Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Hurtig kopiering hjælper dig med at flytte store mængder data hurtigere i Dataflow Gen2. Tænk på det som at skifte til en mere kraftfuld motor, når du skal håndtere terabyte data.
Når du arbejder med dataflow, skal du først indtage data og derefter transformere dem. Med udskalering af dataflow ved hjælp af SQL DW-beregning kan du transformere data i stor skala. Hurtig kopiering tager sig af indtagelsesdelen ved at give dig den nemme dataflowoplevelse med den effektive backend af pipelinekopieringsaktivitet.
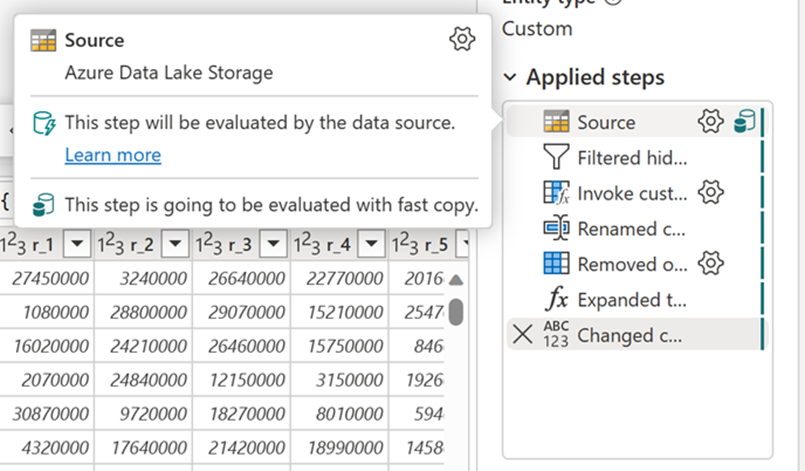
Sådan fungerer det: Når du har aktiveret hurtig kopiering, skifter dataflow automatisk til den hurtigere backend, når din datastørrelse overskrider en bestemt grænse. Du behøver ikke at ændre noget, mens du opbygger dine dataflow. Når dit dataflow er opdateret, kan du kontrollere opdateringshistorikken for at se, om der blev brugt hurtig kopiering, ved at se på den programtype , der er angivet der.
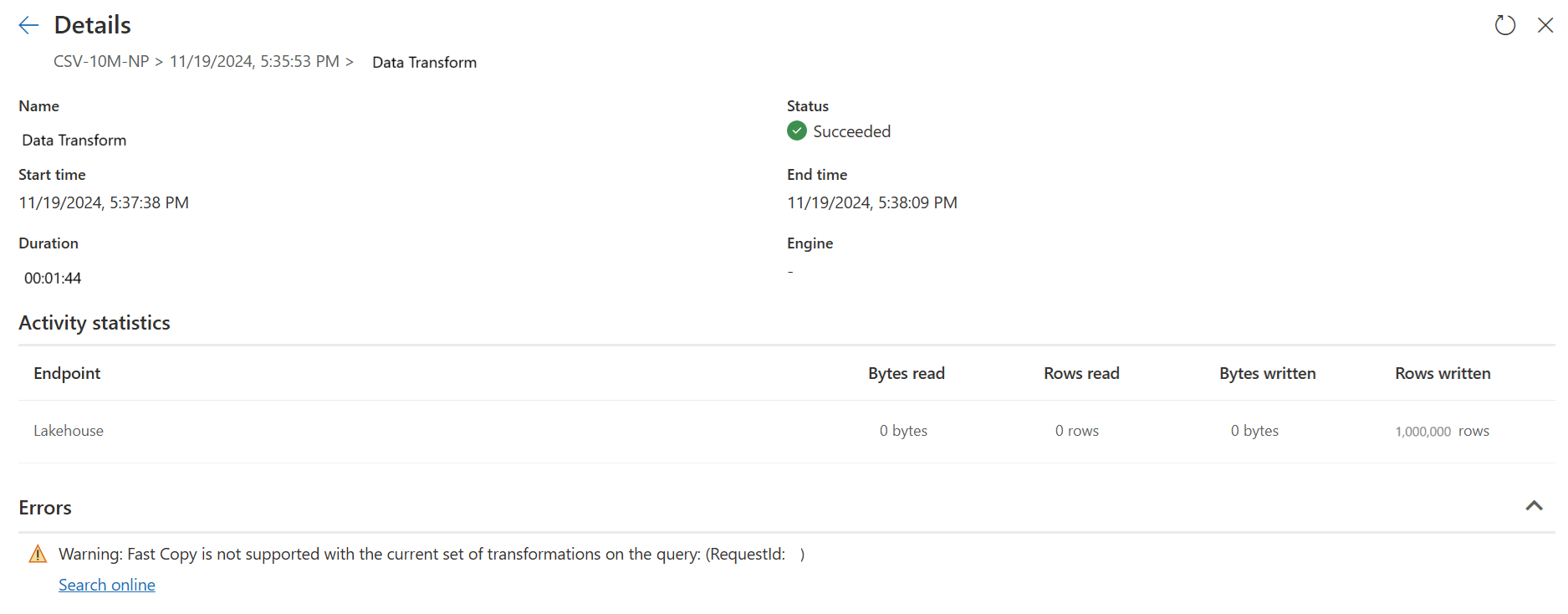
Hvis du aktiverer indstillingen Kræv hurtig kopiering , stopper opdateringen af dataflowet, hvis hurtig kopiering af en eller anden grund ikke kan bruges. Dette hjælper dig med at undgå at vente på en timeout og kan være nyttigt ved fejlfinding. Du kan bruge indikatorerne for hurtig kopiering i ruden med forespørgselstrin til at kontrollere, om forespørgslen kan køre med hurtig kopiering.
