Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Denne opskrift viser, hvordan man bruger SynapseML og Foundry Tools på Apache Spark til detektion af multivariate anomalier. Multivariat anomalidetektion involverer påvisning af anomalier blandt mange variabler eller tidsserier, samtidig med at der tages højde for alle indbyrdes korrelationer og afhængigheder mellem de forskellige variabler. Dette scenarie bruger SynapseML og Foundry Tools til at træne en model til detektion af multivariate anomalier. Du bruger derefter modellen til at udlede multivariate anomalier i et datasæt, der indeholder syntetiske målinger fra tre IoT-sensorer.
Vigtigt
Fra den 20. september 2023 kan du ikke længere oprette nye Anomaly Detector-ressourcer. Anomaly Detector-tjenesten går ud af drift den 1. oktober 2026.
For mere information om Azure AI Anomaly Detector, besøg informationsressourcen Anomaly Detector.
Forudsætninger
- Et Azure-abonnement - Opret et gratis
- Vedhæft din notesbog til et lakehouse. I venstre side skal du vælge Tilføj for at tilføje et eksisterende lakehouse eller oprette et lakehouse.
Opsætte
Med udgangspunkt i en eksisterende Anomaly Detector ressource kan du undersøge måder at håndtere data i forskellige former på.
Opret en Afvigelsesregistrering ressource
Bemærkning
Siden den 20. september 2023 kan du ikke oprette nye Anomaly Detector-ressourcer. Følgende trin gælder kun, hvis du har en eksisterende Anomaly Detector-ressource. For en multivariat anomali-detektionsmetode, der ikke kræver Anomaly Detector-tjenesten, se Multivariat Anomaly Detection with Isolation Forest.
- I Azure-portalen vælger du Create i din ressourcegruppe, og skriver derefter Anomaly Detector. Vælg den Afvigelsesregistrering ressource.
- Navngiv ressourcen, og brug ideelt set det samme område som resten af ressourcegruppen. Brug standardindstillingerne for resten, og vælg derefter Gennemse + Opret og derefter Opret.
- Når du har oprettet ressourcen Afvigelsesregistrering, skal du åbne den og vælge
Keys and Endpointspanelet i venstre navigationsrude. Kopiér nøglen for den Afvigelsesregistrering ressource til miljøvariablenANOMALY_API_KEY, eller gem den i variablenanomalyKey.
Opret en lagerkontoressource
For at gemme mellemliggende data skal du oprette en Azure Blob Storage-konto. Inden for denne lagerkonto skal du oprette en objektbeholder til lagring af de mellemliggende data. Notér containerens navn, og kopier connection string til den container. Du skal bruge den til senere at udfylde variablen containerName og miljøvariablen BLOB_CONNECTION_STRING .
Angiv dine servicenøgler
Først skal du opsætte miljøvariablerne for dine servicenøgler. Den næste celle sætter miljøvariablerne ANOMALY_API_KEY og BLOB_CONNECTION_STRING baseret på de værdier, der er gemt i Azure Key Vault. Hvis du kører dette selvstudium i dit eget miljø, skal du sørge for at angive disse miljøvariabler, før du fortsætter:
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Læs variablerne ANOMALY_API_KEY og BLOB_CONNECTION_STRING miljø, og indstil variablerne containerName og location :
# An Anomaly Detector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Forbind til lagringskontoen, så anomalidetektoren kan gemme mellemliggende resultater i den lagringskonto:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Importer alle de nødvendige moduler:
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.services import *
Læs eksempeldataene i en Spark DataFrame:
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Du kan nu oprette et estimator objekt, som du bruger til at træne din model. Angiv start- og sluttidspunkterne for træningsdataene. Angiv også de inputkolonner, der skal bruges, samt navnet på kolonnen, der indeholder tidsstemplerne. Til sidst angiv antallet af datapunkter, der skal bruges i anomali-detektionsvinduet, og sæt connection string til Azure Blob Storage Account:
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Sæt dataene estimator sammen:
model = estimator.fit(df)
Når træningen er færdig, brug modellen til slutning. Koden i næste celle angiver start- og sluttidspunkterne for de data, hvor du ønsker at opdage anomalier:
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
I den forrige celle .show(5) vises de første fem dataframe-rækker. Resultaterne skyldes alle null , at de lander uden for slutningsvinduet.
Hvis du kun vil have vist resultaterne for de udledte data, skal du vælge de nødvendige kolonner. Du kan derefter ordne rækkerne i datarammen efter stigende rækkefølge og filtrere resultatet, så kun rækkerne i inferensvinduets område vises. Her inferenceEndTime matcher den sidste række i dataframen, så du kan ignorere den.
