Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for: ✅ SQL analytics endpoint og Warehouse i Microsoft Fabric
Brugerdefinerede SQL-puljer giver administratorer mere kontrol over, hvordan ressourcer tildeles til at håndtere forespørgsler. I denne quickstart konfigurerer du brugerdefinerede SQL-pools og observerer klassifikatorværdierne ved hjælp af Fabric REST API'en.
Workspace-administratorer kan bruge applikationsnavnet (eller programnavnet) fra forbindelsesstrengen til at dirigere anmodninger til forskellige compute pools. Workspace-administratorer kan også styre procentdelen af ressourcer, som hver compute SQL-pool kan tilgå, baseret på den burstable skaleringsgrænse for arbejdsområdets kapacitet.
Fabric REST API definerer et samlet endpoint til operationer.
Forudsætninger
- Adgang til en lagervare i et arbejdsområde. Du bør være medlem af administratorrollen.
Få den nuværende konfiguration
Brug følgende API for at få den aktuelle konfiguration.
Eksempel på stofnotesbog
Du kan køre følgende eksempel på Python-kode i en Fabric Spark-notesbog.
- Koden sender en
GETanmodning til det brugerdefinerede SQL pool konfigurations-API og returnerer den tilpassede SQL-pool konfiguration for arbejdsområdet. - Feltet
workspace_idbruger detmssparkutils.runtime.contexttil at få den workspace GUID, som notebooken kører i. For at konfigurere en brugerdefineret SQL-pool i et andet arbejdsområde, opdater tilworkspace_idGUID'en for det arbejdsområde, hvor du vil konfigurere de brugerdefinerede SQL-pools.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Konfigurer brugerdefinerede SQL-pools
Følgende Python-eksempel muliggør og konfigurerer brugerdefinerede SQL-puljer. Du kan køre denne Python-kode i en Fabric Spark-notebook.
- Den tilpassede SQL-poolkonfiguration er kun aktiv, når
customSQLPoolsEnabledattributten er sat til true. Du kan definere en payload icustomSQLPoolsobjektdefinitionen, men hvis du ikke sætter customSQLPoolsEnabled til true, ignoreres payloaden, og autonom workload management anvendes. - Koden konfigurerer to brugerdefinerede SQL-puljer,
ContosoSQLPoologAdhocPool.- Den
ContosoSQLPoolforventes at modtage 70% af de tilgængelige ressourcer. Applikationsnavn-klassifikatoren har værdien afMyContosoApp. - Alle SQL-forespørgsler, der kommer fra en forbindelsesstreng, der angiver applikationsnavnet
MyContosoApp, klassificeres i den brugerdefineredeContosoSQLPoolSQL-pool og har adgang til 70% af de samlede noder med burstbar kapacitet. - Alle SQL-forespørgsler, der ikke indeholder
MyContosoAppapplikationsnavnet på forbindelsesstrengen, sendes til denAdhocbrugerdefinerede SQL-pool, som er defineret som standardpoolen. Disse anmodninger får adgang til 30% af de samlede noder med burstbar kapacitet.
- Den
- Alle brugerdefinerede SQL pool-konfigurationer skal have én standard SQL Pool, identificeret ved at sætte attributten
isDefaulttil true. - Summen af alle
maxResourcePercentageværdier skal være mindre end eller lig med 100%. - Feltet
workspace_idbruger detmssparkutils.runtime.contexttil at få den workspace GUID, som notebooken kører i. For at konfigurere en brugerdefineret SQL-pool i et andet arbejdsområde, opdater tilworkspace_idGUID'en for det arbejdsområde, hvor du vil konfigurere de brugerdefinerede SQL-pools.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Tips
Brug disse nyttige Application Name (regex) klassifikatorværdier til trafik fra Fabric:
- For at klassificere forespørgsler fra Fabric-pipelines, brug
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - For at klassificere forespørgsler fra Power BI, brug
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). - For at klassificere forespørgsler fra Fabric portalens SQL-forespørgselseditor, brug
DMS_user.
Sæt applikationsnavnet i SQL Server Management Studio (SSMS)
Klassifikatoren for brugerdefinerede SQL-puljer bruger applikationsnavnet eller programnavnets parameter for almindelige forbindelsesstrenge.
I SQL Server Management Studio (SSMS) skal du angive servernavnet for lageret og give autentificering. Microsoft Entra MFA anbefales.
Vælg knappen Avanceret .
