny arbejdsbelastning er blevet bekræftet, kan du overføre den til en forretningskritisk gatewayklynge. Denne proces forhindrer nye, ikke-afprøvede eller eksperimentelle arbejdsbelastninger i at have indvirkning på ydeevnen på produktionsarbejdsbelastninger.
Brug også dine udviklingsgatewayklynger til at teste nye gatewayopdateringer, før du anvender opdateringer til dine forretningskritiske gatewayklynger. Nye gatewayopdateringer skal installeres i mindst 24 timer i udviklingsgatewayklynge, før de bruges på forretningskritiske gatewayklynger.
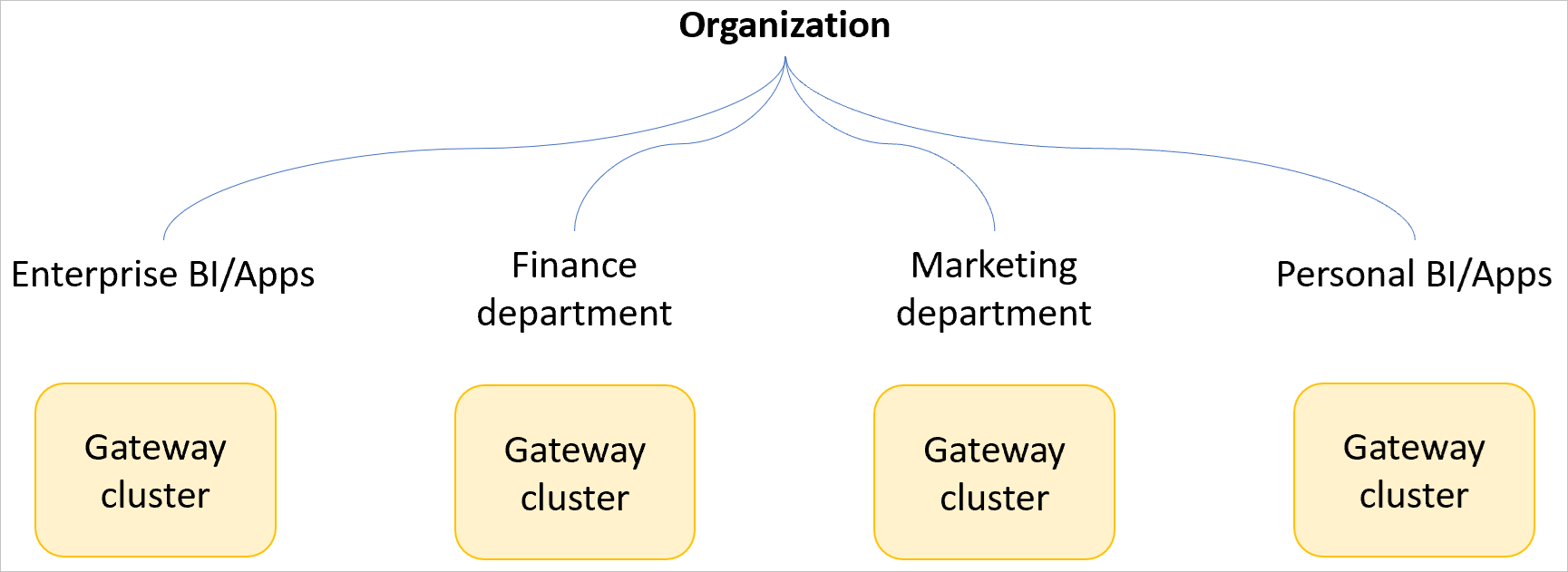
Brug flere gatewayklynger
Hvis du opretter en gatewayklynge for et stort antal brugere i din organisation, skal du oprette flere gatewayklynger baseret på forretningsenheder eller mindre for at begrænse eventuelle potentielle indvirkninger på ydeevnen for et mindre undersæt af brugere.
