Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
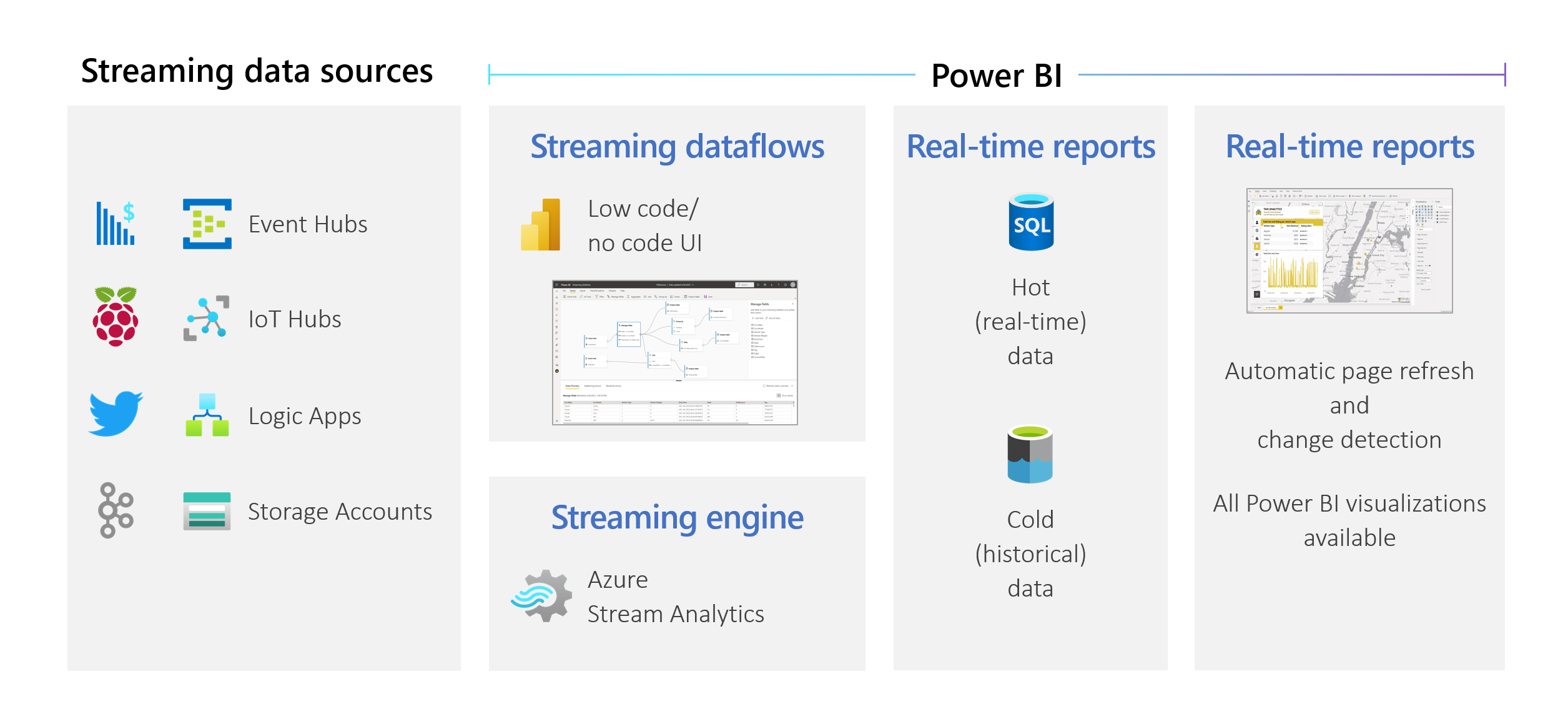
Organisationer vil arbejde med data, som de kommer ind, ikke dage eller uger senere. Visionen om Power BI er enkel: Forskellen mellem batch, realtid og streaming bør forsvinde. Brugerne bør kunne arbejde med alle data, så snart de er tilgængelige. Analytikere har normalt brug for teknisk hjælp til at håndtere streamingdatakilder, dataforberedelse, komplekse tidsbaserede handlinger og datavisualisering i realtid. It-afdelinger er ofte afhængige af specialbyggede systemer og en kombination af teknologier fra forskellige leverandører for at kunne udføre rettidige analyser af dataene. Uden denne kompleksitet kan de ikke give beslutningstagere oplysninger i næsten realtid.
