Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Data Wrangler acceler din dataforberedelsesproces ved at tilbyde en immersiv, visuel grænseflade til udforskende dataanalyse. I denne artikel lærer du, hvordan du:
- Start Data Wrangler fra din Fabric-notebook
- Udforsk data med interaktive visualiseringer og opsummerende statistikker
- Anvend almindelige datarensningsoperationer med automatisk kodegenerering
- Eksporter genanvendelige pandaer eller PySpark-funktioner tilbage til din bærbare computer
Denne artikel fokuserer på pandas DataFrames. For Spark DataFrames, se denne ressource.
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Prøveversion af Microsoft Fabric.
Skift til Fabric ved at bruge experience-switcheren nederst til venstre på din startside.

Begrænsninger
- Brugerdefinerede kodeoperationer understøtter i øjeblikket kun pandas DataFrames.
- Data Wrangler-skærmen fungerer bedst på store skærme. Du kan dog minimere eller skjule forskellige dele af grænsefladen for at få plads til mindre skærme.
Start data-Wrangler
Du kan starte Data Wrangler direkte fra en Microsoft Fabric-notebook for at udforske og transformere pandaer eller Spark DataFrame.
For at komme i gang med eksempeldata:
Dette kodestykke viser, hvordan du læser eksempeldata i en pandas DataFrame:
import pandas as pd
# Read a CSV into a Pandas DataFrame
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv")
display(df)
På notesbogens båndfane "Hjem" skal du bruge rullemenuen Data Wrangler til at gennemse de aktive DataFrames, der er tilgængelige til redigering. Vælg den, du vil åbne i Data Wrangler.
Tip
Du kan ikke åbne Data Wrangler, mens notebook-kernen er optaget. En udførende celle skal afsluttes, før Data Wrangler kan starte, som vist på dette skærmbillede:

Start Data Wrangler fra en celle
Du kan også åbne Data Wrangler direkte fra en notesbogscelle uden at navigere til båndet. Dette indgående indgangspunkt viser Data Wrangler lige der, hvor du arbejder med DataFrames.
Når du kører en celle, der udskriver en DataFrame, vises en Data Wrangler-prompt på celleniveau. Vælg prompten for at åbne den DataFrame i Data Wrangler. Understøttede kommandoer inkluderer:
-
df.head()Ellerdf.head(n) -
df.tail()Ellerdf.tail(n) -
df.show()Ellerdf.show(n)
Kør en celle, der outputter en DataFrame:
import pandas as pd df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") df.head()Efter cellen er færdig med at køre, dukker en Data Wrangler-prompt op på cellen. Vælg Open i Data Wrangler for at starte Data Wrangler med DataFrame.
df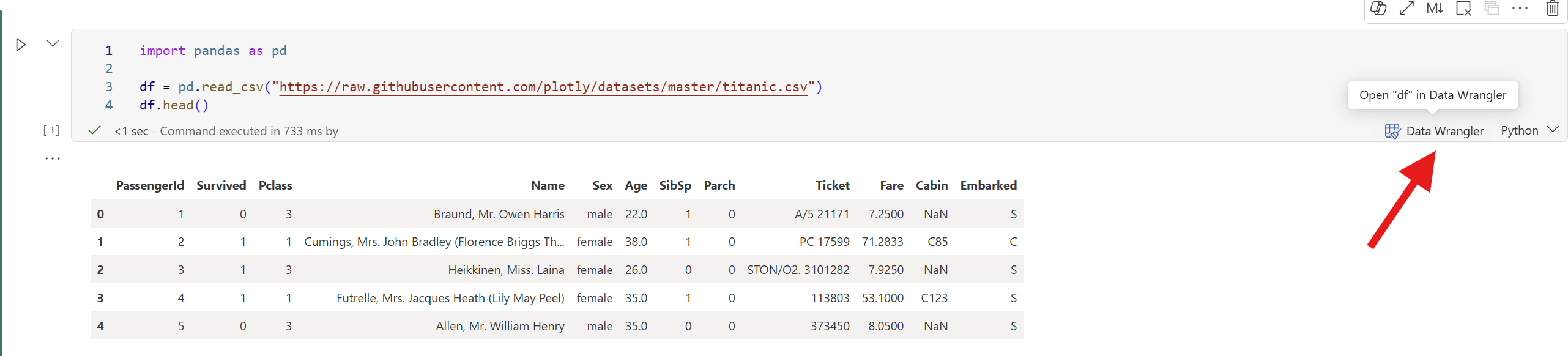