Vi anbefaler ikke, at der bruges en enkelt forretningskritisk gatewayklynge til en hel virksomhed (medmindre virksomheden er lille). I et enkelt gatewayklyngescenarie kan én bruger tænkes at sende en forespørgsel, der medfører en betydelig indvirkning på ydeevnen for al trafik på tværs af gatewayen. Hvis gatewayen bruges på tværs af hele virksomheden, kan påvirkningen af ydeevnen påvirke hele virksomheden. Når en gatewayklynge bruges på tværs af en hel virksomhed, kan det også være sværere for dig at identificere, hvilken forespørgsel der kan forårsage problemer med ydeevnen, når du bruger funktionen til overvågning af gatewayens ydeevne .
Brug funktionerne til høj tilgængelighed og justering af belastning for gatewayen
Brug altid funktionerne med høj tilgængelighed og belastningsjustering for alle forretningskritiske gatewayklynger.
- Høj tilgængelighed: Eliminerer, at der er et enkelt fejlpunkt.
- Justering af belastning: Distribuerer automatisk arbejdsbelastningen på tværs af alle gatewayservere i klyngen.
Konfigurer mindst to gateways pr. gatewayklynge, hvis en gateway af en eller anden grund går offline. Denne konfiguration sikrer, at en enkelt gatewayfejl ikke medfører, at hele gatewayklynge mislykkes. Derudover kan grænser for CPU, hukommelse og samtidighed aktiveres på gateways for bedre at fordele belastningen på tværs af gatewayklynge.
Planlæg og vedligehold gatewayklyngeskalerbarhed
Konfiguration af en gatewayklynge ved hjælp af vores anbefalede retningslinjer for hardware og software sikrer, at klyngen kører med god ydeevne. Gateways, der ikke skaleres korrekt, kan resultere i dårlig ydeevne. Der er mange faktorer, du skal overveje for at have en god ydeevne på din gatewayklynge.
Fastlæg hardwarespecifikationer for gatewayserveren
Specifikationer for gatewayserveren (CPU, hukommelse, disk osv.) er en vigtig faktor, da Power Query-transformationerne i de fleste tilfælde anvendes på dataene på gatewayserveren. En gatewayserver skal derfor have tilstrækkelige ressourcer, hukommelse og behandlingskraft til at håndtere alle datatransformationerne.
Når du har brug for at vælge en serverstørrelse, er der to vigtigste målepunkter: Hukommelse og CPU. Du skal bruge både rigelig hukommelse og CPU-kraft for at kunne behandle trinnene til transformation af Power Query-data på gatewayen. Det er vigtigt, at din gatewayserver er effektiv nok til at behandle den højeste arbejdsbelastning, du har. Hvis gatewayserveren ikke kan håndtere arbejdsbelastningen, mislykkes din direkte forespørgsel eller dataopdatering. Det er også vigtigt at forstå, hvor mange forespørgsler der udføres på samme tid.
Disse forskellige forespørgselsindstillinger har en anden effekt på gatewayserveren.
| Forespørgselstype | Grænsefaktor |
|---|---|
| Importér | Hukommelse |
| DirectQuery | CPU |
| LiveConnect | CPU |
Under en import skal hele datasættet forespørges og behandles, hvilket er en tung hukommelsesopgave. Denne import tager ofte også længere tid. DirectQueries og LiveConnections er ofte CPU-tunge. I de fleste tilfælde udføres direkte forespørgsler mange gange for kun at behandle en lille del af dataene. Da kun en lille del af dataene behandles, er disse direkte forespørgsler normalt ikke en tung opgave i hukommelsen. Da forespørgslerne udføres mange gange efter behov, kan dette dog være CPU-krævende.
Afhængigt af din arbejdsbelastning kan du overveje at optimere din gatewayserver til hukommelse eller CPU.
Hvornår skaleres en gatewayklynge?
Skalering er et vigtigt aspekt af en forretningskritisk gatewayklynge. I takt med at dit forbrug med gatewayklynge vokser, skal gatewayklyngen skal skaleres op og/eller skaleres ud for at sikre en god ydeevne. Vi anbefaler, at du begynder at skalere en gatewayklynge, hvis du tidligere har skaleret gateways i klyngen.
