Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Fabric Runtime tilbyder en problemfri integration med Azure. Det giver et sofistikeret miljø til både datakonstruktions- og datavidenskabsprojekter, der bruger Apache Spark. Denne artikel giver et overblik over de væsentlige funktioner og komponenter i Fabric Runtime 1.3.
Microsoft Fabric Runtime 1.3 er en GA runtime-version, der indeholder følgende komponenter og opgraderinger designet til at forbedre dine databehandlingsmuligheder:
Apache Spark 3,5
Operativsystem: Mariner 2.0
Java: 11
Størrelse: 2.12.17
Python: 3.11
Delta Lake: 3,2
R: 4.4.1
Tips
Fabric Runtime 1.3 omfatter understøttelse af det oprindelige eksekveringsprogram, som kan forbedre ydeevnen markant uden flere omkostninger. Hvis du vil aktivere det oprindelige udførelsesprogram på tværs af alle job og notesbøger i dit miljø, skal du navigere til dine miljøindstillinger, vælge Spark compute, gå til fanen Acceleration og markere Aktivér oprindeligt udførelsesprogram. Når du har gemt og publiceret, anvendes denne indstilling på tværs af miljøet, så alle nye job og notesbøger automatisk arver og drager fordel af de forbedrede ydeevnefunktioner.
Integrer Runtime 1.3
Notat
For information om alle tilgængelige Fabric-runtimes og deres nuværende status, se Apache Spark Runtimes i Fabric.
Brug følgende instruktioner til at integrere runtime 1.3 i dit arbejdsområde og bruge de nye funktioner:
Gå til fanen Indstillinger for arbejdsområde i dit Fabric-arbejdsområde.
Gå til fanen Dataudvikler ing/Videnskab, og vælg Spark-indstillinger.
Vælg fanen Miljø .
Udvid rullelisten under Kørselsversioner.
Vælg 1.3 (Spark 3.5, Delta 3.2), og gem dine ændringer. Denne handling angiver 1.3 som standardkørsel for dit arbejdsområde.
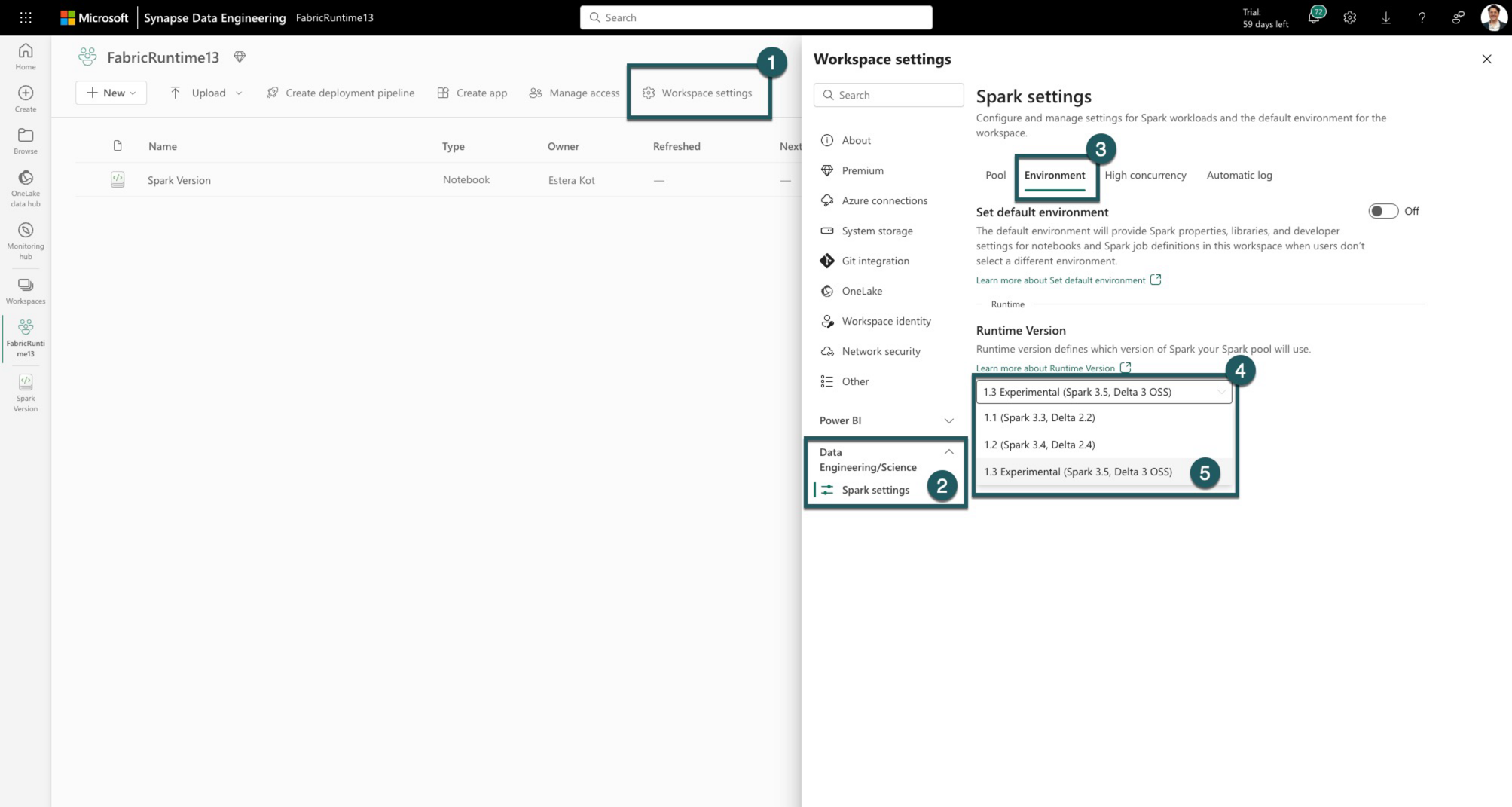

Du kan nu begynde at arbejde med de nyeste forbedringer og funktioner, der er introduceret i Fabric runtime 1.3 (Spark 3.5 og Delta Lake 3.2).
Få mere at vide om Apache Spark 3.5
Apache Spark 3.5.0 er den sjette version i 3.x-serien. Denne version er et produkt af omfattende samarbejde inden for open source-community'et, der løser mere end 1.300 problemer som registreret i Jira.
