Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Du kan oprette forbindelse til SAP HANA-datakilder direkte ved hjælp af DirectQuery, hvilket ofte er påkrævet for store datasæt, der overstiger de tilgængelige ressourcer, for at understøtte importmodeller. Der er to metoder til at oprette forbindelse til SAP HANA i DirectQuery-tilstand, hver med forskellige egenskaber:
Behandl SAP HANA som en flerdimensionel kilde (standard): I dette tilfælde svarer funktionsmåden til, når Power BI opretter forbindelse til andre flerdimensionelle kilder, f.eks. SAP Business Warehouse eller Analysis Services. Når du opretter forbindelse til SAP HANA som en flerdimensionel kilde, vælges der en enkelt analyse- eller beregningsvisning, og alle målinger, hierarkier og attributter for den pågældende visning er tilgængelige på feltlisten. Du kan ikke tilføje beregnede kolonner eller andre datatilpasninger i den semantiske model. Når der oprettes visualiseringer, hentes de aggregerede data direkte fra SAP HANA. Behandl SAP HANA som en flerdimensionel kilde er standarden for nye DirectQuery-rapporter via SAP HANA.
Behandl SAP HANA som en relationel kilde: I dette tilfælde behandler Power BI SAP HANA som en relationel datakilde. Denne fremgangsmåde giver større fleksibilitet. Du kan bl.a. tilføje beregnede kolonner og inkludere data fra andre kilder, men du skal være omhyggelig med at sikre, at målingerne aggregeres som forventet. Undgå ikke-additive målinger. Sørg også for at bruge enkle visninger med få kolonner og joinforbindelser for at undgå problemer med ydeevnen. Overvej at oprette målinger igen i den semantiske model, men vær opmærksom på, at komplekse målinger muligvis ikke kan foldes. SAP HANA-hierarkier er ikke tilgængelige, når SAP HANA bruges som relationskilde.
Forbindelsesmetoden bestemmes af en global værktøjsindstilling, som angives ved at vælge Filer>Indstillinger og derefter Indstillinger>DirectQueryog derefter vælge indstillingen Behandl SAP HANA som en relationel kilde, som vist på følgende billede.
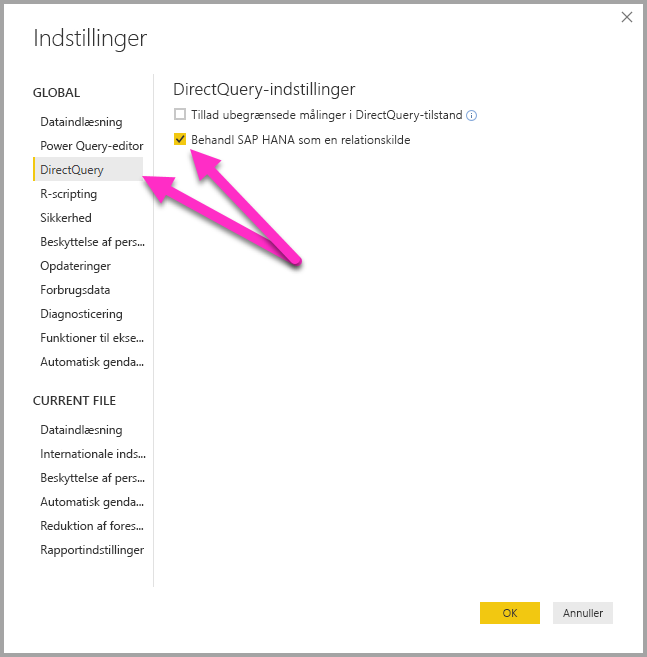
Indstillingen til at behandle SAP HANA som en relationel kilde styrer forbindelsesmetoden for alle nye rapport ved hjælp af DirectQuery via SAP HANA. Det har ingen indvirkning på eksisterende SAP HANA-forbindelser i den aktuelle rapport eller på forbindelser i andre rapporter, der åbnes. Så hvis indstillingen i øjeblikket ikke er markeret, behandler denne forbindelse SAP HANA som en flerdimensionel kilde, når du føjer en ny forbindelse til SAP HANA ved hjælp af Hent data. Men hvis der åbnes en anden rapport, der også opretter forbindelse til SAP HANA, fungerer rapporten fortsat i henhold til den indstilling, der blev angivet på det tidspunkt, den blev oprettet. Dette faktum betyder, at alle rapporter, der opretter forbindelse til SAP HANA som en relationel kilde, fortsat behandler SAP HANA som en relationel kilde, selvom indstillingen nu ikke er markeret.
