Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅ Fabric Data Engineering og Data Science
Når du opretter Microsoft Fabric fra Azure-portalen, bliver det automatisk tilføjet til Fabric-lejeren, der er tilknyttet det abonnement, der bruges til at oprette kapaciteten. Med den forenklede opsætning i Microsoft Fabric er der ikke behov for at knytte kapaciteten til Fabric-tenanten. Fordi den nyoprettede kapacitet vises i ruden Administratorindstillinger. Denne konfiguration giver administratorer en hurtigere oplevelse, så de kan begynde at konfigurere kapaciteten for deres virksomhedsanalyseteams.
Hvis du vil foretage ændringer af indstillingerne for Dataudvikler/Videnskab i en kapacitet, skal du have administratorrollen for den pågældende kapacitet. Hvis du vil vide mere om de roller, du kan tildele til brugere i en kapacitet, skal du se Roller i kapaciteter.
Brug følgende trin til at administrere Data Engineering/Science-indstillingerne for Microsoft Fabric-kapacitet:
Vælg indstillingen Indstillinger for at åbne indstillingsruden for din Fabric-konto. Vælg Administrationsportal under sektionen Styring og indsigt.
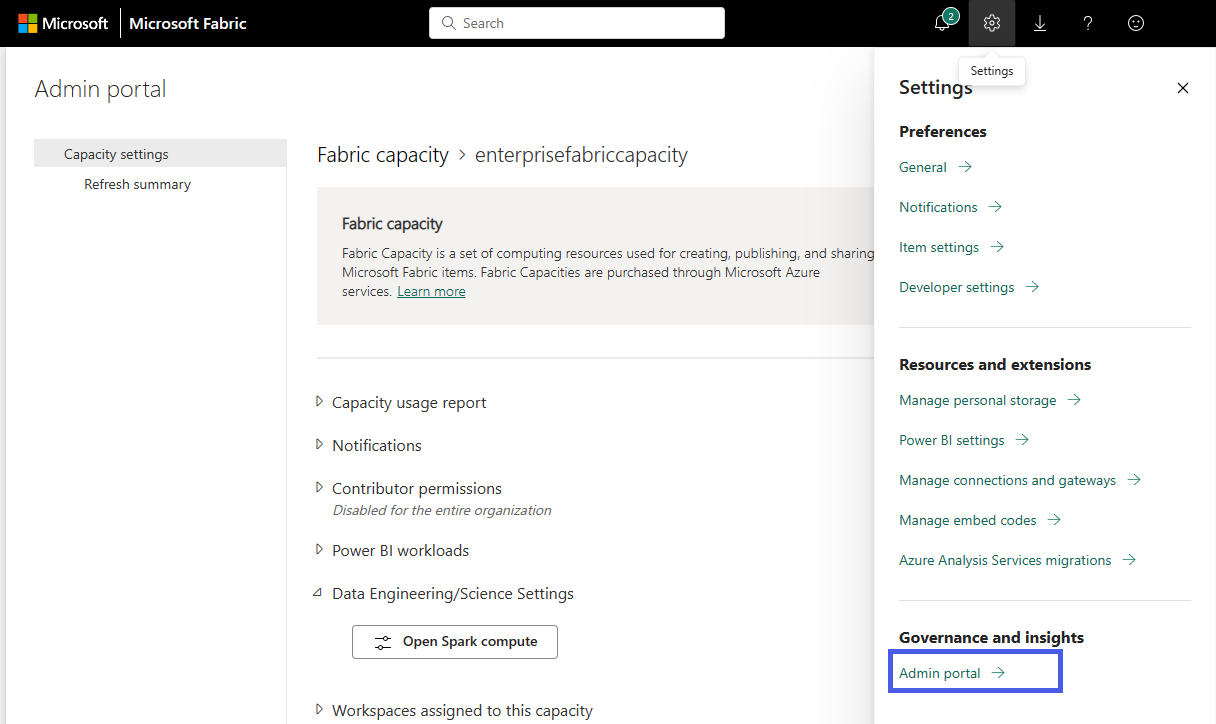
Vælg indstillingen Kapacitetsindstillinger for at udvide menuen, og vælg fanen Strukturkapacitet . Her kan du se de kapaciteter, du har oprettet i din lejer. Vælg den kapacitet, du vil konfigurere.
