Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅ SQL Analytics-slutpunkt og warehouse i Microsoft Fabric
Hentning af data fra datasøen er en vigtig input-/outputhandling (IO), der har betydelige konsekvenser for forespørgslens ydeevne. Fabric Data Warehouse anvender raffinerede adgangsmønstre for at forbedre datalæsninger fra lageret og øge hastigheden for udførelse af forespørgsler. Derudover minimerer det intelligent behovet for læsning af fjernlager ved at udnytte lokale cachelagre.
Cachelagring er en teknik, der forbedrer ydeevnen af databehandlingsprogrammer ved at reducere IO-handlingerne. Cachelagring gemmer ofte tilgåede data og metadata i et hurtigere lagerlag, f.eks. lokal hukommelse eller lokal SSD-disk, så efterfølgende anmodninger kan behandles hurtigere direkte fra cachen. Hvis en forespørgsel tidligere har fået adgang til et bestemt datasæt, henter eventuelle efterfølgende forespørgsler disse data direkte fra cachen i hukommelsen. Denne fremgangsmåde reducerer IO-ventetiden betydeligt, da lokale hukommelseshandlinger især er hurtigere sammenlignet med hentning af data fra fjernlageret.
Brugeren har fuld gennemsigtighed i hukommelsen og cachelagring af disken i Fabric Data Warehouse. Uanset oprindelsen, uanset om det er en lagertabel, en OneLake-genvej eller endda OneLake-genvej, der refererer til ikke-Azure-tjenester, cachelagrer forespørgslen alle de data, den har adgang til.
Der er to typer cacher, der beskrives senere i denne artikel, cachen i hukommelsen og diskcachen. Cachelagring af resultatsæt er beskrevet i en anden artikel.
Cache i hukommelsen
I takt med at forespørgslen tilgår og henter data fra lageret, udfører den en transformationsproces, der omkoder dataene fra det oprindelige filbaserede format til stærkt optimerede strukturer i cachen i hukommelsen.

Data i cachen er organiseret i et komprimeret kolonneformat, der er optimeret til analytiske forespørgsler. Hver kolonne med data gemmes sammen, adskilt fra de andre, hvilket giver mulighed for bedre komprimering, da lignende dataværdier gemmes sammen, hvilket medfører reduceret hukommelsesforbrug. Når forespørgsler skal udføre handlinger på en bestemt kolonne, f.eks. aggregeringer eller filtrering, kan programmet arbejde mere effektivt, da det ikke behøver at behandle unødvendige data fra andre kolonner.
Derudover er dette kolonnelager også velegnet til parallel behandling, hvilket kan fremskynde udførelsen af forespørgsler betydeligt for store datasæt. Programmet kan udføre handlinger på flere kolonner samtidigt og drage fordel af moderne processorer med flere kerner.
Denne fremgangsmåde er især nyttig for analytiske arbejdsbelastninger, hvor forespørgsler omfatter scanning af store mængder data for at udføre sammenlægninger, filtrering og andre datamanipulationer.
Diskcache
Visse datasæt er for store til at kunne imødekommes i en cache i hukommelsen. Warehouse bruger diskplads som en supplerende udvidelse til cachen i hukommelsen for at opretholde en hurtig forespørgselsydeevne for disse datasæt. Alle oplysninger, der indlæses i cachen i hukommelsen, serialiseres også til SSD-cachen.
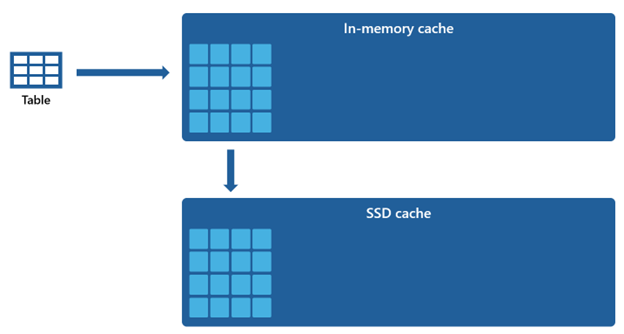
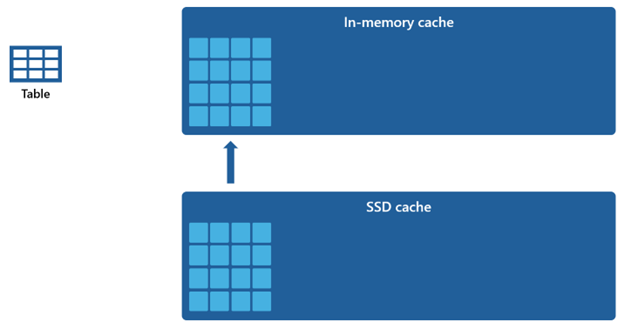
Da cachen i hukommelsen har en mindre kapacitet sammenlignet med SSD-cachen, forbliver data, der fjernes fra cachen i hukommelsen, i SSD-cachen i en længere periode. Når efterfølgende forespørgsler anmoder om disse data, hentes de fra SSD-cachen til cachen i hukommelsen betydeligt hurtigere, end hvis de hentes fra fjernlageret, hvilket i sidste ende giver dig en mere ensartet forespørgselsydeevne.
Cachestyring
Cachelagring forbliver konstant aktiv og fungerer problemfrit i baggrunden, hvilket kræver ingen indgriben fra din side. Deaktivering af cachelagring er ikke nødvendig, da det uundgåeligt vil medføre en mærkbar forringelse af forespørgslens ydeevne.
Cachelagringsmekanismen organiseres og opretholdes af selve Microsoft Fabric, og den giver ikke brugerne mulighed for manuelt at rydde cachen.
Fuld transaktionskonsistens i cachen sikrer, at alle ændringer af dataene i lageret, f.eks. via DML-handlinger (Data Manipulation Language), efter at de først er indlæst i cachen i hukommelsen, resulterer i ensartede data.
Når cachen når sin kapacitetsgrænse, og nye data læses for første gang, fjernes objekter, der ikke er blevet brugt i den længste periode, fra cachen. Denne proces er vedtaget for at skabe plads til tilstrømningen af nye data og opretholde en optimal cacheudnyttelsesstrategi.