Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
I denne artikel lærer du, hvordan du udfører udforskningsdataanalyser ved hjælp af Azure Open Datasets og Apache Spark. I denne artikel analyseres taxadatasættet i New York City. Dataene er tilgængelige via Azure Open Datasets. Dette undersæt af datasættet indeholder oplysninger om gule taxature: oplysninger om hver tur, start- og sluttidspunkt og placeringer, omkostninger og andre interessante attributter.
I denne artikel kan du:
- Download og forbered data
- Analysér data
- Visualiser data
Forudsætninger
Få et Microsoft Fabric-abonnement. Du kan også tilmelde dig en gratis Prøveversion af Microsoft Fabric.
Skift til Fabric ved at bruge experience-switcheren nederst til venstre på din startside.

Download og forbered dataene
For at starte skal du downloade datasættet New York City (NYC) Taxi og forberede dataene.
Opret en notesbog ved hjælp af PySpark. Du kan finde en vejledning under Opret en notesbog.
Bemærk
På grund af PySpark-kernen behøver du ikke at oprette nogen kontekster eksplicit. Spark-konteksten oprettes automatisk for dig, når du kører den første kodecelle.
I denne artikel kan du bruge flere forskellige biblioteker til at visualisere datasættet. Hvis du vil udføre denne analyse, skal du importere følgende biblioteker:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdDa rådata er i Parquet-format, kan du bruge Spark-konteksten til at trække filen til hukommelsen som en DataFrame direkte. Brug API'en Open Datasets til at hente dataene og oprette en Spark DataFrame. Hvis du vil udlede datatyperne og skemaet, skal du bruge Spark DataFrame-skemaet på læseegenskaber .
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Når dataene er læst, skal du foretage en indledende filtrering for at rense datasættet. Du kan fjerne unødvendige kolonner og tilføje kolonner, der udtrækker vigtige oplysninger. Derudover kan du filtrere uregelmæssigheder i datasættet fra.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Analysér data
Som dataanalytiker har du en lang række værktøjer, der kan hjælpe dig med at udtrække indsigt fra dataene. I denne del af artiklen kan du få mere at vide om nogle nyttige værktøjer, der er tilgængelige i Microsoft Fabric-notesbøger. I denne analyse vil du gerne forstå de faktorer, der giver højere taxatips for den valgte periode.
Apache Spark SQL Magic
Først skal du foretage udforskende dataanalyser ved hjælp af Apache Spark SQL og magiske kommandoer med Microsoft Fabric-notesbogen. Når du har forespørgslen, kan du visualisere resultaterne ved hjælp af den indbyggede chart options funktion.
Opret en ny celle i notesbogen, og kopiér følgende kode. Ved hjælp af denne forespørgsel kan du forstå, hvordan de gennemsnitlige tipbeløb ændres i den valgte periode. Denne forespørgsel hjælper dig også med at identificere andre nyttige indsigter, herunder minimum-/maksimumbeløb pr. dag og det gennemsnitlige prisbeløb.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCNår din forespørgsel er færdig med at køre, kan du visualisere resultaterne ved at skifte til diagramvisningen. I dette eksempel oprettes et kurvediagram ved at angive feltet
day_of_monthsom nøglen ogavgTipAmountsom værdien. Når du har foretaget valgene, skal du vælge Anvend for at opdatere diagrammet.
Visualiser data
Ud over de indbyggede indstillinger for notesbøger kan du bruge populære biblioteker med åben kildekode til at oprette dine egne visualiseringer. I følgende eksempler skal du bruge Seaborn og Matplotlib, som ofte bruges Python-biblioteker til datavisualisering.
