Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
De samlede data i Dynamics 365 Customer Insights – Data er en kilde til oprettelse af modeller til maskinel indlæring, der kan generere yderligere forretningsindsigt. Customer Insights – Data kan integreres med Azure Machine Learning, så du kan bruge dine egne brugerdefinerede modeller.
Forudsætninger
- Adgang til Kundeindsigt – Data
- Active Azure Enterprise-abonnement
- Samlede kundeprofiler
- Tabeleksport til Azure Blob Storage konfigureret
Konfigurer Azure Machine Learning-arbejdsområde
Se Opret et Azure Machine Learning-arbejdsområde for at få forskellige muligheder for at oprette arbejdsområdet. Du får den bedste ydeevne ved at oprette arbejdsområdet i et Azure-område, der geografisk er tættest på dit Customer Insights-miljø.
Få adgang til dit arbejdsområde via Azure Machine Learning Studio. Der er flere måder at interagere med dit arbejdsområde på.
Arbejd med Azure Machine Learning-designer
Azure Machine Learning Designer indeholder et visuelt lærred, hvor du kan trække og slippe datasæt og moduler. En batchpipeline, der er oprettet fra designeren, kan integreres i Customer Insights – data, hvis de er konfigureret i overensstemmelse hermed.
Arbejde med Azure Machine Learning SDK
Datateknikere og AI-udviklere bruger Azure Machine Learning SDK til at bygge arbejdsprocesser til maskinel indlæring. Modeller, der oplæres ved hjælp af SDK'et, kan i øjeblikket ikke integreres direkte. En batchinferenspipeline, der bruger denne model, er påkrævet til integration med Customer Insights – Data.
Krav til batchpipeline, der skal integreres med Customer Insights – Data
Konfiguration af datasæt
Opret datasæt for at bruge tabeldata fra Customer Insights til din batchinferenspipeline. Registrer disse datasæt i arbejdsområdet. I øjeblikket understøtter vi kun tabeldatasæt i .csv format. Parameteriser de datasæt, der svarer til tabeldata, som en pipelineparameter.
Parametre for datasæt i Designer
Åbn Vælg kolonner i Datasæt i designeren, og vælg Angiv som pipelineparameter , hvor du angiver et navn til parameteren.
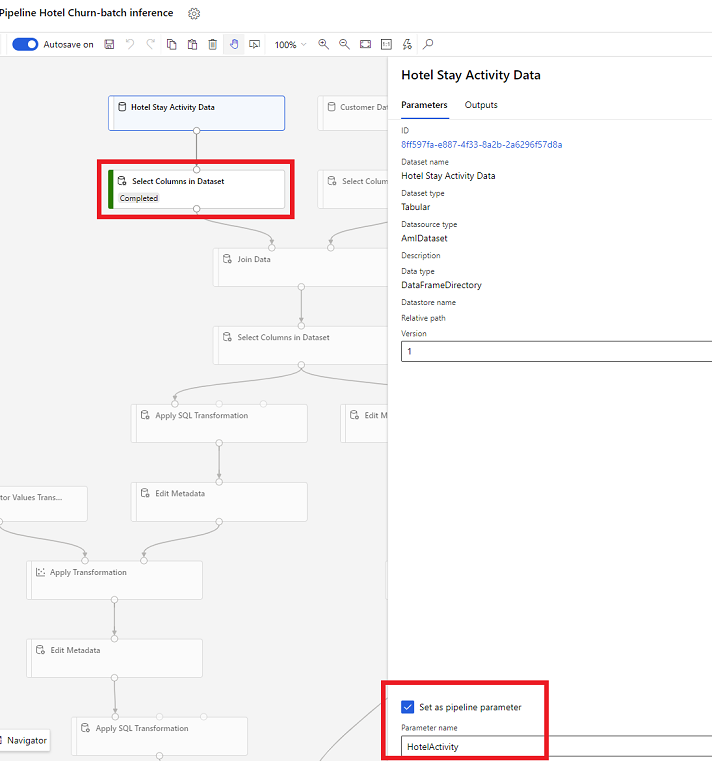
Parameter for datasæt i SDK (Python)
HotelStayActivity_dataset = Dataset.get_by_name(ws, name='Hotel Stay Activity Data') HotelStayActivity_pipeline_param = PipelineParameter(name="HotelStayActivity_pipeline_param", default_value=HotelStayActivity_dataset) HotelStayActivity_ds_consumption = DatasetConsumptionConfig("HotelStayActivity_dataset", HotelStayActivity_pipeline_param)
Batchinferenspipeline
I designeren skal du bruge en træningspipeline til at oprette eller opdatere en inferenspipeline. I øjeblikket understøttes kun batchinferenspipelines.
Publicer pipelinen til et slutpunkt ved hjælp af SDK'et. Customer Insights – Data integreres i øjeblikket med standardpipelinen i et batchpipelineslutpunkt i arbejdsområdet Machine Learning.
published_pipeline = pipeline.publish(name="ChurnInferencePipeline", description="Published Churn Inference pipeline") pipeline_endpoint = PipelineEndpoint.get(workspace=ws, name="ChurnPipelineEndpoint") pipeline_endpoint.add_default(pipeline=published_pipeline)
Importér pipelinedata
Designeren leverer modulet Eksportér data , der gør det muligt at eksportere outputtet fra en pipeline til Azure Storage. I øjeblikket skal modulet bruge datalagertypen Azure Blob Storage og parameterisere datalageret og den relative sti. Systemet tilsidesætter begge disse parametre under udførelse af pipelinen med et datalager og en sti, der er tilgængelig for programmet.
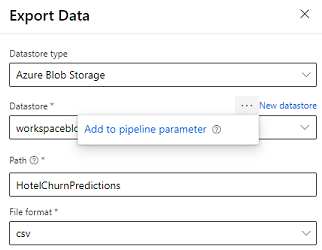
Når du skriver outputtet med en meddelelse ved hjælp af kode, skal du uploade outputtet til en sti i et registreret datalager i arbejdsområdet. Hvis stien og datalageret er parameteriseret i pipelinen, kan Kundeindsigt læse og importere outputtet af resultatet. I øjeblikket understøttes et enkelt tabeloutput i csv-format. Stien skal indeholde mappen og filnavnet.
# In Pipeline setup script OutputPathParameter = PipelineParameter(name="output_path", default_value="HotelChurnOutput/HotelChurnOutput.csv") OutputDatastoreParameter = PipelineParameter(name="output_datastore", default_value="workspaceblobstore") ... # In pipeline execution script run = Run.get_context() ws = run.experiment.workspace datastore = Datastore.get(ws, output_datastore) # output_datastore is parameterized directory_name = os.path.dirname(output_path) # output_path is parameterized. # Datastore.upload() or Dataset.File.upload_directory() are supported methods to uplaod the data # datastore.upload(src_dir=<<working directory>>, target_path=directory_name, overwrite=False, show_progress=True) output_dataset = Dataset.File.upload_directory(src_dir=<<working directory>>, target = (datastore, directory_name)) # Remove trailing "/" from directory_name