På siden Avancerede Egenskaber , under Kontekst, skal værdien af applikationsnavn ændres til
MyContosoApp.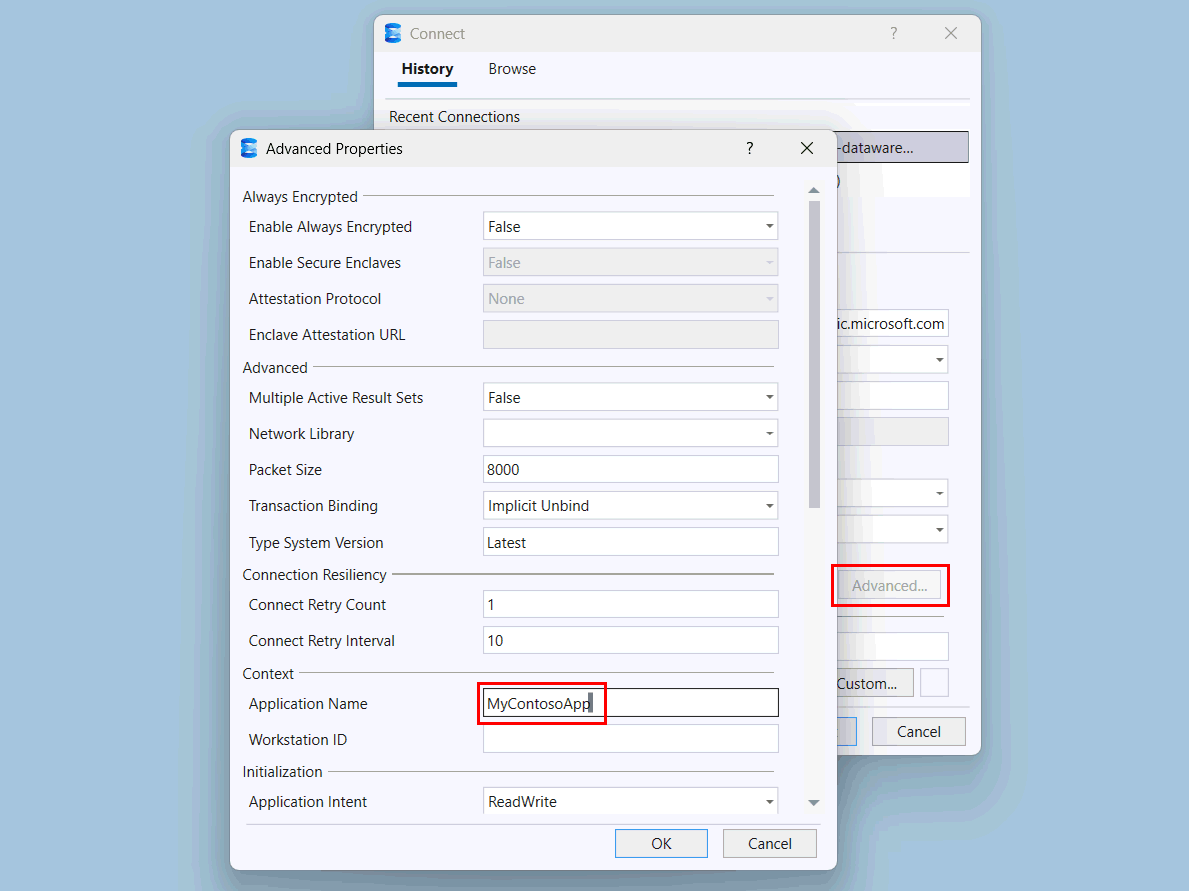
Vælg OK.
Vælg Opret forbindelse.
For at generere noget eksempelaktivitet kan du bruge denne forbindelse i SSMS til at køre en simpel forespørgsel i dit lager, for eksempel:
SELECT * FROM dbo.DimDate;

Observer forespørgselsindsigter for den tilpassede SQL-pool
Gennemgå den dynamiske
sys.dm_exec_sessionsadministrationsvisning for at se, at det bliver genkendt som applikationsnavnet,MyContosoAppder sendes fra SSMS til SQL-motoren.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Eksempel:
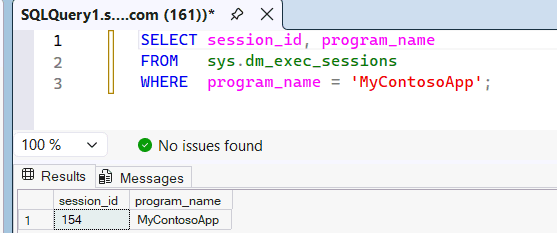
Fordi den
program_namematcher applikationsnavnet i den brugerdefineredeMyContosoAppSQL-pool, bruger denne forespørgsel ressourcerne i den pool. For at bevise, hvilken custom SQL-pool forespørgslen brugte, kan du forespørge i queryinsights.exec_requests_history systemvisning. Vent 10-15 minutter på, at query insights bliver udfyldt, og kør derefter den følgende forespørgsel.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';Du kan også identificere poolen af en forespørgsel ud fra dens Statement ID. I Fabric-portalens SQL-forespørgselseditor skal du køre en forespørgsel mod dit lager eller SQL-analyse-endpoint.
SELECT * FROM dbo.DimDate;Vælg fanen Beskeder og registrer Statement-ID'et for forespørgselsudførelsen. I SQL-forespørgselseditoren er
program_name,DMS_usersom du tidligere konfigurerede til at bruge den brugerdefineredeMyContosoAppSQL-pool.Vent 10-15 minutter på, at query insights bliver udfyldt.
Hent
sql_pool_nameog anden information for at verificere, at den korrekte brugerdefinerede SQL-pool er blevet brugt.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Tilbagefør konfigurationen af brugerdefinerede SQL-pools
For at bringe arbejdsområdet tilbage til den oprindelige tilstand, skift egenskaben customSQLPoolsEnabled til False. Hvis du vil bevare den brugerdefinerede SQL-poolkonfiguration, skal du indtaste hvert poolnavn som i customSQLPools listen.
Dette eksempel Python-kode deaktiverer brugerdefinerede SQL-pools og går tilbage til den autonome workload management-konfiguration af SELECT og ikke-poolsSELECT . En anmodning kaldes med egenskaben PATCHcustomSQLPoolsEnabled sat til False.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)