De to SAP HANA-forbindelsesmetoder udgør en anden funktionsmåde, og det er ikke muligt at skifte en eksisterende rapport fra én forbindelsesmetode til den anden.
Behandl SAP HANA som en flerdimensionel kilde (standard)
Alle nye forbindelser til SAP HANA bruger som standard denne forbindelsesmetode og behandler SAP HANA som en flerdimensionel kilde. Når du opretter forbindelse til SAP HANA som en flerdimensionel kilde, gælder følgende overvejelser:
I Hent datanavigatørkan du vælge en enkelt SAP HANA-visning. Det er ikke muligt at vælge individuelle målinger eller attributter. Der er ikke defineret nogen forespørgsel på oprettelsestidspunktet, hvilket adskiller sig fra import af data, eller når du bruger DirectQuery, mens SAP HANA behandles som en relationel kilde. Denne overvejelse betyder også, at det ikke er muligt at bruge en SAP HANA SQL-forespørgsel direkte, når du vælger denne forbindelsesmetode.
Alle målinger, hierarkier og attributter for den valgte visning vises på feltlisten.
Da en måling bruges i en visualisering, forespørges SAP HANA for at hente målingsværdien på det aggregeringsniveau, der er nødvendigt for visualiseringen. Når du arbejder med ikke-additive målinger, f.eks. tællere og forhold, udføres alle sammenlægninger af SAP HANA, og der udføres ikke yderligere sammenlægning af Power BI.
For at sikre, at de korrekte aggregerede værdier altid kan hentes fra SAP HANA, skal der være visse begrænsninger. Det er f.eks. ikke muligt at tilføje beregnede kolonner eller kombinere data fra flere SAP HANA-visninger i den samme rapport. Det er heller ikke muligt at slette kolonner eller ændre deres datatyper.
At behandle SAP HANA som en flerdimensionel kilde giver mindre fleksibilitet end den alternative relationelle tilgang, men det er mere ligetil. Denne forbindelsesmetode sikrer korrekte aggregerede værdier, når der arbejdes med mere komplekse SAP HANA-målinger, og resulterer generelt i højere ydeevne.
Listen over felt indeholder alle målinger, attributter og hierarkier fra SAP HANA-visningen. Bemærk følgende funktionsmåder, der gælder, når du bruger denne forbindelsesmetode:
Alle attribut, der er inkluderet i mindst ét hierarki, er som standard skjult. De kan dog ses, hvis det er nødvendigt, ved at vælge Vis skjulte i genvejsmenuen på feltlisten. Fra den samme genvejsmenu kan de gøres synlige, hvis det er nødvendigt.
I SAP HANA kan en attribut defineres til at bruge en anden attribut som mærkat. Productmed værdier
1,2,3osv. kan f.eks. bruge ProductNamemed værdierBike,Shirt,Glovesosv. som mærkat. I dette tilfælde vises der et enkelt felt Product på feltlisten, hvis værdier er etiketterneBike,Shirt,Glovesosv., men som sorteres efter og med entydighed bestemt af nøgleværdierne1,2,3. Der oprettes også en skjult kolonne Product.Key, hvilket giver adgang til de underliggende nøgleværdier, hvis det er nødvendigt.
Alle variabler, der er defineret i den underliggende SAP HANA-visning, vises, når der oprettes forbindelse, og de nødvendige værdier kan angives. Disse værdier kan ændres senere ved at vælge Transformér data på båndet og derefter Rediger parametre i den viste rullemenu.
De tilladte modelleringshandlinger er mere restriktive end i det generelle tilfælde, når du bruger DirectQuery, da det er nødvendigt at sikre, at korrekte aggregerede data altid kan hentes fra SAP HANA. Det er dog stadig muligt at foretage nogle tilføjelser og ændringer, herunder definere målinger, omdøbe og skjule felter og definere visningsformater. Alle disse ændringer bevares ved opdatering, og eventuelle ændringer, der ikke er i konflikt med SAP HANA-visningen, anvendes.
Yderligere begrænsninger for udformning
Ud over de nævnte begrænsninger skal du være opmærksom på følgende begrænsninger for modellering, når du opretter forbindelse til SAP HANA som en flerdimensionel kilde:
- Ingen understøttelse af beregnede kolonner: Muligheden for at oprette beregnede kolonner er deaktiveret. Dette faktum betyder også, at gruppering og klyngedannelse, der er afhængige af beregnede kolonner, ikke er tilgængelige.