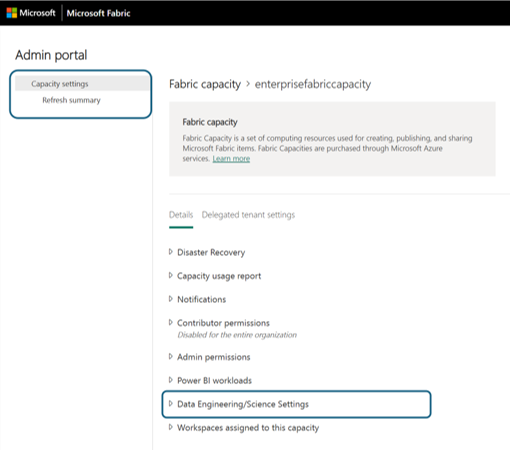
Du navigeres til detaljeruden for kapaciteten, hvor du kan få vist forbruget og andre administratorkontrolelementer for din kapacitet. Gå til afsnittet Dataudvikler/Videnskabsindstillinger, og vælg Åbn Spark Compute. Konfigurer følgende parametre:


Bemærk
Der skal være knyttet mindst ét arbejdsområde til Fabric Capacity for at udforske Data Engineering/Science Settings fra Fabric Capacity Admin Portal.
Administratorkontrolelement: Deaktiver brug af startpulje
Kapacitetsadministratorer kan nu vælge at deaktivere brug af startpulje på tværs af arbejdsområder, der er knyttet til kapaciteten. Når den er deaktiveret, kan brugere og arbejdsområdeadministratorer ikke længere se startpuljen som en beregningsindstilling. I stedet skal de bruge brugerdefinerede puljer, der eksplicit er oprettet og administreret af kapacitetsadministratoren.
Denne funktion giver centraliseret styring af beregningsbrug, hvilket sikrer strammere kontrol over beregningsstørrelse, omkostninger og planlægningsfunktion.
Tips
Denne indstilling er især nyttig i store organisationer, der ønsker at standardisere beregningsmønstre og undgå vilkårligt forbrug via standardstartpuljer.
Administratorkontrolelement: Bursting-knap på jobniveau
Microsoft Fabric understøtter 3× bursting for Spark VCores, hvilket tillader et enkelt job midlertidigt at bruge flere compute-kerner end basiskapaciteten tilbyder. Dette forbedrer jobydelsen under aktivitetsudbrud ved at tillade fuld kapacitetsudnyttelse.
Som kapacitetsadministrator kan du nu styre denne funktionsmåde ved hjælp af parameteren "Deaktiver bursting på jobniveau", der er tilgængelig på administrationsportalen:
Placering:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark ComputeAdfærd:
- Aktiveret (standard): Et enkelt Spark-job kan forbruge den fulde burst-grænse (op til 3× Spark VCores).
- Deaktiveret: Individuelle Spark-job er begrænset til basiskapacitetsallokeringen, hvilket bevarer samtidighed og undgår monopolisering.
Bemærk
Denne switch er kun tilgængelig, når du kører Spark-job på Fabric Capacity. Hvis indstillingen Autoskaler fakturering er aktiveret, deaktiveres denne parameter automatisk, fordi:
- Autoskalering af fakturering følger en ren betalt efter forbrug-model.
- Der er ikke noget udjævningsvindue , der tillader brugsudbrud og afbalancerer dem over 24 timer.
- Bursting er en funktion i reserveret kapacitet, ikke beregning efter behov af autoskalering.
Eksempler på brug
| Scenarie | Indstilling | Adfærd |
|---|---|---|
| Tung ETL-arbejdsbyrde | Bursting aktiveret (standard) | Job kan bruge hele burst-kapaciteten (f.eks. 384 Spark VCores i F64). |
| Interaktive notesbøger til flere brugere | Bursting deaktiveret | Jobforbruget er begrænset (f.eks. 128 Spark VCores i F64), hvilket forbedrer samtidigheden. |
| Autoskalering af fakturering er aktiveret | Bursting-kontrol er ikke tilgængelig | Alt Spark-forbrug faktureres efter behov. ingen sprængning fra basiskapaciteten. |
Tips
Brug denne parameter til at optimere for enten gennemløb eller samtidighed:
- Hold bursting aktiveret for store job og pipelines.
- Deaktiver det for interaktive eller delte miljøer med mange brugere.
Kapacitetspuljer til Data Engineering og Data Science i Microsoft Fabric
I afsnittet Puljeliste i Spark-indstillinger skal du klikke på Tilføj for at oprette en brugerdefineret pulje til din strukturkapacitet.