Prerequisites
Før du kan bruge hurtig kopiering, skal du bruge:
- En strukturkapacitet
- Fildata: CSV- eller Parquet-filer, der er mindst 100 MB og gemt i Azure Data Lake Storage (ADLS) Gen2 eller Blob Storage
- For databaser (herunder Azure SQL DB og PostgreSQL): 5 millioner rækker eller mere data i datakilden
Note
Du kan tilsidesætte tærsklen for at gennemtvinge hurtig kopiering ved at vælge indstillingen Kræv hurtig kopiering .
Understøttelse af stik
Hurtig kopiering fungerer med disse Dataflow Gen2-connectorer:
- ADLS Gen2
- Blob-lager
- Azure SQL DB
- Lakehouse
- PostgreSQL
- SQL Server i det lokale miljø
- Warehouse
- Oracle
- Snowflake
- SQL-database i Fabric
Begrænsninger for transformation
Når du opretter forbindelse til filkilder, understøtter kopieringsaktiviteten kun disse transformationer:
- Kombiner filer
- Vælg kolonner
- Skift datatyper
- Omdøb en kolonne
- Fjern en kolonne
Hvis du har brug for andre transformationer, kan du opdele dit arbejde i separate forespørgsler. Opret én forespørgsel for at hente dataene og en anden forespørgsel, der refererer til den første. På denne måde kan du bruge DW-beregning til transformationerne.
For SQL-kilder fungerer enhver transformation, der er en del af den oprindelige forespørgsel, fint.
Destinationer for output
Lige nu understøtter hurtig kopiering kun indlæsning direkte til en Lakehouse-destination. Hvis du vil bruge en anden outputdestination, kan du klargøre forespørgslen først og referere til den i en senere forespørgsel med din foretrukne destination.
Sådan bruger du hurtig kopi
Sådan konfigurerer og bruger du hurtig kopiering:
I Fabric skal du gå til et Premium-arbejdsområde og oprette en Dataflow Gen2.
Under fanen Hjem i dit nye dataflow skal du vælge Indstillinger:
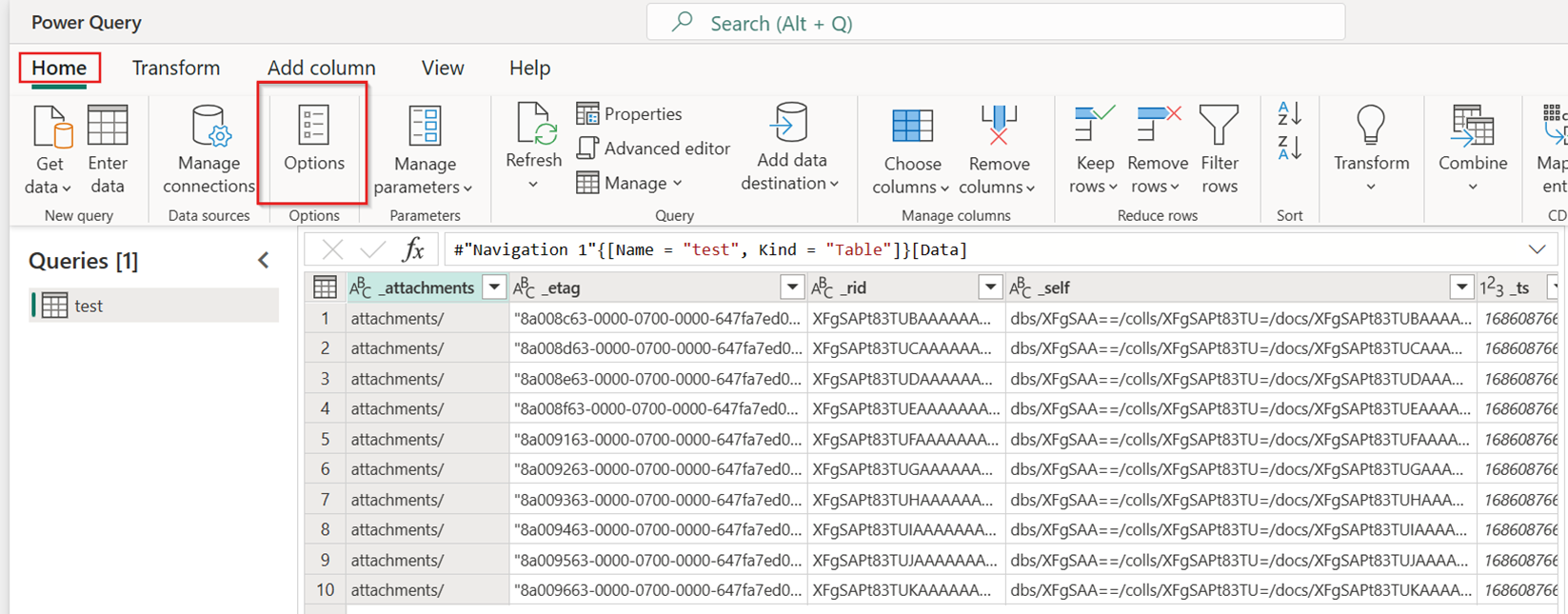
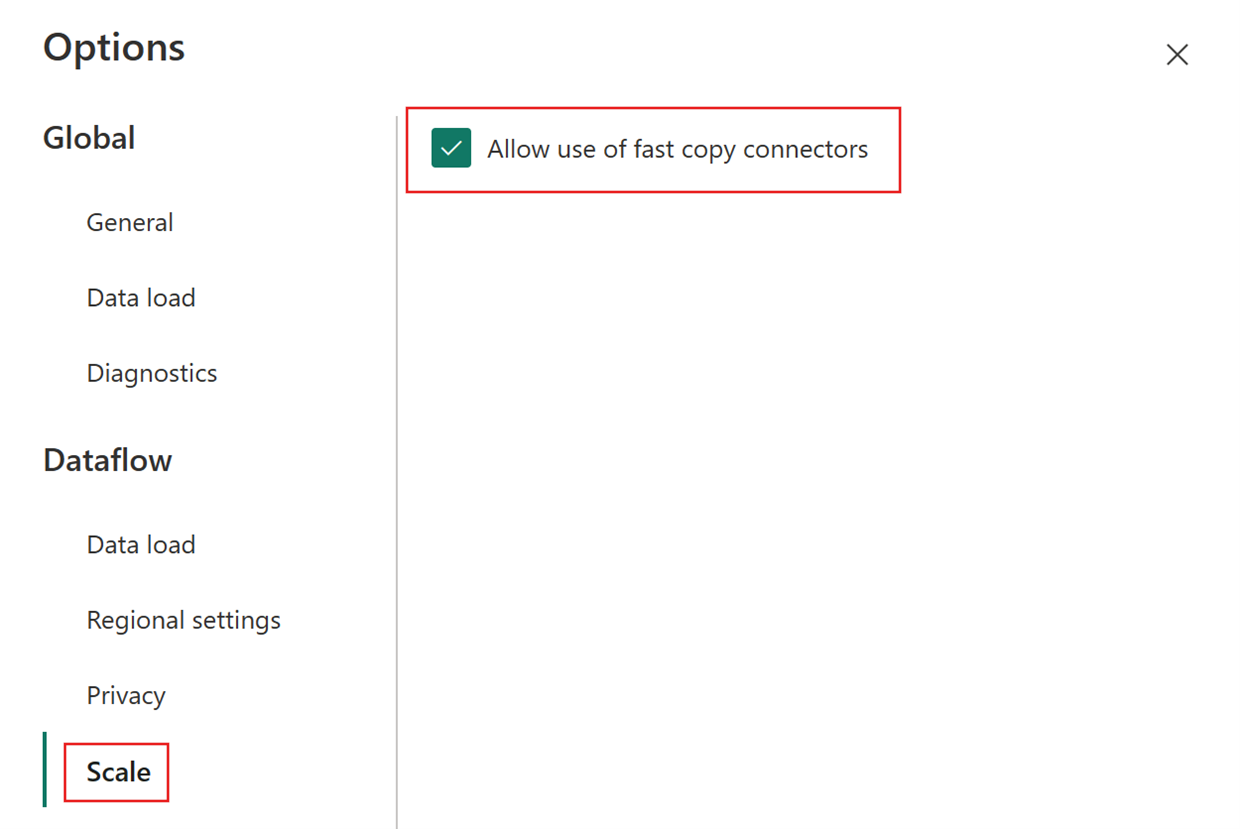
I dialogboksen Indstillinger skal du vælge fanen Skaler og derefter slå Tillad brug af hurtige kopieringsforbindelser til. Luk dialogboksen Indstillinger , når du er færdig.