Når en celle definerer flere DataFrames, giver prompten en undermenu, der viser alle DataFrames i cellen. Du kan åbne alle dem i Data Wrangler – selv dem, du ikke eksplicit har printet.
Kør en celle, der definerer flere DataFrames:
import pandas as pd titanic_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/titanic.csv") iris_df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/iris-data.csv") titanic_df.head() iris_df.head()Når cellen er færdig med at køre, vælg Data Wrangler-prompten i cellen. En undermenu viser alle DataFrames defineret i cellen. Vælg den, du vil udforske.
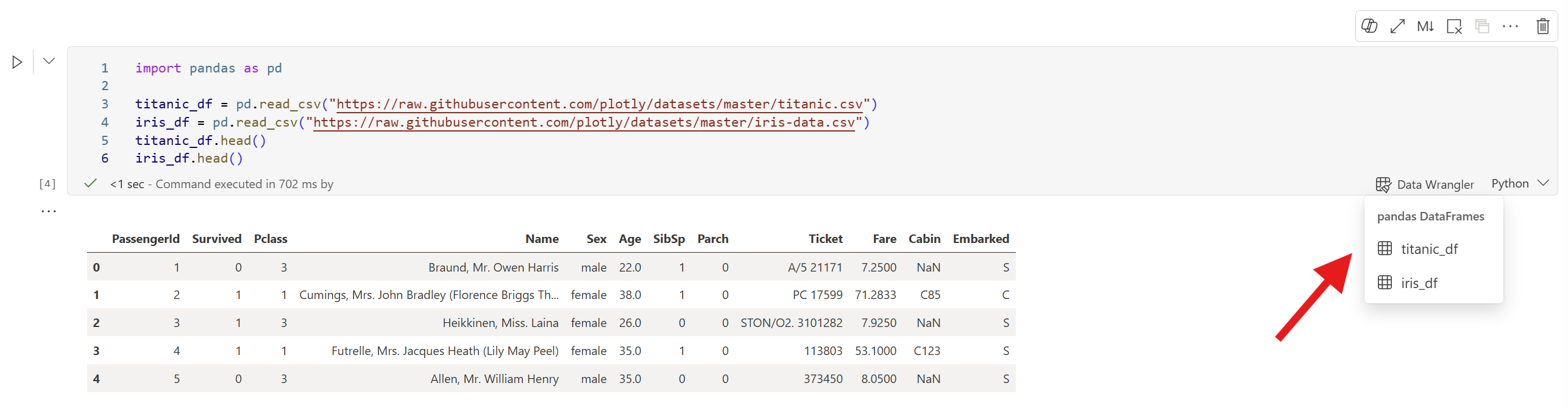

Tip
Undermenuen viser DataFrames defineret i den aktuelle celle. For at åbne en DataFrame fra en tidligere celle, skal du køre en ny celle, der refererer til den—eller bruge Data Wrangler-dropdownmenuen i Home-ribbon-fanen til at gennemse alle aktive DataFrames.
Valg af brugerdefinerede eksempler
For at åbne et brugerdefineret eksempel af en hvilken som helst aktiv DataFrame med Data Wrangler, vælg Vælg brugerdefineret prøve fra dropdown-menuen, som vist på dette screenshot:

Denne handling åbner en dialogboks med indstillinger for at angive størrelsen på den ønskede prøve (antal rækker) og samplingmetoden (første poster, sidste poster eller et tilfældigt sæt). De første 5.000 rækker i DataFrame fungerer som standardeksemplets størrelse, som vist på dette skærmbillede:

Visning af oversigtsstatistik
Når Data Wrangler indlæses, viser den en beskrivende oversigt over den valgte DataFrame i Resumépanelet . Denne oversigt indeholder oplysninger om DataFrame-dimensionerne, manglende værdier og meget mere. Når du vælger en hvilken som helst kolonne i Data Wrangler-gitteret, opdateres Resumépanelet til at vise beskrivende statistikker om den specifikke kolonne. Hurtig indsigt om hver kolonne er også tilgængelig i overskriften.
Tip
Kolonnespecifikke statistikker og visuelle elementer (både i Resume-panelet og i kolonneoverskrifterne) afhænger af kolonnedatatypen. Der vises f.eks. kun et histogram i beholdere med en numerisk kolonne i kolonneoverskriften, hvis kolonnen er angivet som en numerisk type, som vist på dette skærmbillede:

Gennemsyn af handlinger til rensning af data
Operationspanelet giver en søgbar liste over datarensningsoperationer. Når du vælger en datarensningsoperation fra Operations-panelet , skal du angive en målkolonne eller flere målkolonner sammen med eventuelle nødvendige parametre for at fuldføre operationen. Prompten om numerisk skalering af en kolonne kræver f.eks. et nyt interval af værdier, som vist på dette skærmbillede:

Tip
Du kan anvende et mindre udvalg af handlinger i menuen i hver kolonneoverskrift som vist på dette skærmbillede:

Visning og anvendelse af handlinger
Visningsgitteret Data Wrangler viser automatisk resultaterne af en valgt handling, og den tilsvarende kode vises automatisk i panelet under gitteret. For at committe den forhåndsviste kode, vælg Apply i et af lokationerne. For at slette den forhåndsviste kode og prøve en ny operation, vælg Discard, som vist på dette skærmbillede:

Når du anvender en operation, opdateres Data Wrangler-visningsgitteret og oversigtsstatistikker for at afspejle resultaterne. Koden vises i den løbende liste over forpligtede operationer i panelet Rengøringstrin, som vist på dette skærmbillede:

Tip
Du kan altid fortryde det senest anvendte trin. I panelet Rengøringstrin vises et skraldespandsikon, når du holder musepekeren over det senest anvendte trin, som vist på dette screenshot:

I denne tabel opsummeres de handlinger, som Data Wrangler understøtter i øjeblikket:
| Handling | Beskrivelse |
|---|---|
| Sortér | Sortér en kolonne i stigende eller faldende rækkefølge |
| Filter | Filtrer rækker baseret på en eller flere betingelser |
| Kode med én varm kode | Opret nye kolonner for hver entydige værdi i en eksisterende kolonne, der angiver tilstedeværelsen eller fraværet af disse værdier pr. række |
| Binarizer med flere etiketter | Opdel data ved hjælp af en separator, og opret nye kolonner for hver kategori, og marker 1, hvis en række har den pågældende kategori, og 0, hvis den ikke har |
| Skift kolonnetype | Skift datatypen for en kolonne |
| Slip kolonne | Slet en eller flere kolonner |
| Vælg kolonne | Vælg en eller flere kolonner, der skal bevares, og slet resten |
| Omdøb kolonne | Omdøb en kolonne |
| Slip manglende værdier | Fjern rækker med manglende værdier |
| Slip dublerede rækker | Slip alle rækker, der har dublerede værdier i en eller flere kolonner |
| Udfyld manglende værdier | Erstat celler med manglende værdier med en ny værdi |
| Søg og erstat | Erstat celler med et nøjagtigt matchende mønster |
| Gruppér efter kolonne og aggregering | Gruppér efter kolonneværdier, og aggreger resultater |
| Blanktegn i stribe | Fjern mellemrum fra starten og slutningen af teksten |
| Opdel tekst | Opdel en kolonne i flere kolonner baseret på en brugerdefineret afgrænser |
| Konvertér tekst til små bogstaver | Konvertér tekst til små bogstaver |
| Konvertér tekst til store bogstaver | Konvertér tekst til STORE BOGSTAVER |
| Skaler min./maks. værdier | Skaler en numerisk kolonne mellem en minimum- og maksimumværdi |
| Hurtigudfyld | Opret automatisk en ny kolonne baseret på eksempler, der er afledt af en eksisterende kolonne |
Tilpas din skærm
Når som helst kan du tilpasse brugerfladen ved at bruge fanen "Views" i værktøjslinjen over Data Wrangler-skærmgitteret. Denne mulighed kan skjule eller vise forskellige ruder baseret på dine præferencer og skærmstørrelse, som vist på dette skærmbillede:

Gemmer og eksporterer kode
Værktøjslinjen over visningsgitteret Data Wrangler indeholder indstillinger til at gemme den genererede kode. Du kan kopiere koden til udklipsholderen eller eksportere den til notesbogen som en funktion. Eksport af koden lukker Data Wrangler og føjer den nye funktion til en kodecelle i notesbogen. Du kan også downloade den rensede DataFrame som en CSV-fil.
Tip
Data Wrangler genererer kode, der kun kører, når du manuelt kører den nye celle, og den overskriver ikke din oprindelige DataFrame, som vist på dette skærmbillede:

Du kan derefter køre den eksporterede kode som vist på dette skærmbillede:

Næste trin
Nu hvor du ved, hvordan du bruger Data Wrangler med pandas DataFrames, kan du udforske disse ressourcer:
- Brug Data Wrangler med Spark DataFrames - Anvend de samme teknikker til Spark DataFrames
- Se en live-demo - Se Data Wrangler i aktion med Guy in a Cube
- Prøv Data Wrangler i VS Code - Brug Data Wrangler i Visual Studio Code
Har du feedback? Del dine idéer i Fabric Ideas-forummet.