- Yderligere begrænsninger for målinger: Der er andre begrænsninger for DAX-udtryk, der kan bruges i målinger, for at afspejle det supportniveau, der tilbydes af SAP HANA. Det er f.eks. ikke muligt at bruge en aggregeringsfunktion over en tabel.
- Ingen understøttelse af definition af relationer: Det er kun en enkelt visning, der kan forespørges i en rapport, og derfor understøttes definition af relationer ikke.
- Ingen tabelvisning: Den tabelvisning viser normalt data på detaljeniveau i tabellerne. På grund af karakteren af flerdimensionelle kilder er denne visning ikke tilgængelig, når DU bruger SAP HANA som en flerdimensionel kilde.
- Oplysninger om kolonne og måling er faste: Kolonnerne og målingerne på feltlisten bestemmes af den underliggende kilde og kan ikke ændres. Det er f.eks. ikke muligt at slette en kolonne eller ændre dens datatype. Den kan dog omdøbes.
Yderligere begrænsninger for visualiseringer
Der er begrænsninger i visualiseringer, når du opretter forbindelse til SAP HANA som en flerdimensionel kilde:
- Ingen aggregering af kolonner: Det er ikke muligt at ændre aggregeringen for en kolonne i en visualisering, og det er altid Opsummer ikke.
Behandl SAP HANA som en relationel kilde
Hvis du vil oprette forbindelse til SAP HANA som en relationskilde, skal du vælge Filer>Indstillinger og derefter Indstillinger>DirectQueryog derefter vælge indstillingen Behandl SAP HANA som en relationel kilde.
Når du bruger SAP HANA som relationskilde, er der en vis ekstra fleksibilitet tilgængelig. Du kan f.eks. oprette beregnede kolonner, medtage data fra flere SAP HANA-visninger og oprette relationer mellem de resulterende tabeller. Der er dog forskelle fra funktionsmåden, når du opretter forbindelse til SAP HANA som en flerdimensionel kilde, især når SAP HANA-visningen indeholder ikke-additive målinger, f.eks. særskilte optællinger eller gennemsnit i stedet for simple summer. Ikke-additive målinger kan give forkerte resultater. Målingerne kan også reducere effektiviteten af optimering af forespørgselsplan i SAP HANA og resultere i dårlig forespørgselsydeevne og timeout.
Om SAP HANA som en relationel kilde
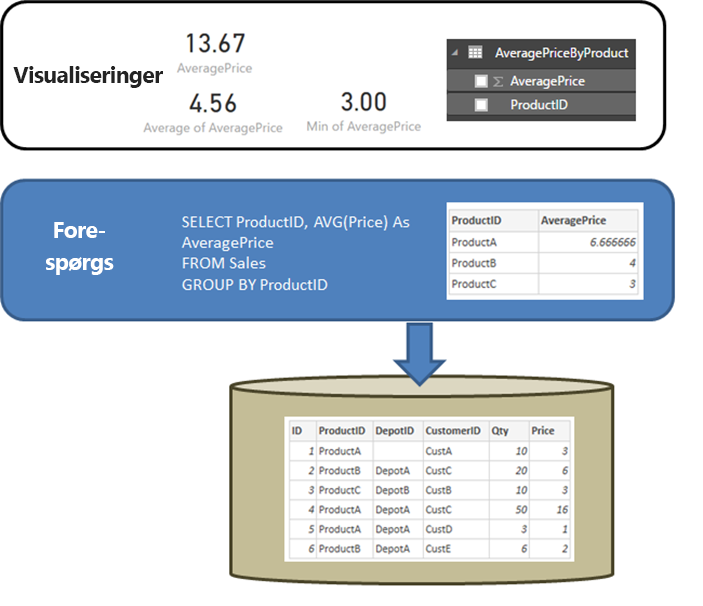
Det er nyttigt at starte med at tydeliggøre funktionsmåden for en relationskilde, f.eks. SQL Server, når den forespørgsel, der er defineret i Hent data eller Power Query-editor, udfører en sammenlægning. I det følgende eksempel returnerer en forespørgsel, der er defineret i Power Query-editor, gennemsnitsprisen ved ProductID.