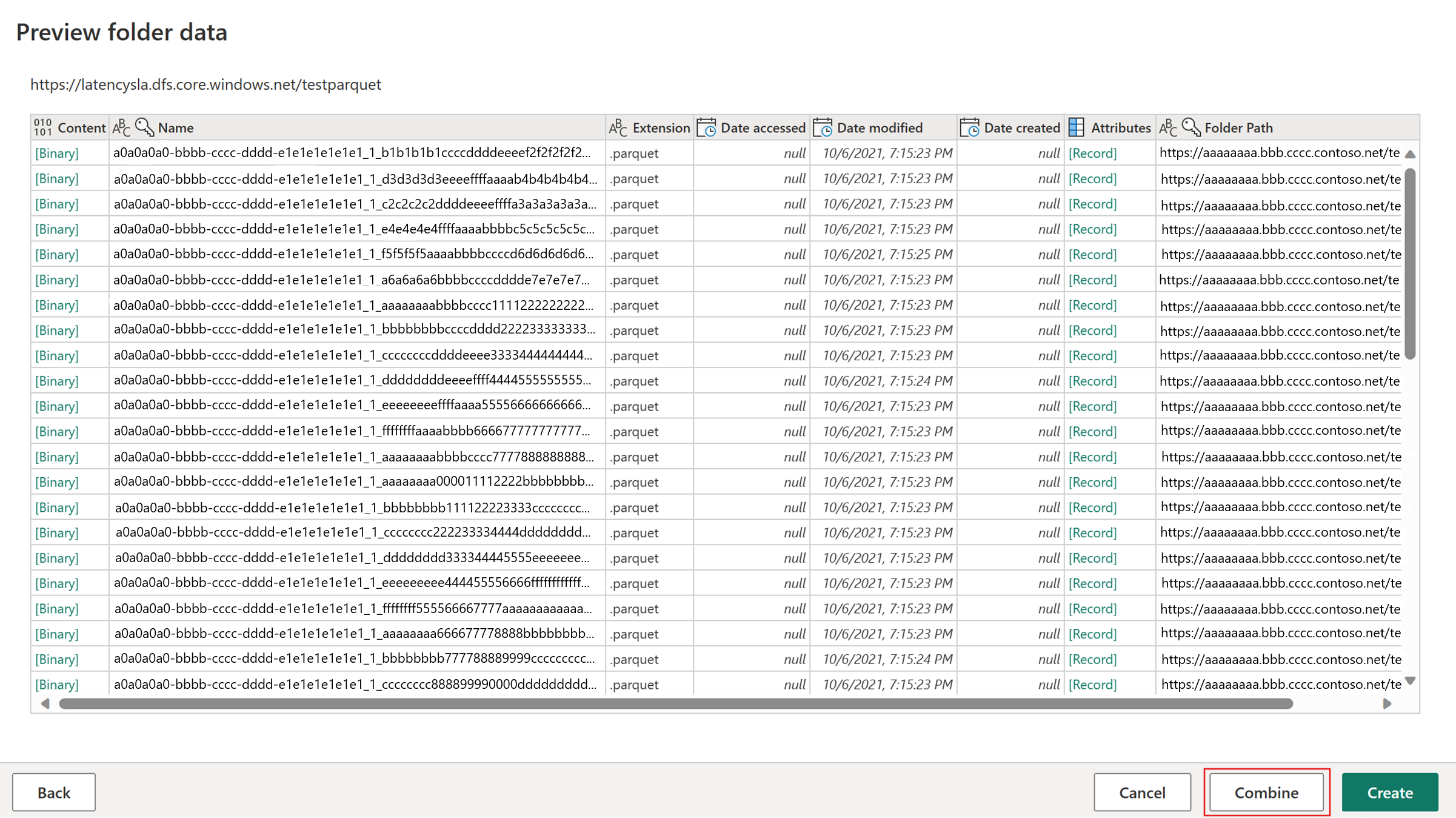
Vælg Hent data, vælg ADLS Gen2-kilden, og udfyld detaljerne for din objektbeholder.
Vælg knappen Kombiner .
Hvis du vil sikre, at hurtig kopiering fungerer, skal du kun anvende transformationer, der er angivet i afsnittet Connectorsupport . Hvis du har brug for andre transformationer, skal du klargøre dataene først og referere til den faseinddelte forespørgsel i en senere forespørgsel. Anvend dine andre transformationer på den forespørgsel, der refereres til.
