Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅ Fabric Data Engineering og Data Science
Ressourceprofiler i Fabric Data Engineering hjælper dig med at få optimerede Spark-computekonfigurationer uden manuel justering. Du beskriver din arbejdsbyrde ved at vælge en primær brugssituation, datavolumen og et par andre højniveauinput. Fabric genererer derefter en anbefalet konfiguration — inklusive nodestørrelser, autoskaleringsindstillinger og runtime-version — baseret på dokumenterede bedste praksisser og interne performancedata.
Hvorfor bruge ressourceprofiler
Ressourceprofiler giver:
- Optimeret fra starten: Din første Spark-session kører på compute, der er tilpasset din arbejdsbyrde – ingen iterativ benchmarking nødvendig.
- Konsistens: Alle Spark-jobs i arbejdsområdet deler samme performance-tunede konfiguration.
- Bedre pris-ydelse: Ressourcer i rette størrelse reducerer spild og forbedrer gennemløbet.
- Lavere driftsomkostninger: Færre tuningcyklusser og færre supporteskaleringer.
Forudsætninger
For at konfigurere ressourceprofiler skal du have administratorrollen for arbejdsområdet.
Konfigurér en ressourceprofil
Sådan konfigurerer du en ressourceprofil til dit arbejdsområde:
Gå til dit arbejdsområde og vælg Arbejdsområdeindstillinger.
Udvid Data Engineering/Science i venstre panel og vælg derefter Spark-indstillinger.
