Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Gælder for:✅SQL-database i Microsoft Fabric
Fabric Dataflow Gen2 giver dig mulighed for at transformere data, mens du flytter dem. Denne artikel er en hurtig retning til brug af dataflow med SQL-database i Fabric, en af flere muligheder for at kopiere data fra kilde til kilde. Hvis du vil sammenligne indstillinger, skal du se Microsoft Fabric-beslutningsvejledningen: kopiér aktivitet, dataflow eller Spark.
Fabric Dataflow Gen2 understøtter mange konfigurationer og indstillinger, herunder planlægning. Denne artikels eksempel forenkles for at komme i gang med en simpel datakopi.
Forudsætninger
- Du har brug for en eksisterende Fabric-kapacitet. Hvis du ikke gør det, skal du starte en Fabric-prøveversion.
- Opret et nyt arbejdsområde, eller brug et eksisterende Fabric-arbejdsområde.
- Opret en ny SQL-database , eller brug en eksisterende SQL-database.
- Indlæs AdventureWorks-eksempeldataene i en ny SQL-database, eller brug dine egne eksempeldata.
Kom i gang med Fabric Dataflow Gen2
- Åbn dit arbejdsområde. Vælg + Nyt element.
- Vælg Dataflow Gen 2 i menuen.
- Når den nye Dataflow åbnes, skal du vælge Hent data. Du kan også vælge pil ned på Hent data og derefter Mere.
- Vælg din Fabric SQL-database på listen OneLake . Det vil være kilden til denne Dataflow.
- Vælg en tabel ved at markere afkrydsningsfeltet ud for den.
- Vælg Opret.
- Du har nu konfigureret det meste af dit dataflow. Der er mange forskellige konfigurationer, du kan gøre herfra for at få flytningen af datakonfigurationen til at opfylde dine behov.
- Derefter skal vi konfigurere en destination. Vælg plusknappen (+) ud for Datadestination.
- Vælg SQL-database.
- Vælg Næste. Hvis Næste ikke er aktiveret, skal du vælge Log på for at godkende igen.
- Vælg destinationsmålet.
- Lad knappen Ny tabel være markeret.
- Vælg et SQL-databasenavn på objektlisten som destination for at kopiere tabellen.
- Giv den nye tabel et navn.
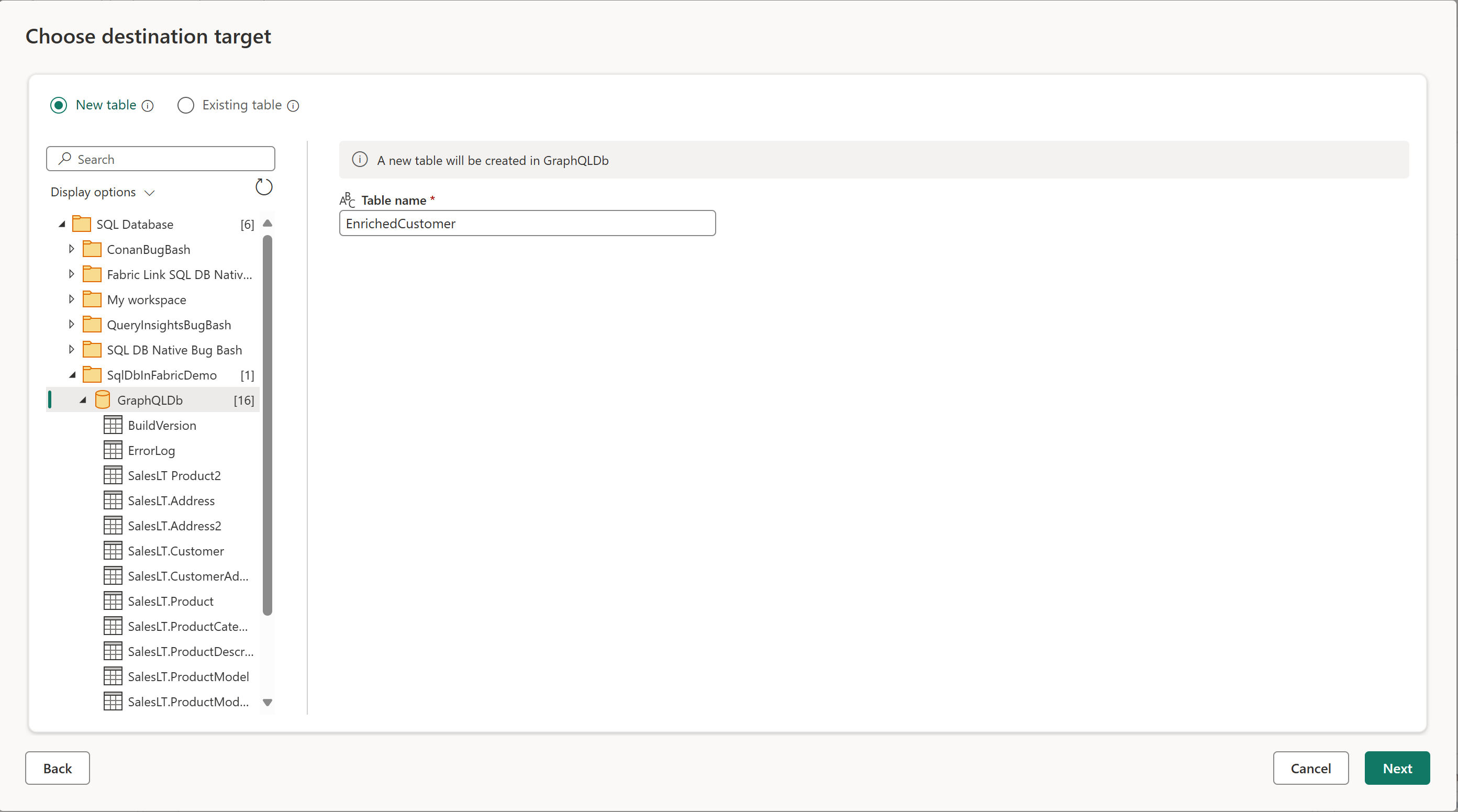
- Vælg Næste.
- Gennemse de tilgængelige indstillinger. Brug automatiske indstillinger.
- Vælg Næste. Du har nu et komplet dataflow.
- Vælg Udgiv. Når Dataflow publicerer, opdateres dataene. Det betyder, at så snart dataflowet er publiceret, kan du se, at det opdateres. Når opdateringen er fuldført, kan du se den nye tabel i databasen.