(Valgfrit) Du kan kræve hurtig kopi af forespørgslen ved at højreklikke på forespørgslen og vælge Kræv hurtig kopi.
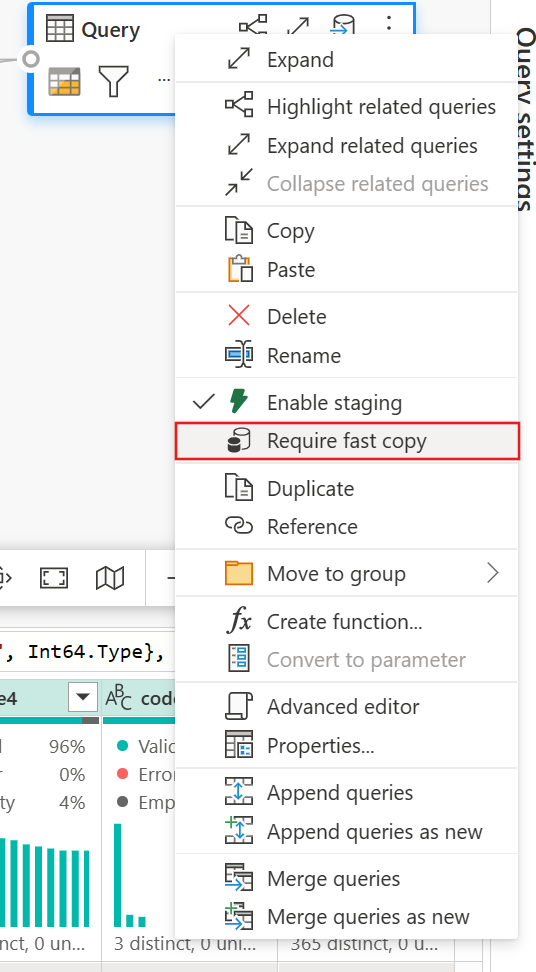
(Valgfrit) Lige nu kan du kun oprette et Lakehouse som outputdestination. For enhver anden destination skal du fase forespørgslen og referere til den senere i en anden forespørgsel, hvor du kan skrive til en hvilken som helst kilde.
Kontrollér indikatorerne for hurtig kopiering for at sikre, at din forespørgsel kan køre med hurtig kopiering. Hvis det er muligt, viser ProgramtypeCopyActivity.

Publicer dataflowet.
Når opdateringen er fuldført, skal du kontrollere, at der blev brugt hurtig kopi.



Sådan opdeler du din forespørgsel for at bruge hurtig kopi
Når du arbejder med store mængder data, kan du få den bedste ydeevne ved at bruge hurtig kopiering til at indtage data i midlertidig lagring først og derefter transformere dem i stor skala med SQL DW-beregning.
Hurtige kopieringsindikatorer hjælper dig med at finde ud af, hvordan du opdeler din forespørgsel i to dele: dataindtagelse til midlertidig lagring og transformation i stor skala med SQL DW-beregning. Prøv at skubbe så meget af din forespørgselsevaluering til hurtig kopi som muligt til dataindtagelse. Når indikatorerne for hurtig kopiering viser, at de resterende trin ikke kan køre med hurtig kopiering, kan du opdele resten af forespørgslen med midlertidig lagring aktiveret.
Indikatorer for trindiagnosticering
| Indicator | Icon | Description |
|---|---|---|
| Dette trin vil blive evalueret med hurtig kopi | 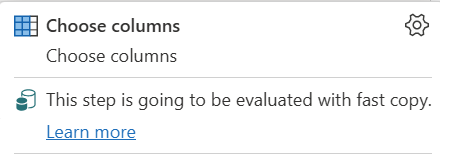
|
Indikatoren for hurtig kopiering viser, at forespørgslen op til dette trin understøtter hurtig kopiering. |
| Dette trin understøttes ikke af hurtig kopiering | 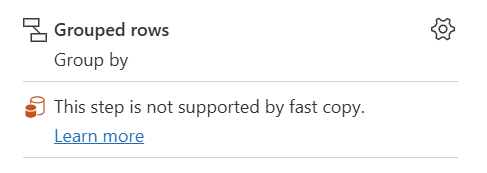
|
Indikatoren for hurtig kopiering viser, at dette trin ikke understøtter hurtig kopi. |
| Et eller flere trin i forespørgslen understøttes ikke af hurtig kopiering | 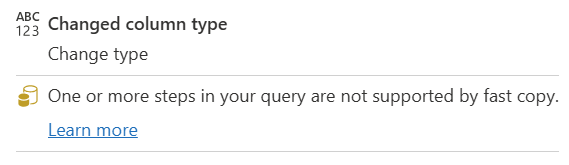
|
Indikatoren for hurtig kopiering viser, at nogle trin i denne forespørgsel understøtter hurtig kopiering, mens andre ikke gør det. Hvis du vil optimere, skal du opdele forespørgslen: gule trin (understøttes muligvis af hurtig kopi) og røde trin (understøttes ikke). |
Trin-for-trin vejledning
Når du har fuldført din datatransformationslogik i Dataflow Gen2, evaluerer indikatoren for hurtig kopiering hvert trin for at finde ud af, hvor mange trin der kan bruge hurtig kopiering for at opnå bedre ydeevne.