Til sidst, for bedre at afbilde resultaterne, skal du konvertere Spark-datarammen til en Pandas-dataramme:
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
Formatér den contributors kolonne, der gemmer bidragsscoren fra hver sensor, til de registrerede uregelmæssigheder. Den næste celle håndterer dette og opdeler bidragsscoren for hver sensor i sin egen kolonne:
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Du har nu bidragsscorerne for sensorerne 1, 2 og 3 i series_0henholdsvis , series_1, og series_2 kolonnerne.
Hvis du vil plotte resultaterne, skal du køre den næste celle. Parameteren minSeverity angiver den mindste alvorsgrad af de uregelmæssigheder, der skal plottes:
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
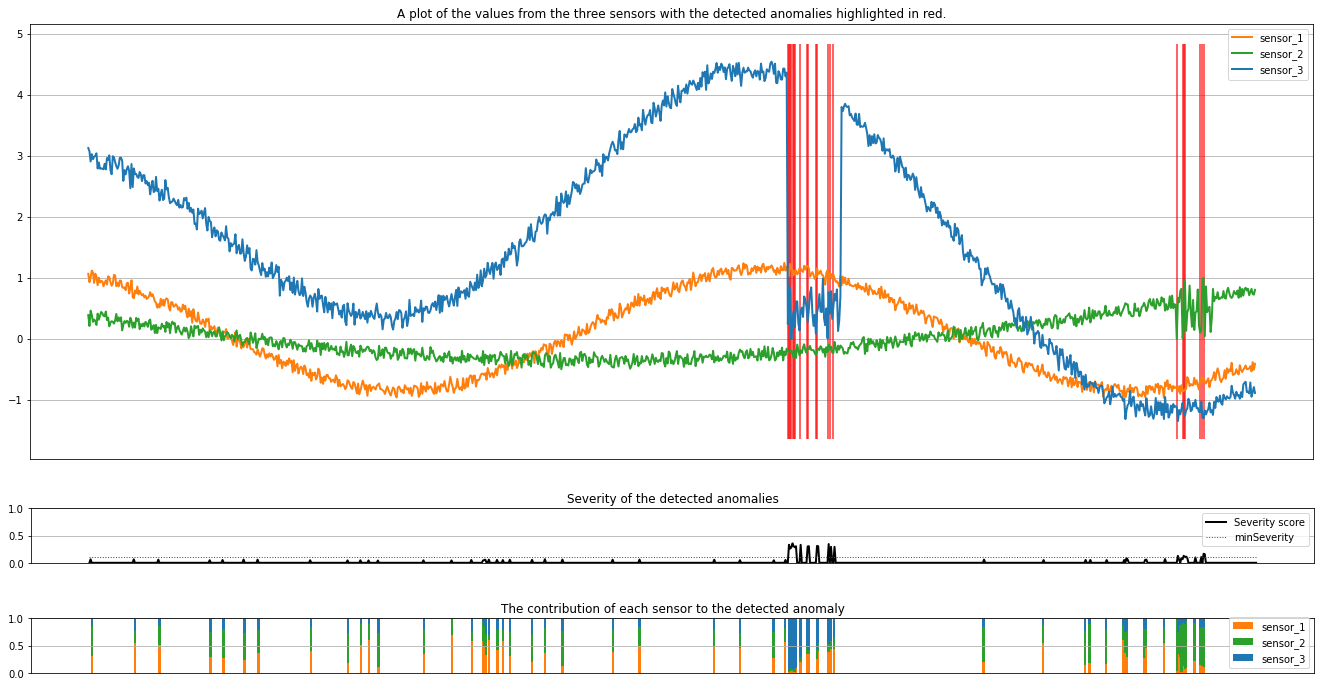
Afbildningerne viser rådata fra sensorerne (inde i inferensvinduet) i orange, grøn og blå. De røde lodrette linjer i det første tal viser de registrerede uregelmæssigheder, der har en alvorsgrad, der er større end eller lig med minSeverity.
I det andet afbildning vises alvorsgradsscoren for alle de registrerede uregelmæssigheder, hvor minSeverity tærsklen vises på den stiplede røde linje.
Endelig viser det sidste plot bidraget fra dataene fra hver sensor til de registrerede uregelmæssigheder. Det hjælper med at diagnosticere og forstå den mest sandsynlige årsag til hver afvigelse.
Relateret indhold
- Multivariat Anomali-detektion med Isolation Forest – kræver ikke en Azure AI Anomaly Detector ressource.
- Sådan bruger du LightGBM med SynapseML
- Sådan bruger du Foundry Tools med SynapseML
- Sådan bruger du SynapseML til at justere hyperparametre