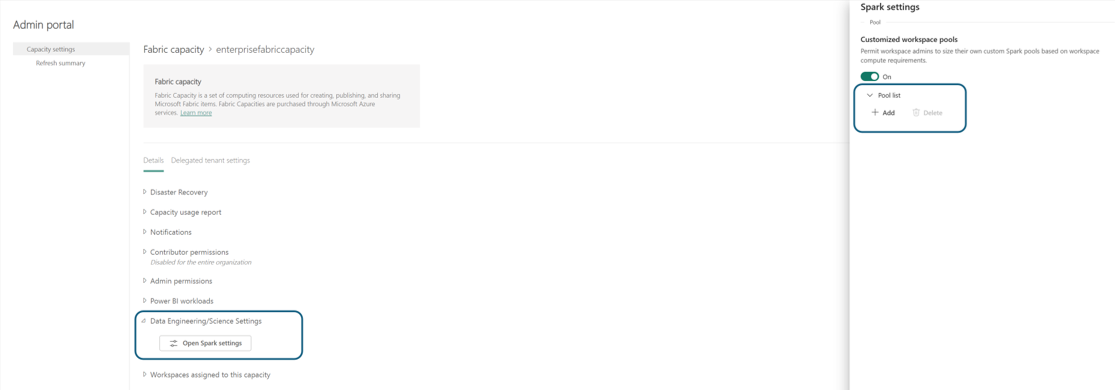
Du navigeres til siden til oprettelse af puljer, hvor du kan:
- Angiv navnet på puljen
- Vælg Nodefamilie og Nodestørrelse
- Indstil min. og maks. noder
- Aktiver/deaktiver autoskalering og dynamisk allokering af eksekutorer
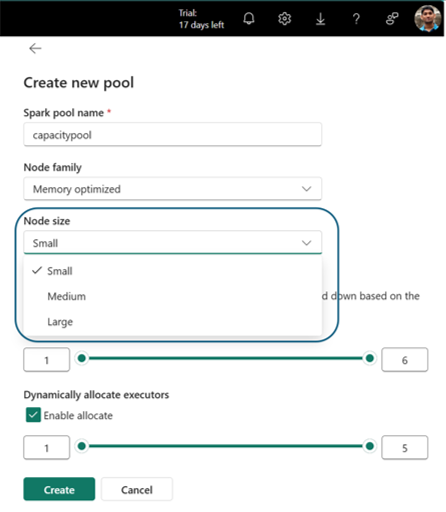
Vælg Opret for at gemme dine indstillinger.
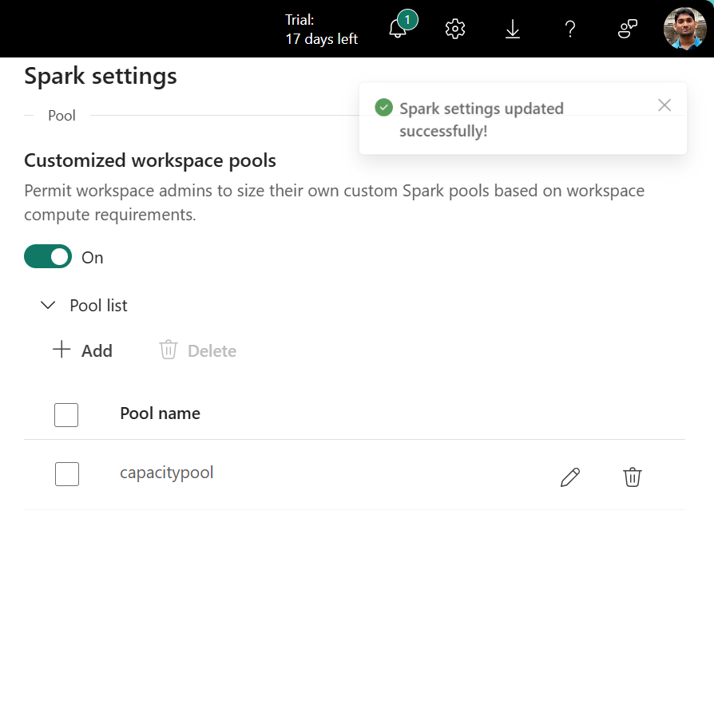



Bemærk
Brugerdefinerede puljer på kapacitetsniveau har en startventetid på 2-3 minutter. Hvis du vil have hurtigere start af Spark-sessionen (<5 sekunder), skal du bruge startpuljer, hvis den er aktiveret.