I denne version er der en opgradering i kompatibilitet til struktureret streaming. Denne version udvider desuden funktionaliteten i PySpark og SQL. Den tilføjer funktioner som SQL-id-delsætningen, navngivne argumenter i SQL-funktionskald og medtagelse af SQL-funktioner til omtrentlige sammenlægninger af HyperLogLog.
Andre nye funktioner omfatter også brugerdefinerede Python-tabelfunktioner, forenkling af distribueret træning via DeepSpeed og nye strukturerede streamingfunktioner, f.eks. vandmærkeoverførsel og dropDuplicatesWithinWatermark-handlingen .
Du kan kontrollere den komplette liste og detaljerede ændringer her: Spark Release 3.5.0.
Få mere at vide om Delta Spark
Delta Lake 3.2 markerer en kollektiv forpligtelse til at gøre Delta Lake kompatibel på tværs af formater, nemmere at arbejde med og mere effektiv. Delta Spark 3.2 er bygget oven på Apache Spark™ 3.5. Delta Spark maven-artefaktet omdøbes fra delta-core til delta-spark.
Du kan kontrollere den komplette liste og detaljerede ændringer her: https://docs.delta.io/index.html.
Komponenter og biblioteker
Hvis du vil have opdaterede oplysninger, en detaljeret liste over ændringer og specifikke produktbemærkninger til Fabric-kørsel, skal du kontrollere og abonnere på Spark Runtimes-udgivelser og -opdateringer.
Notat
EventHubConnector udfases i Fabric Runtime 1.3 (Spark 3.5) og fjernes fra fremtidige Fabric Runtime-versioner. Kunder opfordres til i stedet at bruge Kafka Spark Connector, da Event Hubs allerede er Kafka-kompatible. Du kan finde mere information om brug af Kafka Spark Connector med Event Hubs her: Event Hubs Kafka Spark Tutorial
Relateret indhold
- Læs om Apache Spark Runtimes i Fabric – Oversigt, Versionering, Understøttelse af flere runtimes og opgradering af Delta Lake-protokollen
- Spark Core-migreringsvejledning
- Vejledninger til migrering af SQL, Datasæt og DataFrame
- Vejledning til struktureret overførsel af streaming
- Overflytningsvejledning til MLlib (Machine Learning)
- Migreringsvejledning til PySpark (Python on Spark)
- SparkR-migreringsvejledning (R on Spark)