Skalering og distribution af trafikbelastning på tværs af individuelle noder i en klynge er en kompleks proces, der varierer afhængigt af hvert enkelt scenarie. Selvom der ikke er nogen endelig model til at sikre, at al gatewaytrafik er forudsigeligt serviceret, indikerer de grænser, der er angivet nedenfor, et skaleringsbehov. Generelt anbefaler vi, at du skalerer ud (føje noder til klyngen) til at skalere op (øge CPU, RAM eller diskplads på individuelle noder). Udskalering har en tendens til at være mere effektiv generelt i systemets evne som helhed til at håndtere ekstra trafik. Udskalering har også en positiv indvirkning på den samlede båndbredde, klyngen kan behandle, hvorimod opskalering generelt ikke gør det. Når en eller flere gatewaynoder viser tegn på at nå følgende tærskler, bør det overvejes kraftigt at skalere klyngen ud.
CPU: CPU'en er over 80% i længere tid, men lejlighedsvise korte stigninger (under 5 minutter) maks. CPU'er er ikke unormale.
RAM: Den tilgængelige hukommelse falder regelmæssigt til under 20%.
Disk: Ledig diskplads falder ofte til under 5 GB. Dette fald kan også indikere, at det er nødvendigt at konfigurere cachelagrings- eller spoolingmapper mere strategisk.
Samtidighed: Kørsel af mere end 40 forespørgsler samtidigt på en enkelt node.
Da opdateringer og forespørgsler, der distribueres på tværs af gatewaynoder, kan have meget forskellige profiler, anbefaler vi også, at der foretages ekstra kontrol af langvarige eller hukommelsestunge job. Forespørgselsoptimering i sådanne tilfælde kan have stor indvirkning på ydeevnen og skalerbarheden, ikke kun for de enkelte rapporter og opdateringer, men for systemet som helhed. Vi anbefaler, at du isolerer de pågældende opdateringer til en enkelt dedikeret