Brug en notesbog til at indlæse data i dit lakehouse
I dette selvstudium kan du få mere at vide om, hvordan du læser/skriver data i dit Fabric lakehouse med en notesbog. Fabric understøtter Spark API og Pandas API'er for at nå dette mål.
Indlæs data med en Apache Spark-API
I kodecellen i notesbogen skal du bruge følgende kodeeksempel til at læse data fra kilden og indlæse dem i filer, tabeller eller begge dele af dit lakehouse.
Hvis du vil angive den placering, der skal læses fra, kan du bruge den relative sti, hvis dataene er fra standardsøhuset for din aktuelle notesbog. Eller hvis dataene er fra et andet lakehouse, kan du bruge den absolutte ABFS-sti (Azure Blob File System). Kopiér denne sti fra genvejsmenuen for dataene.
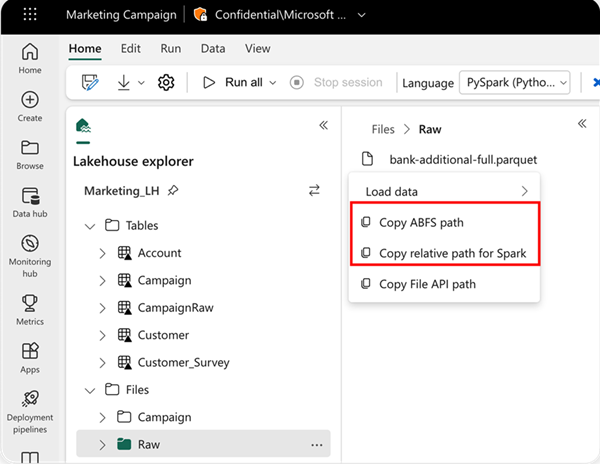
Kopiér ABFS-sti: Denne indstilling returnerer filens absolutte sti.
Kopiér relativ sti til Spark: Denne indstilling returnerer den relative sti til filen i dit standard lakehouse.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Indlæs data med Pandas API
For at understøtte Pandas API installeres standard lakehouse automatisk til notesbogen. Monteringspunktet er '/lakehouse/default/'. Du kan bruge dette monteringspunkt til at læse/skrive data fra/til standard lakehouse. Indstillingen "Kopiér fil-API-sti" fra genvejsmenuen returnerer fil-API-stien fra det pågældende tilslutningspunkt. Den sti, der returneres fra indstillingen Kopiér ABFS-sti , fungerer også for Pandas API.
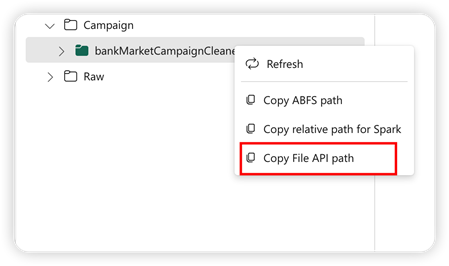
Kopiér fil-API-sti: Denne indstilling returnerer stien under tilslutningspunktet for standard lakehouse.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Tip
Til Spark API skal du bruge indstillingen Kopiér ABFS-sti eller Kopiér relativ sti til Spark for at hente stien til filen. For Pandas API skal du bruge indstillingen Kopiér ABFS-sti eller Kopiér fil-API-sti for at hente stien til filen.
Den hurtigste måde at få koden til at arbejde med Spark API eller Pandas API på er ved at bruge indstillingen Indlæs data og vælge den API, du vil bruge. Koden genereres automatisk i en ny kodecelle i notesbogen.