Streaming af dataflow gør det muligt for forfattere at oprette forbindelse til, indtage, mikse, modellere og oprette rapporter baseret på streaming i data i næsten realtid direkte i Power BI-tjeneste. Tjenesten gør det muligt at trække og slippe uden kode. Du kan blande og matche streamingdata med batchdata, hvis du har brug for det via en brugergrænseflade, der indeholder en diagramvisning , der gør det nemt at mikse data. Det endelige element, der produceres, er et dataflow, som kan bruges i realtid for at oprette meget interaktiv rapportering i næsten realtid. Alle datavisualiseringsfunktionerne i Power BI fungerer med streamingdata på samme måde som med batchdata.
Vigtigt
Streamingdataflows er udgået og er ikke længere tilgængelige.
Azure Stream Analytics har flettet funktionaliteten af streamingdataflow. Du kan få flere oplysninger om udfasning af streamingdataflow i udfasningsmeddelelsen.
 Brugerne kan udføre dataforberedelseshandlinger, f.eks. joinforbindelser og filtre. De kan også udføre sammenlægninger af tidsvinduer (f.eks. tumbling, hopping og sessionsvinduer) for group-by-handlinger.
Streaming af dataflow i Power BI giver organisationer mulighed for at:
Brugerne kan udføre dataforberedelseshandlinger, f.eks. joinforbindelser og filtre. De kan også udføre sammenlægninger af tidsvinduer (f.eks. tumbling, hopping og sessionsvinduer) for group-by-handlinger.
Streaming af dataflow i Power BI giver organisationer mulighed for at:
- Træn sikre beslutninger i næsten realtid. Organisationer kan være mere fleksible og udføre meningsfulde handlinger baseret på den mest opdaterede indsigt.
- Demokratiser streamingdata. Organisationer kan gøre data mere tilgængelige og nemmere at fortolke med en løsning uden kode, og denne tilgængelighed reducerer it-ressourcer.
- Sæt fart på indsigten ved hjælp af en komplette streaminganalyseløsning med integreret datalager og business intelligence.
Streamingdataflow understøtter DirectQuery og automatisk opdatering/ændring af sider. Denne support giver brugerne mulighed for at oprette rapporter, der opdateres i næsten realtid, op til hvert sekund, ved hjælp af en hvilken som helst visualisering, der er tilgængelig i Power BI.
Krav
Før du opretter dit første streamingdataflow, skal du sørge for, at du opfylder alle følgende krav:
Hvis du vil oprette og køre et streamingdataflow, skal du bruge et arbejdsområde, der er en del af en Premium-kapacitet eller premium pr. bruger-licens.
Vigtigt
Hvis du bruger en Premium pr. bruger-licens, og du ønsker, at andre brugere skal bruge rapporter, der er oprettet med streamingdataflow, som opdateres i realtid, skal de også bruge en Premium pr. bruger-licens. De kan derefter bruge rapporterne med den samme opdateringshyppighed, som du konfigurerer, hvis opdateringen er hurtigere end hvert 30. minut.
Aktivér dataflow for din lejer. Du kan få flere oplysninger under Aktivering af dataflow i Power BI Premium.
For at sikre, at streamingdataflow fungerer i din Premium-kapacitet, skal det forbedrede beregningsprogram være slået til. Programmet er som standard slået til, men power BI-kapacitetsadministratorer kan slå det fra. Hvis det er tilfældet, skal du kontakte din administrator for at aktivere den.
Det forbedrede beregningsprogram er kun tilgængeligt i Premium P eller Embedded A3 og større kapaciteter. Hvis du vil bruge streamingdataflow, skal du enten bruge Premium pr. bruger, en Premium P-kapacitet af enhver størrelse eller en Embedded A3-kapacitet eller en større kapacitet. Du kan få flere oplysninger om Premium-SKU'er og deres specifikationer under Kapacitet og SKU'er i en integreret Power BI-analyse.
Hvis du vil oprette rapporter, der opdateres i realtid, skal du sørge for, at din administrator (kapacitet eller Power BI til Premium pr. bruger) har aktiveret automatisk sideopdatering. Sørg også for, at administratoren har tilladt et minimuminterval for opdatering, der svarer til dine behov. Du kan få flere oplysninger under Automatisk sideopdatering i Power BI.
