Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅ Warehouse i Microsoft Fabric
Vigtigt!
Denne funktion er i prøveversion.
Surrogatnøgler er identifikatorer, der bruges i datalager til unikt at skelne rækker, uafhængigt af deres naturlige nøgler. I Fabric Data Warehouse muliggør kolonner automatisk generering af disse surrogatnøgler, IDENTITY når nye rækker indsættes i en tabel. Denne artikel forklarer, hvordan man bruger IDENTITY kolonner i Fabric Data Warehouse til effektivt at oprette og administrere surrogatnøgler.
Hvorfor bruge en IDENTITET-kolonne?
IDENTITY Kolonner eliminerer behovet for manuel nøglefordeling, hvilket reducerer risikoen for fejl og forenkler dataindlæsningen. Systemadministrerede unikke værdier er ideelle som surrogatnøgler og primærnøgler. Sammenlignet med manuelle tilgange til at producere surrogatnøgler tilbyder kolonner overlegen ydeevne, IDENTITY da unikke nøgler genereres automatisk uden ekstra logik på forespørgsler.
Biggint-datatypen, som kræves for IDENTITY kolonner, kan gemme op til 9.223.372.036.854.775.807 positive heltalsværdier, hvilket sikrer, at hver række i en tabels levetid modtager en unik værdi i sin IDENTITY kolonne.
For en plan om at migrere data med surrogatnøgler fra andre databaseplatforme, se Migrate IDENTITY-kolonner til Fabric Data Warehouse.
Syntaks
For at definere en IDENTITY kolonne i Fabric Data Warehouse bruges egenskaben IDENTITY sammen med den ønskede kolonne. Syntaksen er som følger:
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
[column_name] BIGINT IDENTITY,
[ ,... n ]
-- Other columns here
);
Hvordan IDENTITY-kolonner fungerer
Inden for Fabric Data Warehouse kan du ikke angive en brugerdefineret startværdi eller inkrement; Systemet administrerer værdierne internt for at sikre unikhed.
IDENTITY kolonner producerer altid positive heltalsværdier. Hver ny række modtager en ny værdi, og entydighed er garanteret, så længe tabellen eksisterer. Når en værdi er brugt, IDENTITY bruges den ikke den samme værdi igen, hvilket bevarer både nøgleintegritet og entykhed. Huller kan opstå på værdier, som kolonnen IDENTITY producerer.
Fordeling af værdier
På grund af warehouse-motorens distribuerede arkitektur garanterer egenskaben IDENTITY ikke rækkefølgen, hvori surrogatværdierne allokeres. Egenskaben IDENTITY er designet til at skalere ud på tværs af beregningsnoder for at maksimere parallelisme, uden at påvirke belastningsydelsen. Som følge heraf kan værdiintervaller på forskellige indtagelsesopgaver have forskellige sekvensintervaller.
For at illustrere denne adfærd, overvej følgende eksempel:
-- Create a table with an IDENTITY column
CREATE TABLE dbo.T1(
C1 BIGINT IDENTITY,
C2 VARCHAR(30) NULL
)
-- Ingestion task A
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Ingestion task B
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Reviewing the data
SELECT * FROM dbo.T1;
Eksempelresultat:
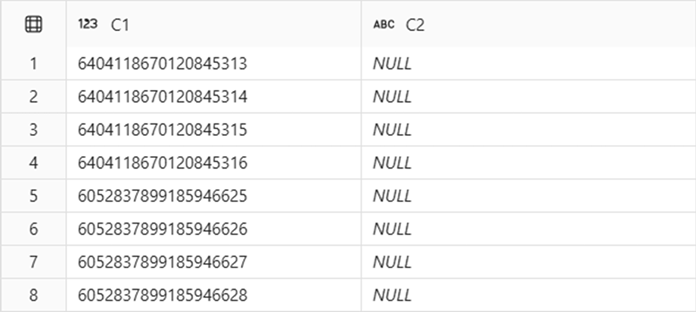
I dette eksempel Ingestion task A udføres og Ingestion task B sekventielt som uafhængige opgaver. Selvom opgaverne kørte i løbet af hinanden, har den første og de sidste fire rækker forskellige identitetsnøgleintervaller i dbo.T1.C1. Derudover kan derudover, som observeret i dette eksempel, opstå huller mellem de intervaller, der er tildelt opgave A og opgave B.