gatewayklynge for at evaluere ydeevneegenskaber og udføre optimering ved hjælp af diagnosticering af forespørgselsplan, foldningsindikatorer og alle andre publicerede ydeevneanbefalinger. Denne isolation minimerer mængden af data, der hentes, og mængden af påkrævet efterbehandling. Denne isolation kan også bruges som en langsigtet strategi til at adskille langvarige ETL-job til en dedikeret gatewayklynge for at reducere striden med andre typiske opdateringer på tværs af organisationen.
Opskalering af en gatewayklynge
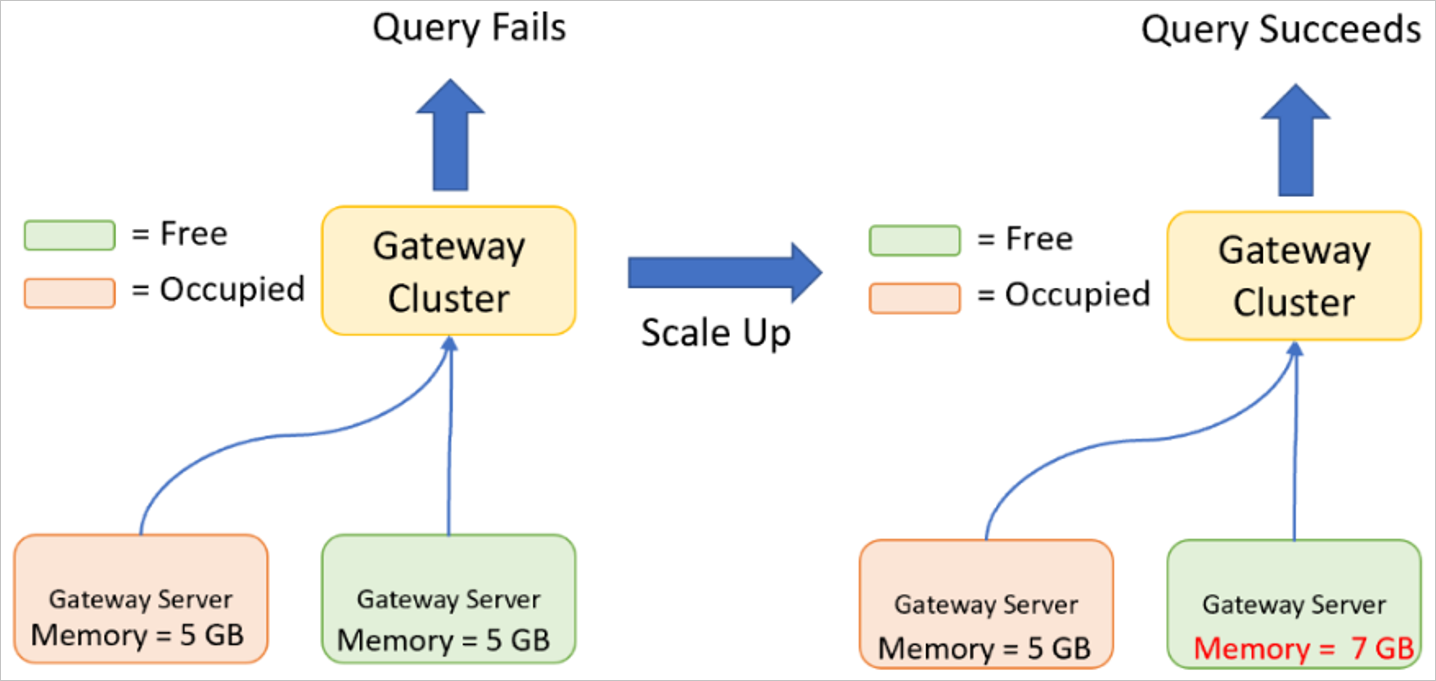
Opskalering er, når du øger specifikationerne (CPU, hukommelse, disk osv.) for dine gatewayservere.
Opskalering kan være påkrævet, hvis den maksimale CPU eller hukommelse nås, når gatewayen udfører en eller flere forespørgsler. En forespørgsel kan kun udføres på én gatewayserver, og derfor skal gatewayserveren have tilstrækkelige ressourcer til at behandle hele forespørgslen sammen med de resulterende data.
Udskalering af en gatewayklynge
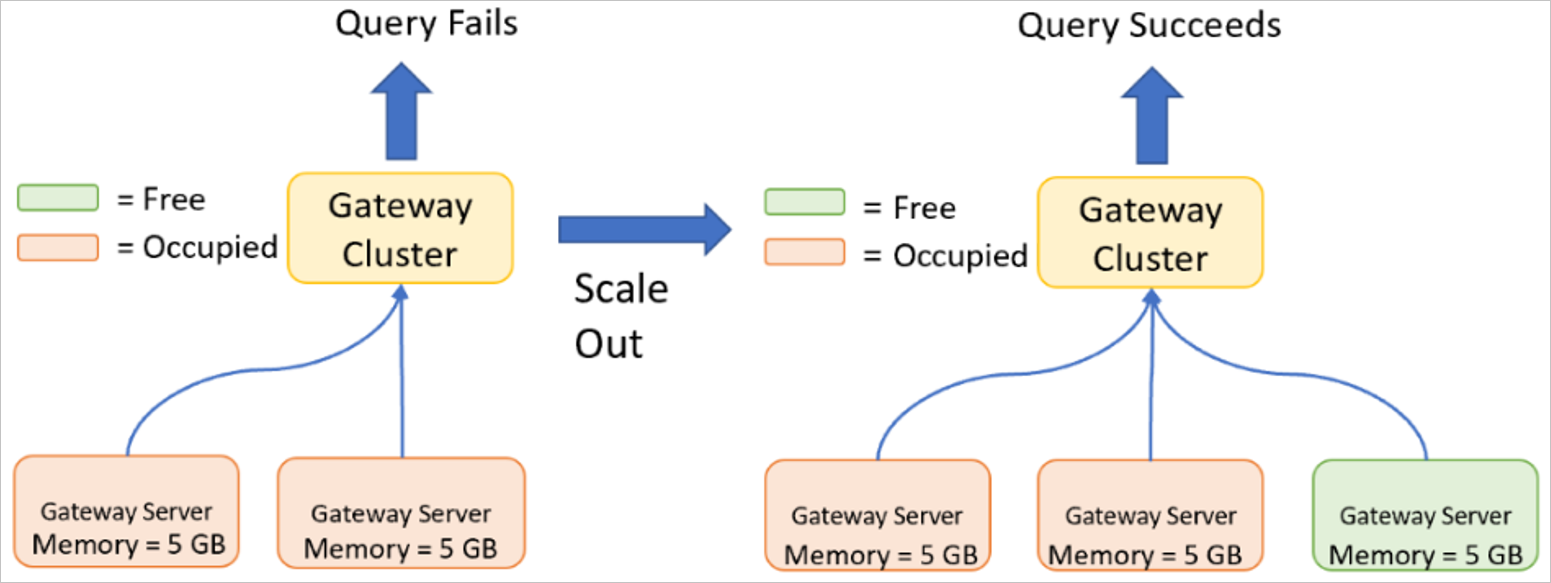
Udskalering er påkrævet, hvis gatewayserveren allerede har høje specifikationer (det vil sige, at gatewayserveren allerede har opskaleret), eller du har nået grænserne for, hvad en enkelt gatewayserver kan administrere på grund af det antal samtidige forespørgsler, der udføres. En bred baseret belastningsforøgelse på tværs af hele gatewaymedlemssættet er en god indikation af, at skalering af en klynge ved at tilføje noder er den korrekte fremgangsmåde. Hvornår en gatewayklynge skal skaleres , indeholder specifikke tærskler, der angiver, hvornår det er tid til at skalere. Du kan finde flere oplysninger om udskalering ved at gå til Brug gatewayens funktioner med høj tilgængelighed og justering af belastning.