Hvis du vil gøre udvikling nemmere og billigere, skal du nedsample datasættet. Brug den indbyggede funktion Apache Spark-sampling. Desuden kræver både Seaborn og Matplotlib en Pandas DataFrame- eller NumPy-matrix. Hvis du vil hente en Pandas DataFrame, skal du bruge kommandoen
toPandas()til at konvertere DataFrame.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Du kan forstå distributionen af tip i datasættet. Brug Matplotlib til at oprette et histogram, der viser fordelingen af tipmængden og antallet. Baseret på fordelingen kan du se, at tip er skæve i forhold til beløb, der er mindre end eller lig med $10.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()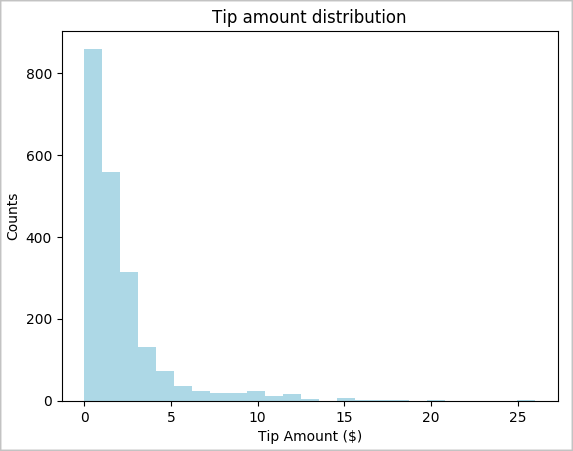
Prøv derefter at forstå relationen mellem tipsene til en given tur og ugedagen. Brug Seaborn til at oprette en feltafbildning, der opsummerer tendenserne for hver dag i ugen.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()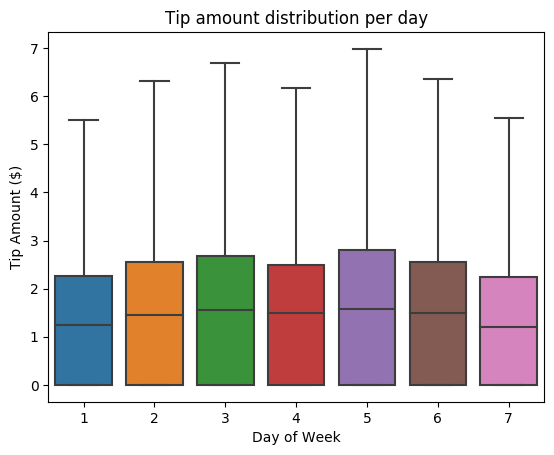
En anden hypotese kan være, at der er et positivt forhold mellem antallet af passagerer og det samlede taxatipbeløb. Hvis du vil bekræfte denne relation, skal du køre følgende kode for at generere en feltafbildning, der illustrerer fordelingen af tip for hvert passagerantal.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()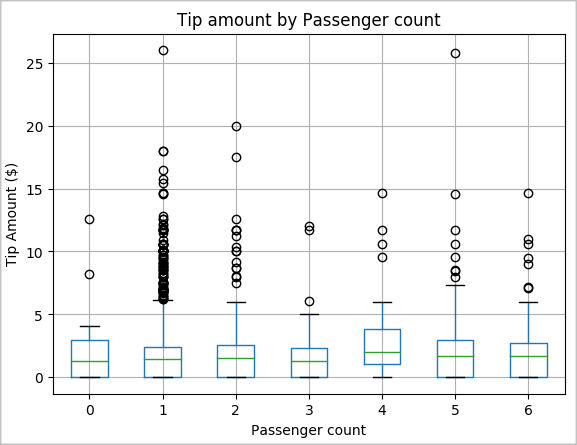
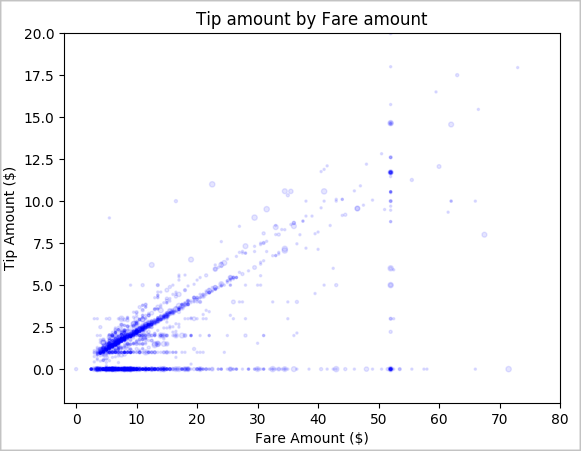
Sidst skal du udforske relationen mellem takstbeløbet og tipbeløbet. På baggrund af resultaterne kan du se, at der er flere observationer, hvor folk ikke giver tip. Der er dog et positivt forhold mellem den samlede pris og drikkepengebeløbene.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()