Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Brug aktiviteten Notebook til at køre notebooks du opretter i Microsoft Fabric som en del af dine Data Factory-pipelines. Med notesbøger kan du køre Apache Spark-job for at hente, rydde op i eller transformere dine data som en del af dine dataarbejdsprocesser. Det er nemt at tilføje en Notesbogsaktivitet til dine pipelines i Fabric, og denne guide guider dig gennem hvert trin.
Forudsætninger
For at komme i gang skal du fuldføre følgende forudsætninger:
- Du skal have adgang til en Microsoft Fabric lejer med en provisioneret kapacitet. Du kan prøve Fabric med en gratis prøveperiode.
- En Fabric workspace tildelt den kapacitet.
- Der oprettes en notesbog i dit arbejdsområde. For at oprette en ny notesbog, se Sådan opretter du Microsoft Fabric notesbøger.
Opret en notesbogaktivitet
Opret en ny pipeline i dit arbejdsområde.
Søg efter Notesbog i ruden Pipelineaktiviteter, og vælg den for at føje den til pipelinelærredet.
Vælg den nye notesbogaktivitet på lærredet, hvis den ikke allerede er valgt.
Se vejledningen til generelle indstillinger for at konfigurere fanen Generelle indstillinger.
Konfigurer indstillinger for notesbog
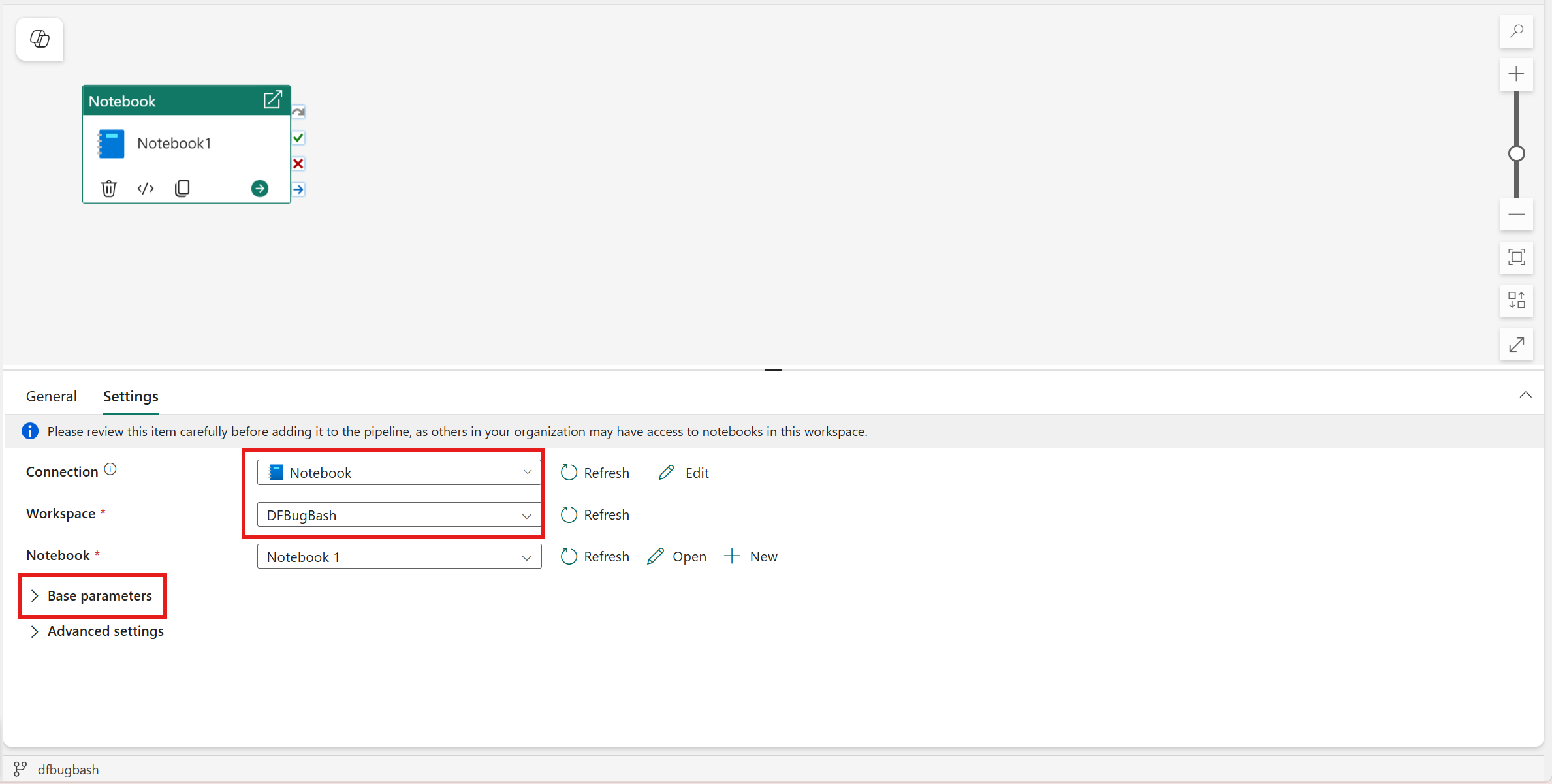
Vælg fanen Indstillinger.