I dette eksempel viser det sidste trin et rødt ikon, hvilket betyder, at trinnet Gruppér efter ikke understøttes af hurtig kopi. Alle de foregående trin med gule ikoner kan dog potentielt understøttes af hurtig kopiering.

Hvis du publicerer og kører dit dataflow Gen2 på dette tidspunkt, bruger det ikke programmet til hurtig kopiering til at indlæse dine data.

Hvis du vil bruge programmet til hurtig kopiering og forbedre ydeevnen for dit dataflow Gen2, kan du opdele din forespørgsel i to dele: dataindtagelse til midlertidig lagring og transformation i stor skala med SQL DW-beregning. Sådan gør du:
Slet alle transformationer, der viser røde ikoner (hvilket betyder, at de ikke understøttes af hurtig kopiering) sammen med destinationen (hvis du har defineret en).
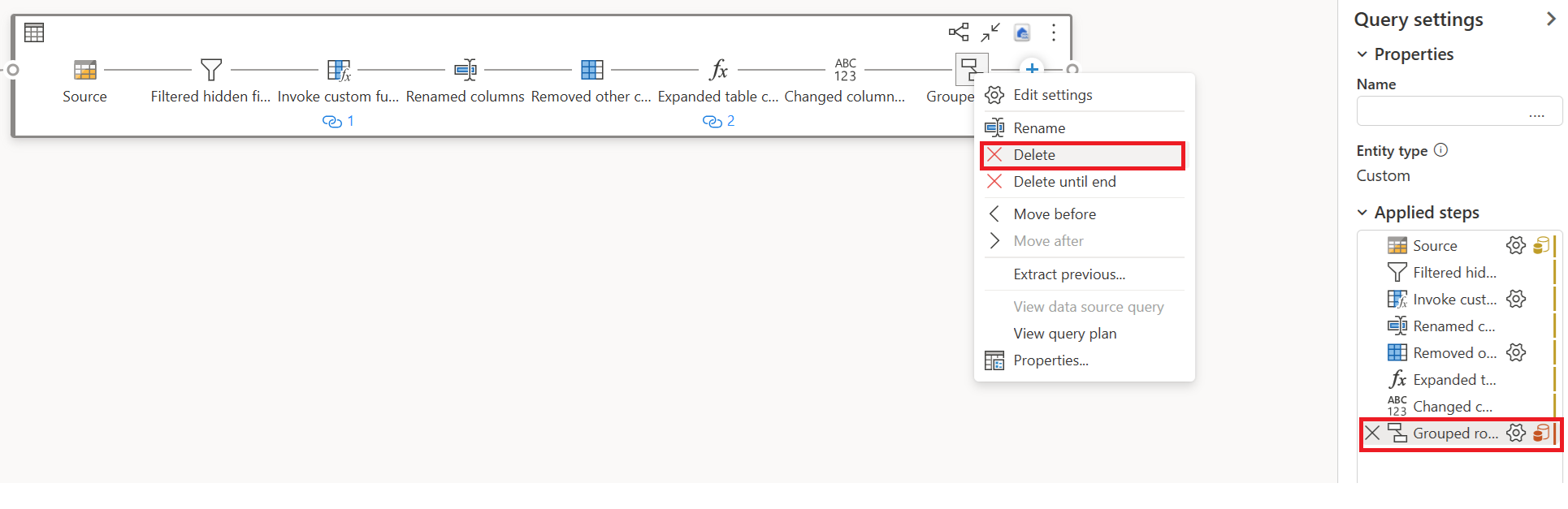
Indikatoren for hurtig kopiering viser nu grønt for de resterende trin, hvilket betyder, at din første forespørgsel kan bruge hurtig kopiering for at opnå bedre ydeevne.
Højreklik på din første forespørgsel, vælg Aktivér midlertidig lagring, højreklik derefter på din første forespørgsel igen, og vælg Reference.