Skalering ved at oprette nye gatewayklynger
Hvis ressourceforbruget for din gatewayklynge er højt, eller et usædvanligt stort antal brugere er afhængige af en gatewayklynge, kan der oprettes en ny gatewayklynge. Et undersæt af arbejdsbelastningen kan derefter overføres til den nye gatewayklynge. Når et stort antal brugere er afhængige af en enkelt gatewayklynge, øges sandsynligheden for, at en bruger kan sende en forespørgsel, der medfører en betydelig indvirkning på ydeevnen på tværs af hele gatewayklynge.
Et usædvanligt stort antal brugere, der er afhængige af en enkelt gatewayklynge, er en indikator for, at der skal oprettes en ny gatewayklynge.
Overvågning og fejlfinding af gatewayydeevne
Det er vigtigt at overvåge den overordnede ydeevne af forretningskritiske gateways ved hjælp af funktionen til overvågning af gatewayens ydeevne . Du kan også bruge denne funktion til at foretage fejlfinding af problemer med ydeevnen, identificere flaskehalse og identificere forespørgsler, der påvirker den overordnede gatewayydeevne. Denne funktion er også et vigtigt værktøj til at hjælpe dig med at bestemme, hvornår du skal skalere en gatewayklynge.
Hvis du identificerer, at en forespørgsel har en stor indvirkning på gatewayen, hvilket resulterer i dårlig overordnet ydeevne, kan du muligvis omskrive forespørgslen for at være mere effektiv og minimere påvirkningen af ydeevnen.
Hvis Microsoft identificerer dårlig ydeevne, der skyldes en gateway eller en gatewayrelateret komponent, f.eks. en Power BI Premium-kapacitet, der er overbelastet, skal den overbelastede komponent afhjælpes ved at skalere eller reducere belastningen. Microsoft undersøger ikke dårlig ydeevne, når en gateway eller en gatewayrelateret komponent overbelastes.