Under Forbindelse skal du vælge autentificeringsmetoden for notebook-kørslen og angive de nødvendige legitimationsoplysninger.
Vælg en eksisterende notesbog fra notesbogsmenuen , og angiv eventuelt eventuelle parametre, der skal sendes til notesbogen.
Brug af Fabric Workspace Identity (WI) i Notebook-aktiviteten
Opret Workspace-identiteten
Du skal aktivere WI i dit arbejdsområde (det kan tage et øjeblik at indlæse). Opret en arbejdsområdeidentitet i dit Fabric-arbejdsområde. Bemærk, at WI skal oprettes i samme arbejdsområde som din Pipeline.
Tjek dokumentationen om Workspace Identity.
Aktiver lejerniveau-indstillinger
Aktivér følgende lejerindstilling (den er deaktiveret som standard): Serviceprincipaler kan kalde Fabric offentlige API'er.
Du kan aktivere denne indstilling i Fabric admin-portalen. For mere information om denne indstilling, se artiklen om enable service principal authentication for admin APIs.
Giv workspace-tilladelser til Workspace Identity
Åbn arbejdsområdet, vælg Administrer adgang, og tildel tilladelser til Workspace Identity. Bidragyderadgang er tilstrækkelig i de fleste scenarier. Hvis din Notebook ikke er i samme arbejdsområde som din Pipeline, skal du tildele den WI, du har oprettet i din Pipelines arbejdsområde, mindst bidragyderadgang til din Notebooks arbejdsområde.
Tjek dokumentationen om Giv brugere adgang til arbejdsområder.
Angiv sessionsmærke
Hvis du vil minimere den tid, det tager at udføre notesbogjobbet, kan du eventuelt angive et sessionsmærke. Når du angiver sessionskoden, får Spark besked om at genbruge en eksisterende Spark-session, hvilket minimerer starttidspunktet. Alle vilkårlige strengværdier kan bruges til sessionskoden. Hvis der ikke findes en session, oprettes der en ny ved hjælp af kodeværdien.