Hvis dataene blev importeret til Power BI i stedet for at bruge DirectQuery, ville følgende situation medføre:
- Dataene importeres på det aggregeringsniveau, der er defineret af den forespørgsel, der er oprettet i Power Query-editor. F.eks. gennemsnitsprisen efter produkt. Dette faktum resulterer i en tabel med de to kolonner ProductID- og AveragePrice-, der kan bruges i visualiseringer.
- I en visualisering udføres alle efterfølgende aggregeringer, f.eks. Sum, Average, Minog andre, over de importerede data. Hvis du f.eks. medtager AveragePrice- i en visualisering, bruges den Sum- aggregering som standard og returnerer summen over AveragePrice- for hver ProductID-i dette eksempel 13,67. Det samme gælder for alle alternative aggregeringsfunktioner, f.eks. Min. eller Average, der bruges i visualiseringen. Gennemsnit af AveragePrice- returnerer f.eks. gennemsnittet af 6,66, 4 og 3, hvilket svarer til 4,56, og ikke gennemsnittet af Price for de seks poster i den underliggende tabel, hvilket er 5,17.
Hvis DirectQuery over den samme relationelle kilde bruges i stedet for Import, gælder den samme semantik, og resultaterne vil være nøjagtigt de samme:
På grund af den samme forespørgsel præsenteres nøjagtigt de samme data logisk for rapporteringslaget – selvom dataene faktisk ikke importeres.
I en visualisering udføres alle efterfølgende aggregeringer, f.eks. Sum, Averageog Min, igen over den logiske tabel fra forespørgslen. Og igen returnerer en visualisering, der indeholder Average af AveragePrice de samme 4,56.
Overvej SAP HANA, når forbindelsen behandles som en relationel kilde. Power BI kan arbejde med både analysevisninger og beregningsvisninger i SAP HANA, som begge kan indeholde målinger. Men i dag følger tilgangen til SAP HANA de samme principper som beskrevet tidligere i dette afsnit: Den forespørgsel, der er defineret i Hent data eller Power Query-editor, bestemmer de tilgængelige data, og derefter er alle efterfølgende aggregeringer i en visualisering over disse data, og det samme gælder for både Import og DirectQuery. Men på grund af SAP HANA's karakter er den forespørgsel, der er defineret i den indledende Hent data dialogboks eller Power Query-editor altid en aggregeringsforespørgsel og omfatter generelt målinger, hvor de faktiske sammenlægninger, der bruges, er defineret af SAP HANA-visningen.
Det tilsvarende til det forrige SQL Server-eksempel er, at der er en SAP HANA-visning, der indeholder id, ProductID, DepotIDog målinger, herunder AveragePrice, der er defineret i visningen som Average of Price.
Hvis de foretagne valg i Hent data var for ProductID- og målingen AveragePrice, definerer det en forespørgsel for visningen og anmoder om de aggregerede data. I det tidligere eksempel bruges der for nemheds skyld pseudo-SQL, der ikke stemmer overens med den nøjagtige syntaks i SAP HANA SQL. Derefter aggregerer eventuelle yderligere sammenlægninger, der er defineret i en visualisering, yderligere resultaterne af en sådan forespørgsel. Som beskrevet tidligere for SQL Server gælder dette resultat både for import- og DirectQuery-sagen. I DirectQuery-sagen bruges forespørgslen fra Hent data eller Power Query-editor i en undermarkering i en enkelt forespørgsel, der sendes til SAP HANA, og derfor er det faktisk ikke tilfældet, at alle dataene læses ind, før de aggregeres yderligere.
Alle disse overvejelser og funktionsmåder nødvendiggør følgende vigtige overvejelser, når DirectQuery bruges via SAP HANA som en relationel kilde:
Du skal være opmærksom på enhver yderligere aggregering, der udføres i visualiseringer, når målingen i SAP HANA ikke er additiv, f.eks. ikke en simpel Sum, Min.eller Max.
I Hent data eller Power Query-editor skal kun de påkrævede kolonner medtages for at hente de nødvendige data, hvilket afspejler, at resultatet er en forespørgsel, der skal være en rimelig forespørgsel, der kan sendes til SAP HANA. Hvis der f.eks. er valgt mange kolonner med den tanke, at de kan være nødvendige i efterfølgende visualiseringer, betyder en simpel visualisering, at den aggregerede forespørgsel, der bruges i undermarkeringen, indeholder de mange kolonner, der generelt klarer sig dårligt og kan støde på timeout.