For at få en anbefalet beregningskonfiguration til optimering af dit ressourceforbrug, vælg under Optimer til din brugssituation Get Started.
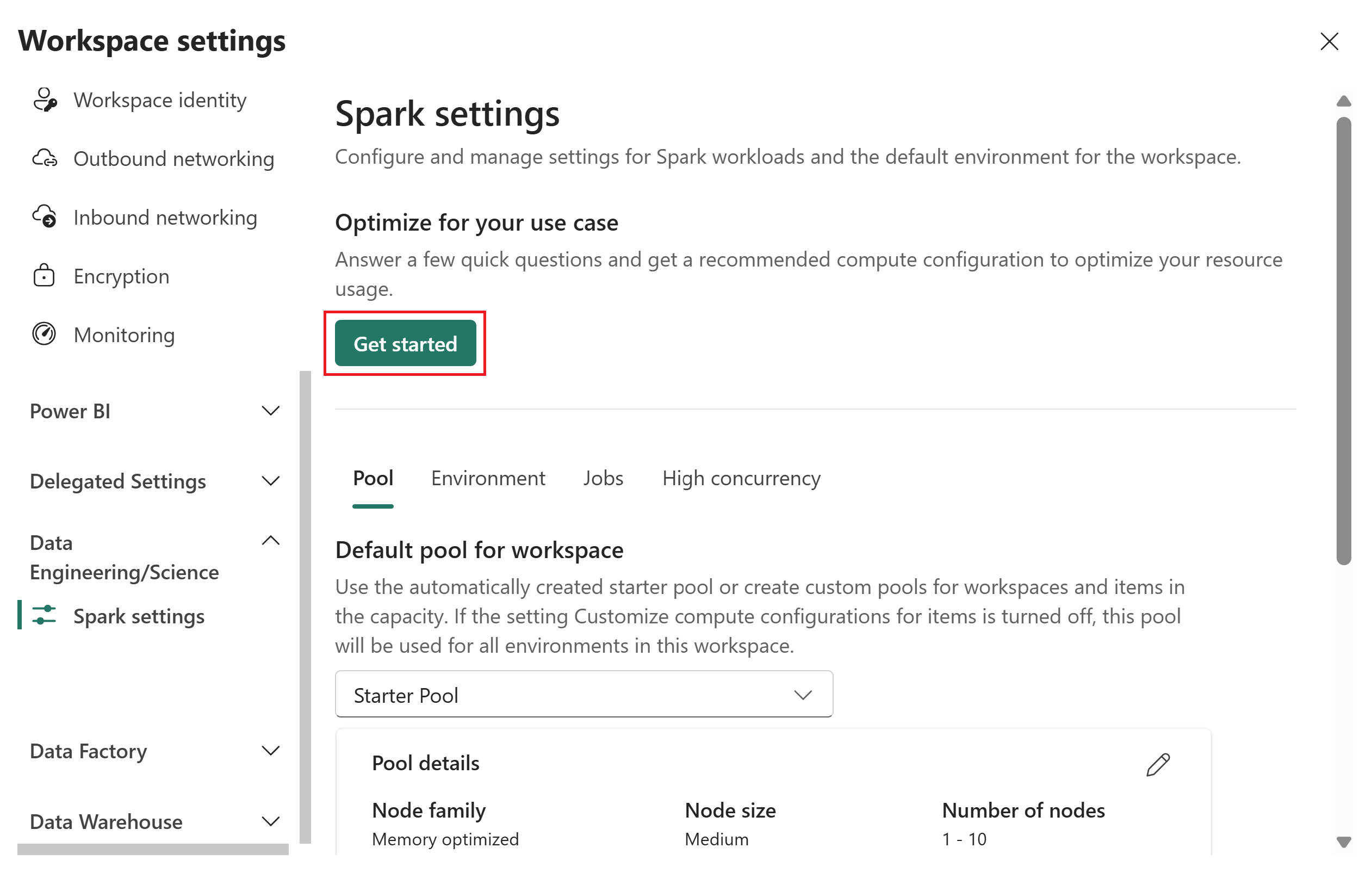
I siden Optimer for din brugssituation skal du angive følgende input:
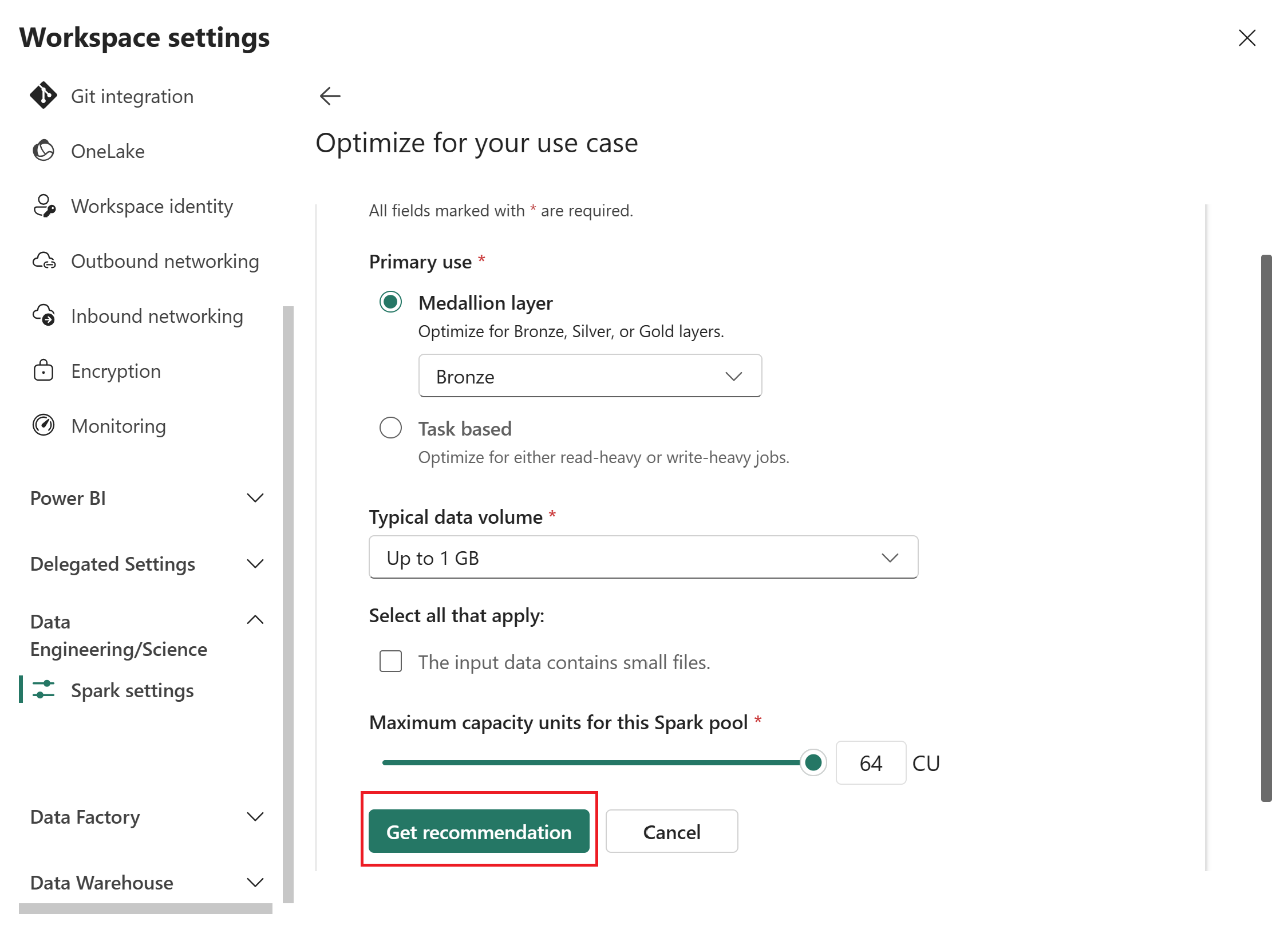
- Primær brugssituation: Vælg enten Medallion-laget eller Task based, og vælg derefter en specifik mulighed fra dropdown-menuen. Medallion-lagmulighederne er bronze, sølv eller guld. Opgavebaserede muligheder er læseoptimeret eller skriveoptimeret. For vejledning i valg af brugstilfælde, se Primær brugsreference.
- Typisk datavolumen: Vælg et volumen fra dropdown-menuen: Op til 1 GB,10 GB,100 GB,1 TB eller over 1 TB.
- Maksimale kapacitetsenheder (CU): Brug skyderen til at sætte den maksimale CU-grænse for Spark-poolen.