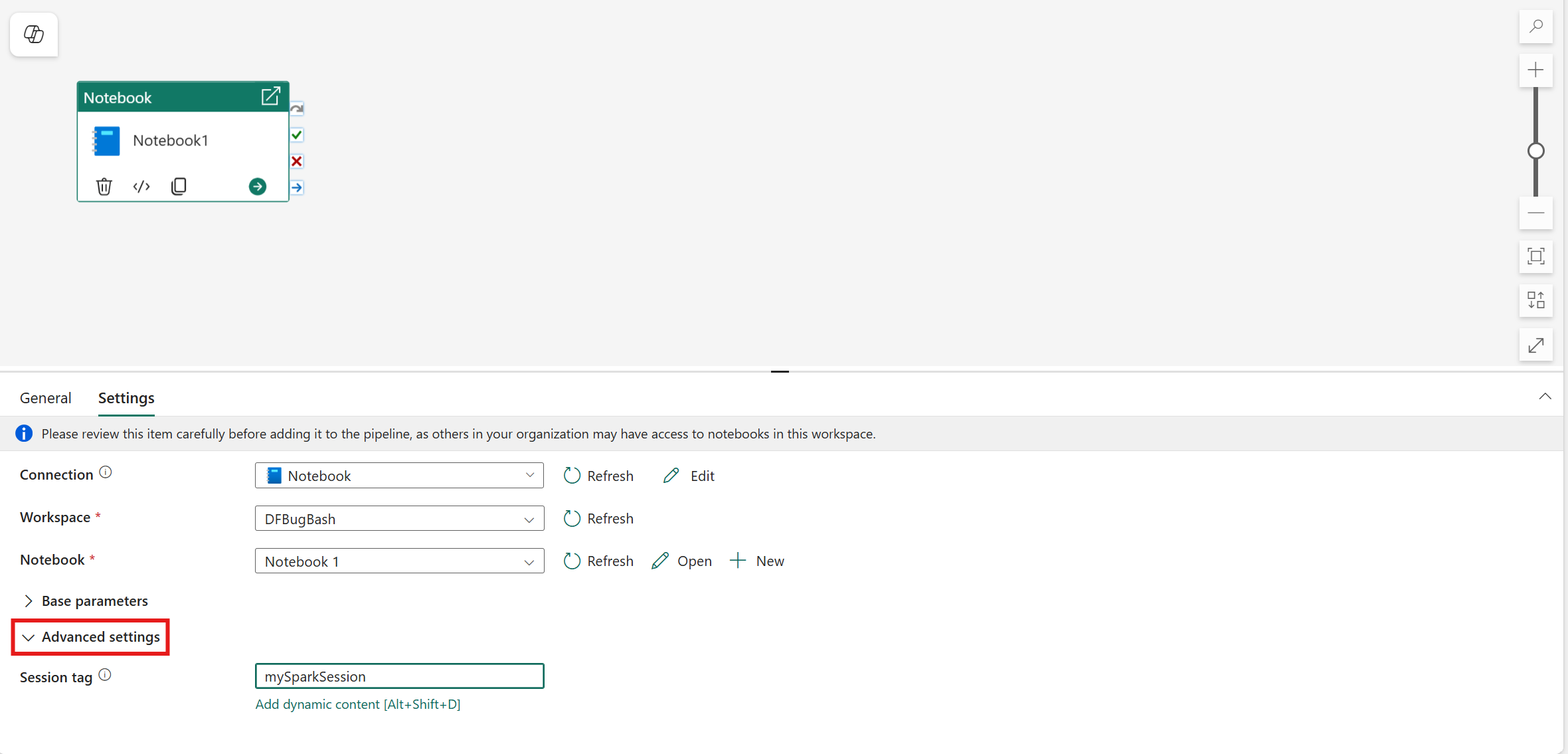
Bemærk
Hvis du vil kunne bruge sessionskoden, skal indstillingen Høj samtidighedstilstand for pipeline, der kører flere notesbøger, være slået til. Denne indstilling kan findes under tilstanden Høj samtidighed for Spark-indstillinger under indstillingerne for arbejdsområdet

Gem og kør eller planlæg pipelinen
Skift til fanen Hjem øverst i pipeline-editoren og vælg gem-knappen for at gemme din pipeline. Vælg Kør for at køre direkte eller Skemalæg for at planlægge løb på bestemte tidspunkter eller intervaller. For mere information om rørledningskørsler, se: planlæg rørledningskørsler.

Efter kørsel kan du overvåge pipeline-udførelsen og se kørselshistorik fra fanen Output under lærredet.
Kendte problemer
- At bruge Service Principal til at køre en notesbog, der indeholder Semantic Link-kode, har funktionelle begrænsninger og understøtter kun et delmængde af semantiske link-funktioner. Se de understøttede semantiske linkfunktioner for detaljer. Hvis du vil bruge andre funktioner, anbefales det manuelt at godkende semantisk link med en tjenesteprincipal.