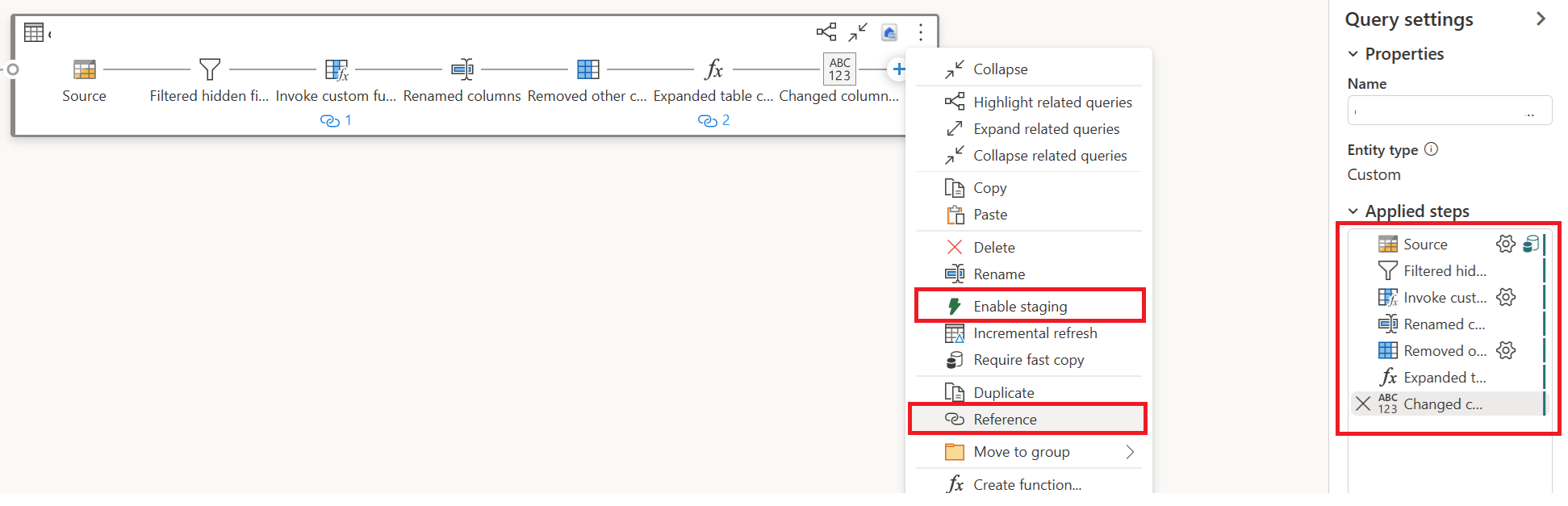
I den nye forespørgsel, der refereres til, skal du tilføje transformationen "Gruppér efter" og destinationen (hvis det er relevant).
Publicer og opdater dit Dataflow Gen2. Du har nu to forespørgsler i dit dataflow Gen2, og den samlede varighed er kortere.
Den første forespørgsel henter data til midlertidig lagring ved hjælp af hurtig kopi.
Den anden forespørgsel udfører transformationer i stor skala ved hjælp af SQL DW-beregning.