IDENTITY i Fabric Data Warehouse garanteres, at alle værdier i en IDENTITY kolonne er unikke, men der kan være huller i de intervaller, der produceres for en given indlæsningsopgave.
Systemvisninger
sys.identity_columns katalogvisning kan bruges til at liste alle identitetskolonner på et lager. Følgende eksempel viser alle tabeller, der indeholder en IDENTITY kolonne i deres definition, med deres respektive skemanavn og navnet på kolonnen IDENTITY i den tabel:
SELECT
s.name AS SchemaName,
t.name AS TableName,
c.name AS IdentityColumnName
FROM
sys.identity_columns AS ic
INNER JOIN
sys.columns AS c ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN
sys.tables AS t ON ic.[object_id] = t.[object_id]
INNER JOIN
sys.schemas AS s ON t.[schema_id] = s.[schema_id]
ORDER BY
s.name, t.name;
Limitations
- Kun bigint-datatypen understøttes for
IDENTITYkolonner i Fabric Data Warehouse. Forsøg på at bruge andre datatyper resulterer i en fejl. -
IDENTITY_INSERTunderstøttes ikke i Fabric Data Warehouse. Brugere kan ikke opdatere eller manuelt indsætte kolonneværdier på identitetskolonner i Fabric Data Warehouse. - At definere a
seedogincrementunderstøttes ikke. Som følge heraf understøttes det ikke at genseede kolonnenIDENTITY. - At tilføje en ny
IDENTITYkolonne til en eksisterende tabel medALTER TABLEunderstøttes ikke. Overvej at bruge CREATE TABLE AS SELECT (CTAS) eller SELECT... INTO som alternativer til at oprette en kopi af en eksisterende tabel, der tilføjer enIDENTITYkolonne til sin definition. - Nogle begrænsninger gælder, hvordan
IDENTITYkolonner bevares, når en ny tabel oprettes som følge af et udvælgelse fra en anden tabel medCREATE TABLE AS SELECT (CTAS)ellerSELECT... INTO. For mere information, se afsnittet Data Types i SELECT - INTO Clause (Transact-SQL).
Eksempler
A. Opret en tabel med en IDENTITY-kolonne
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Denne sætning opretter en Employees-tabel, hvor hver ny række automatisk modtager en unik EmployeeID værdi som bigint .
B. INSERT på en tabel med en identitetskolonne
Når den første kolonne er en IDENTITY kolonne, behøver du ikke angive den i kolonnelisten.
INSERT INTO Employees (FirstName, LastName) VALUES ('Ensi','Vasala')
Det er også muligt at udsende kolonnenavnene, hvis værdier er angivet for alle kolonner i destinationstabellen (undtagen identitetskolonnen):
INSERT INTO Employees VALUES ('Quarantino', 'Esposito')
C. Opret en ny tabel med en IDENTITY-kolonne ved hjælp af CREATE TABLE AS SELECT (CTAS)
Betragter vi en simpel tabel som eksempel:
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Vi kan bruge CREATE TABLE AS SELECT (CTAS) til at oprette en kopi af denne tabel og bevare egenskaben IDENTITY i måltabellen:
CREATE TABLE RetiredEmployees
AS SELECT * FROM Employees
Kolonnen i måltabellen arver egenskaben IDENTITY fra kildetabellen. For en liste over begrænsninger, der gælder for dette scenarie, henvises til afsnittet Data Types i SELECT - INTO Clause.
D. Opret en ny tabel med en IDENTITY-kolonne ved hjælp af SELECT... I
Betragter vi en simpel tabel som eksempel:
CREATE TABLE dbo.Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Retired BIT
);
Vi kan bruge SELECT... INTO til at oprette en kopi af denne tabel og bevare egenskaben IDENTITY i måltabellen:
SELECT *
INTO dbo.RetiredEmployees
FROM dbo.Employees
WHERE Retired = 1;
Kolonnen i måltabellen arver egenskaben IDENTITY fra kildetabellen. For en liste over begrænsninger, der gælder for dette scenarie, henvises til afsnittet Data Types i SELECT - INTO Clause.