I følgende eksempel skal du vælge fem kolonner (CalendarQuarter, Color, LastName, ProductLine, SalesOrderNumber) i dialogboksen Hent data . sammen med målingen OrderQuantitybetyder, at senere oprettelse af en simpel visualisering, der indeholder Min OrderQuantity resulterer i følgende SQL-forespørgsel til SAP HANA. Den nedtonede er undermarkeringen, der indeholder forespørgslen fra Hent data/Power Query-editor. Hvis denne undermarkering giver et resultat med høj kardinalitet, vil den resulterende SAP HANA-ydeevne sandsynligvis være dårlig eller støde på timeout. Påvirkningen af ydeevnen skyldes ikke, at Power BI anmoder om alle felter i undermarkering. de fleste af disse felter projekteres væk af den ydre forespørgsel. Virkningen skyldes snarere, at målinger i undermarkeringer tvinger den til at blive materialiseret på HANA-serveren.

På grund af denne funktionsmåde anbefaler vi, at de elementer, der er valgt i Hent data eller Power Query-editor, begrænses til de elementer, der er nødvendige, samtidig med at de stadig resulterer i en rimelig forespørgsel til SAP HANA. Hvis det er muligt, kan du overveje at genskabe alle de påkrævede målinger i den semantiske model og bruge SAP HANA mere som en traditionel relationel kilde.
Bedste fremgangsmåder
Hvis begge metoder skal oprette forbindelse til SAP HANA, skal du følge de generelle anbefalinger til brug af DirectQuery, især anbefalinger, der er relateret til at sikre en god forespørgselsydeevne. Du kan finde flere oplysninger under brug af DirectQuery i Power BI.
Overvejelser og begrænsninger
På følgende liste beskrives alle SAP HANA-funktioner, der ikke understøttes fuldt ud, eller funktioner, der fungerer anderledes, når du bruger Power BI.
- overordnede underordnede hierarkier: overordnede underordnede hierarkier er ikke synlige i Power BI. Det skyldes, at Power BI får adgang til SAP HANA ved hjælp af SQL-grænsefladen, og at der ikke kan opnås fuld adgang til overordnede underordnede hierarkier ved hjælp af SQL.
- Andre metadata for hierarkier: Den grundlæggende struktur for hierarkier vises i Power BI, men nogle hierarkimetadata, f.eks. styring af funktionsmåden for ujævne hierarkier, har ingen effekt. Dette skyldes igen begrænsninger, der er pålagt af SQL-grænsefladen.
- forbindelse ved hjælp af SSL: Du kan oprette forbindelse ved hjælp af Import og multidimensionel med TLS, men kan ikke oprette forbindelse til SAP HANA-forekomster, der er konfigureret til at bruge TLS til relationel forbindelsesmetode.
- Understøttelse af attributvisninger: Power BI kan oprette forbindelse til analyse- og beregningsvisninger, men kan ikke oprette direkte forbindelse til attributvisninger.
- understøttelse af katalogobjekter: Power BI kan ikke oprette forbindelse til katalogobjekter.
- Skift til variabler efter publicering: Du kan ikke ændre værdierne for SAP HANA-variabler direkte i Power BI-tjenesten, når rapporten er publiceret.
Kendte problemer
På følgende liste beskrives alle kendte problemer, når du opretter forbindelse til SAP HANA (DirectQuery) ved hjælp af Power BI.
SAP HANA-problem, når der sendes en forespørgsel om tællere og andre målinger: Der returneres forkerte data fra SAP HANA, hvis der oprettes forbindelse til en analysevisning, og en tællermåling og en anden forholdsmåling inkluderes i den samme visualisering. Dette problem er dækket af SAP Note 2128928 (uventede resultater, når der forespørges om en beregnet kolonne og en tæller). Forholdsmålingen er forkert i dette tilfælde.
Flere Power BI-kolonner fra en enkelt SAP HANA-kolonne: For nogle beregningsvisninger, hvor en SAP HANA-kolonne bruges i mere end ét hierarki, viser SAP HANA kolonnen som to separate attributter. Denne fremgangsmåde resulterer i, at der oprettes to kolonner i Power BI. Disse kolonner er dog som standard skjult, og alle forespørgsler, der involverer hierarkierne eller kolonnerne direkte, fungerer korrekt.
Relateret indhold
Du kan finde flere oplysninger om DirectQuery i følgende ressourcer:
- DirectQuery i Power BI-
- Datakilder, der understøttes af DirectQuery
- DirectQuery- og SAP BW-
-
datagateway i det lokale miljø