Vælg Få anbefaling.
Fabric genererer en optimeret konfiguration baseret på dine input.
Gennemgå anbefalingen. Anbefalingen omfatter værdier for to kategorier:
- Spark pool: Pooltype, nodefamilie, nodestørrelse, autoskalering og dynamisk eksekutorallokering.
- Miljø: Runtime-version, Spark-driverkerner og hukommelse, Spark-executor-kerner, hukommelse og instanser.
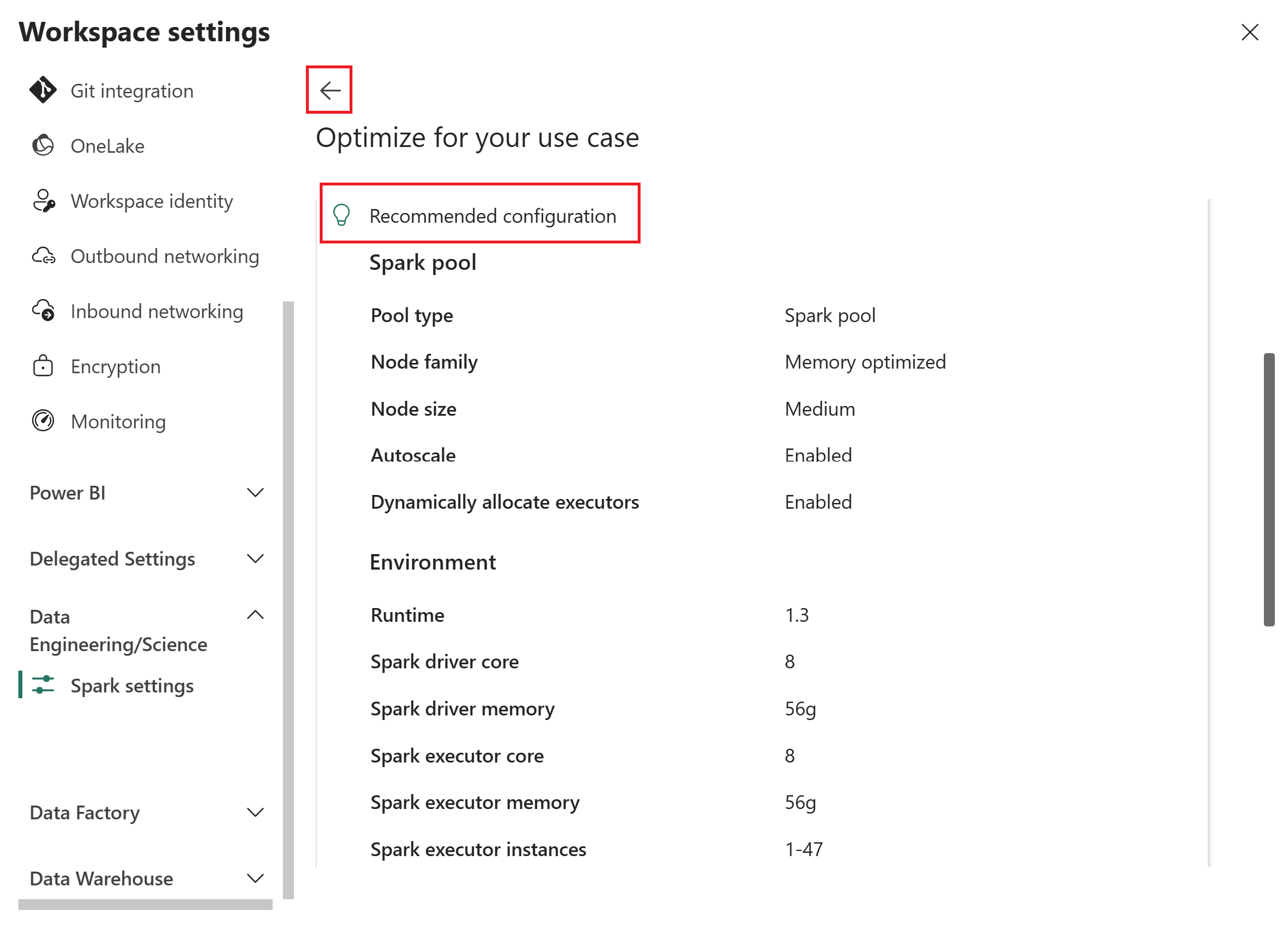
Hvis du vil justere dine input, vælg bagud-pilen for at vende tilbage til forrige side, opdater dine valg, og vælg derefter Get Recommendation igen.
Indtast et Spark-poolnavn og miljø for konfigurationen, og vælg derefter Apply for at gemme det i arbejdsområdet.