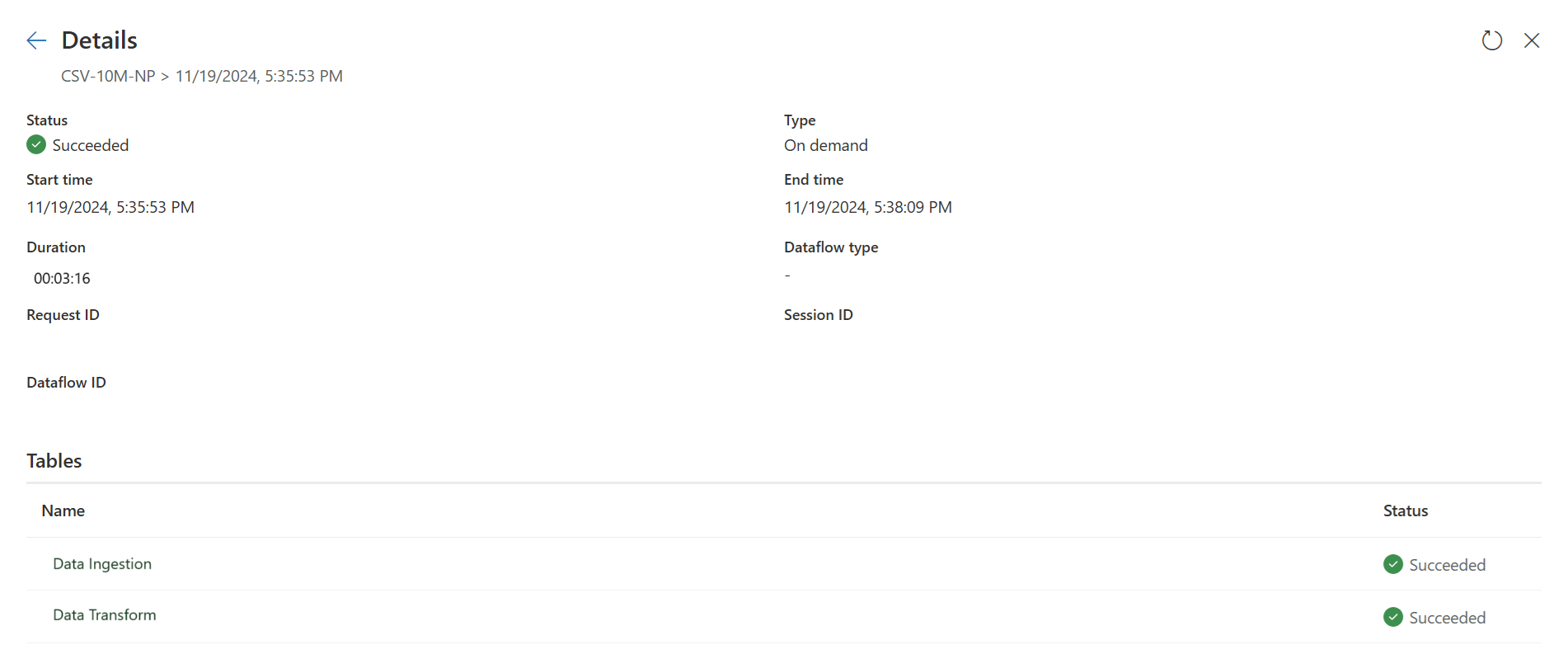
De første forespørgselsoplysninger:
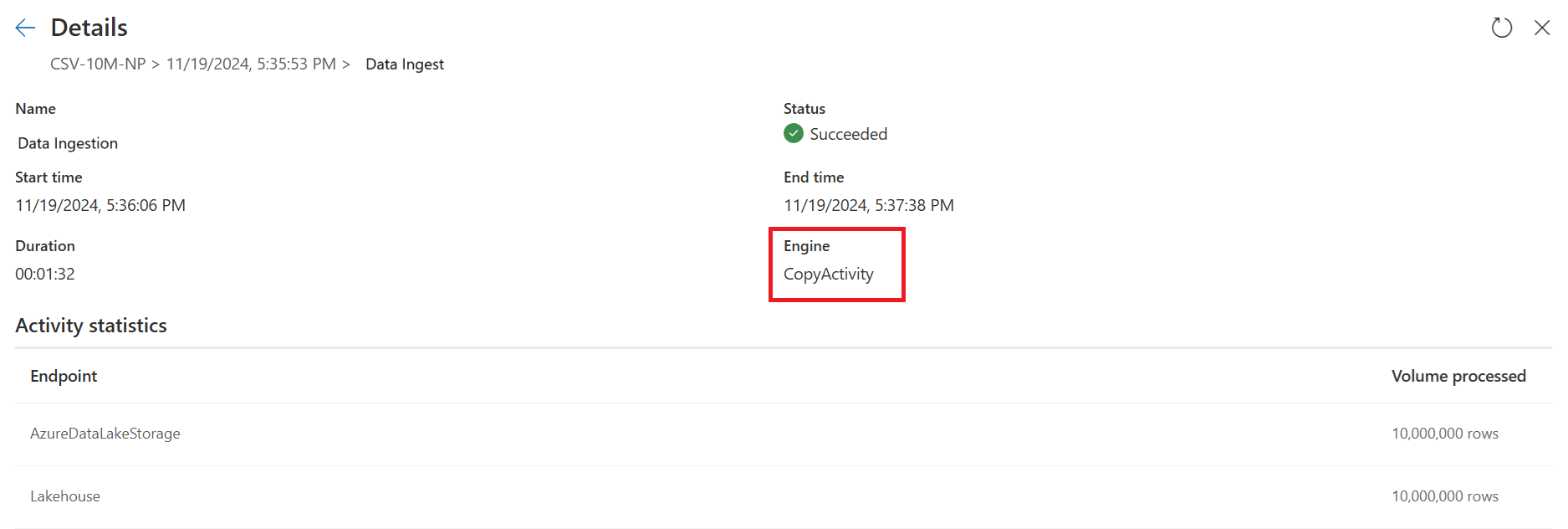
Den anden forespørgselsdetaljer:




Kendte begrænsninger
Her er de aktuelle begrænsninger for hurtig kopiering:
- Du skal have en datagateway i det lokale miljø version 3000.214.2 eller nyere for at understøtte hurtig kopiering.
- Fast skema understøttes ikke.
- Skemabaseret destination understøttes ikke