Når kapacitetspuljen er oprettet, bliver den tilgængelig i:
- Rullemenuen Valg af pulje i indstillinger for arbejdsområde
- Siden Indstillinger for miljøberegning i arbejdsområder
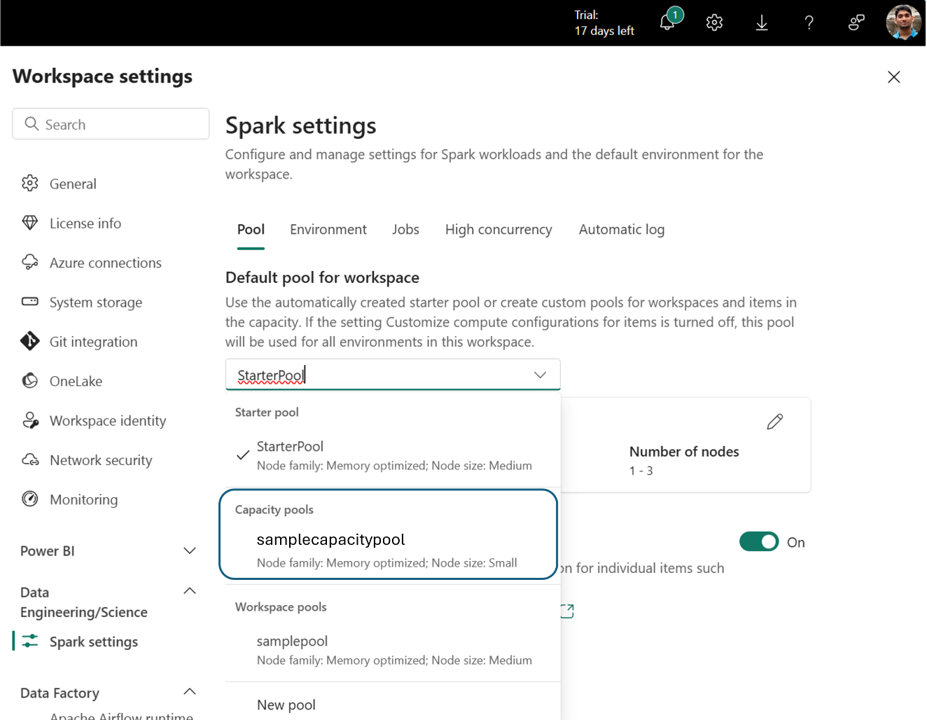
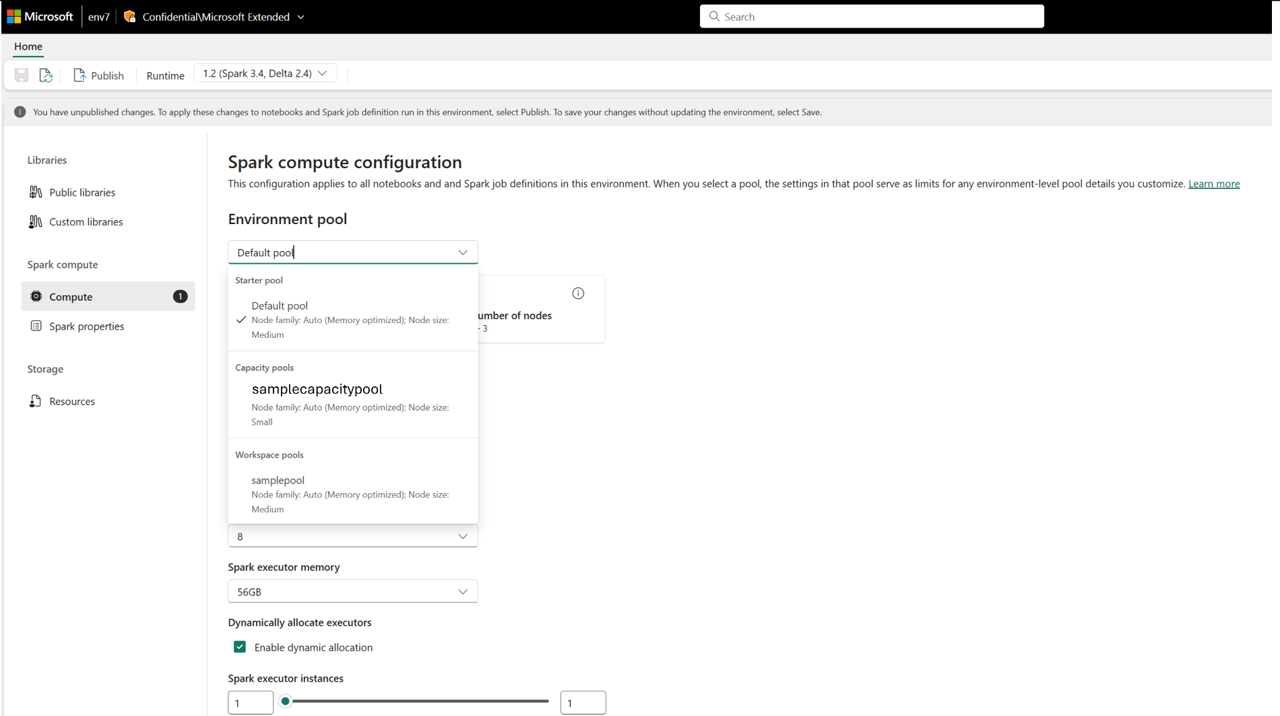
Dette muliggør centraliseret beregningsstyring. Administratorer kan oprette standardiserede puljer og eventuelt deaktivere tilpasning på arbejdsområdeniveau, hvilket forhindrer administratorer i arbejdsområder i at ændre puljeindstillinger eller oprette deres egne.