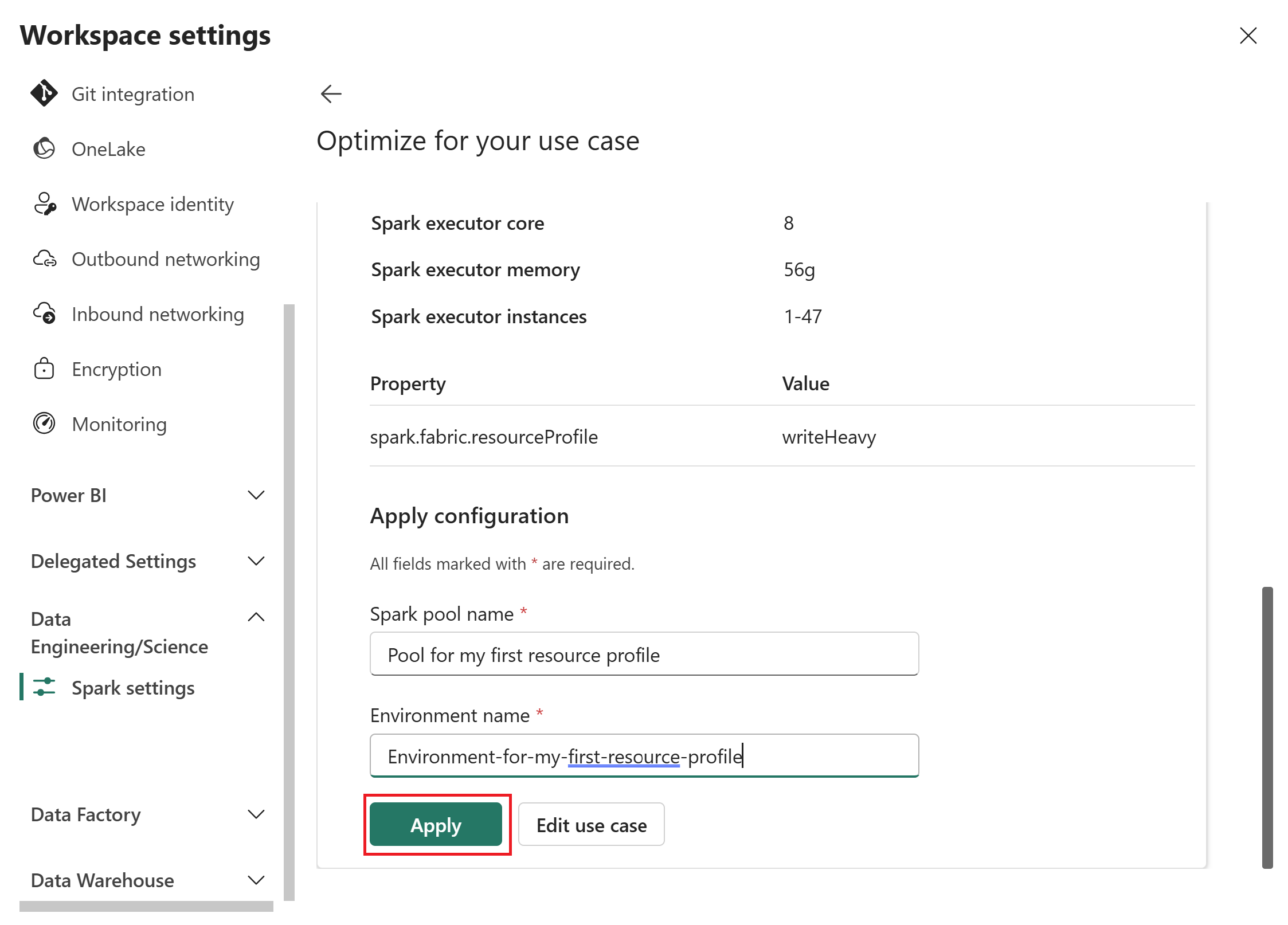




Efter du har anvendt en ressourceprofil, opretter Fabric en brugerdefineret Spark-pool med de anbefalede indstillinger.
Bemærkning
Hvis dit arbejdsområde ikke allerede har en brugerdefineret pool, sættes den nye pool automatisk som standardpool for workspace. Hvis dit arbejdsområde allerede har en standardpool, skal du manuelt skifte til den nye pool i dine Spark-arbejdsområdeindstillinger. Aktive sessioner påvirkes ikke, før de genoptages.
Primær reference for brugstilfælde
Brug følgende vejledning til at vælge det rigtige primære use case-input , når du konfigurerer en ressourceprofil:
Medaljonlag
Vælg Medallion-laget , hvis din datapipeline følger medaljonarkitektur-mønsteret, hvor data bevæger sig gennem Bronze (rå), Sølv (renset) og Guld (kurateret) faser. Hver mulighed justerer beregningen til de læse-/skriveegenskaber, der er typiske for det pågældende trin.
| Brugsscenarie | Hvornår skal du bruge? |
|---|---|
| Bronze | Rå dataindtagelse, høj skrivegennemstrømning, forskellige formater |
| Sølv | Rensning og berigelse, balanceret læse/skriv med moderate joins |
| Guld | Aggregation og rapportering, læseoptimeret til analyse og Power BI |
Opgavebaseret
Vælg Opgavebaseret , hvis din arbejdsbyrde ikke følger medallion-mønsteret, eller hvis den domineres af et enkelt adgangsmønster. Brug for eksempel denne mulighed til selvstændige ETL-jobs, interaktive analysenotebooks eller streaming-pipelines.
| Brugsscenarie | Hvornår skal du bruge? |
|---|---|
| Læs optimeret | Hyppige læsninger og forespørgsler, interaktive notesbøger |
| Skriveoptimering | Højvolumen-indtagelse, ETL-pipelines, streaming |
Auto-opdatere ressourceprofiler
Ressourceprofiler understøtter en automatisk opdateringsfunktion, der holder din Spark-computekonfiguration i overensstemmelse med de nyeste optimeringer fra Fabric. Når auto-opdatering er aktiveret, anvender Fabric arbejdsbelastningsspecifikke Spark-egenskaber baseret på din ressourceprofiltype uden manuel justering.
Auto-opdateringskonfigurationer
Fabric tilbyder tre auto-opdateringsprofiler, hver tilpasset et specifikt arbejdsbelastningsmønster:
Læsetungt for Spark-arbejdsbelastninger
Sat via spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate:
{
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "128"
}
Brug denne profil, når din arbejdsbyrde domineres af Spark-læsninger med moderate behov for skriveoptimering.
Læsetung for Power BI-arbejdsbelastninger
Sat via spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate:
{
"spark.sql.parquet.vorder.default": "true",
"spark.databricks.delta.optimizeWrite.enabled": "true",
"spark.databricks.delta.optimizeWrite.binSize": "1g"
}
Brug denne profil, når dine data primært forbruges af Power BI. V-Order er aktiveret for optimal DirectLake-ydelse, og en større bin-størrelse giver færre, større filer, der egner sig til analytiske læsninger.
Skrivetunge arbejdsbelastninger
Sat via spark.fabric.resourceProfile.writeHeavyAutoUpdate:
{
"spark.sql.parquet.vorder.default": "false",
"spark.databricks.delta.optimizeWrite.binSize": "128",
"spark.databricks.delta.optimizeWrite.partitioned.enabled": "true"
}
Brug denne profil, når din arbejdsbyrde er skriveintensiv (for eksempel high-volume ingestion eller ETL). V-Order er deaktiveret for at reducere skriveomkostninger, og optimeret skrivning med partitionering er aktiveret for effektiv fillayout.
Sådan fungerer auto-opdatering
Når en ressourceprofil med auto-opdatering anvendes:
- Fabric vælger den passende autoopdateringskonfiguration baseret på din primære brugssituation og arbejdsbelastningstype.
- Spark-egenskaberne anvendes automatisk på nye sessioner i arbejdsområdet.
- Aktive sessioner påvirkes ikke, før de starter igen.
Bemærkning
Auto-opdateringskonfigurationer optimerer Delta Lakes skriveadfærd og fillayout inden for rammerne af dine oprindelige profilinput. De ændrer ikke din poolstørrelse, nodekonfiguration eller autoskaleringsindstillinger.
Konfigurationsreference
| Setting | Anvendte egenskaber | Hvornår skal du bruge? |
|---|---|---|
spark.fabric.resourceProfile.readHeavyForSparkAutoUpdate |
Optimering af skrivning aktiveret, partitioneret skrivning, 128 MB bin-størrelse | Læse-tung Spark-analyse |
spark.fabric.resourceProfile.readHeavyForPBIAutoUpdate |
V-Order aktiveret, optimer skrivning, 1 GB bin-størrelse | Læse-tung Power BI/DirectLake |
spark.fabric.resourceProfile.writeHeavyAutoUpdate |
V-Order deaktiveret, optimering af skrivning, 128 MB bin-størrelse, opdelt | Skrivetyngre indlæsning og ETL |