Opret et streamingdataflow
Et streamingdataflow er, ligesom dets relative dataflow, en samling objekter (tabeller), der er oprettet og administreret i arbejdsområder i Power BI-tjeneste. En tabel er et sæt felter, der bruges til at gemme data på samme måde som en tabel i en database.
Du kan tilføje og redigere tabeller i dit streamingdataflow direkte fra det arbejdsområde, hvor dit dataflow blev oprettet. Den største forskel med almindelige dataflow er, at du ikke behøver at bekymre dig om opdateringer eller frekvens. På grund af arten af streamingdata kommer der en kontinuerlig stream ind. Opdateringen er konstant eller uendelig, medmindre du stopper den.
Bemærk
Du kan kun have én type dataflow pr. arbejdsområde. Hvis du allerede har et almindeligt dataflow i dit Premium-arbejdsområde, kan du ikke oprette et streamingdataflow (og omvendt).
Sådan opretter du et streamingdataflow:
Åbn Power BI-tjeneste i en browser, og vælg derefter et Premium-aktiveret arbejdsområde. (Streaming af dataflow, f.eks. almindelige dataflow, er ikke tilgængelige i Mit arbejdsområde.)
Vælg rullemenuen Ny, og vælg derefter Streamingdataflow.
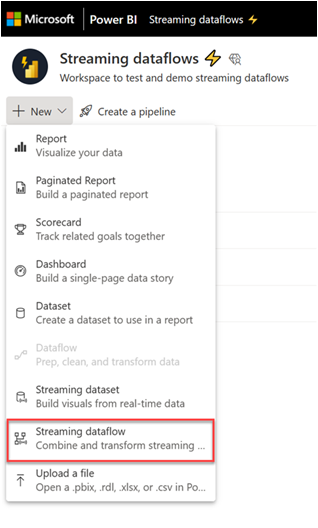
I den siderude, der åbnes, skal du navngive dit streamingdataflow. Angiv et navn i feltet Navn (1), og vælg derefter Opret (2).
Den tomme diagramvisning for streaming af dataflow vises.
På følgende skærmbillede vises et færdigt dataflow. Den fremhæver alle de sektioner, der er tilgængelige for dig til oprettelse i brugergrænsefladen for streamingdataflow.

Bånd: På båndet følger afsnittene rækkefølgen af en "klassisk" analyseproces: input (også kaldet datakilder), transformationer (streaming ETL-handlinger), output og en knap for at gemme status.
Diagramvisning: Denne visning er en grafisk gengivelse af dit dataflow fra input til handlinger til output.
Siderude: Afhængigt af hvilken komponent du vælger i diagramvisningen, har du indstillinger til at ændre hvert input, hver transformation eller hvert output.
Faner til eksempelvisning af data, oprettelsesfejl og kørselsfejl: For hvert kort, der vises, viser dataeksemplet resultaterne for det pågældende trin (live for input og on-demand for transformationer og output).
I dette afsnit opsummeres også eventuelle oprettelsesfejl eller advarsler, som du måtte have i dine dataflow. Hvis du vælger hver fejl eller advarsel, vælges den pågældende transformering. Derudover har du adgang til kørselsfejl, når dataflowet kører, f.eks. mistede meddelelser.
Du kan altid minimere denne sektion af streamingdataflow ved at vælge pilen i øverste højre hjørne.
Et streamingdataflow er baseret på tre hovedkomponenter: streaminginput, transformationer og output. Du kan have lige så mange komponenter, du vil, herunder flere input, parallelle forgreninger med flere transformationer og flere output.
Tilføj et streaminginput
Hvis du vil tilføje et streaminginput, skal du vælge ikonet på båndet og angive de oplysninger, der er nødvendige i sideruden for at konfigurere det. Fra og med juli 2021 understøtter prøveversionen af streamingdataflow Azure Event Hubs og Azure IoT Hub som input.
Azure Event Hubs- og Azure IoT Hub-tjenesterne er bygget på en fælles arkitektur for at lette hurtig og skalerbar indtagelse og forbrug af hændelser. Især IoT Hub er skræddersyet som en central meddelelseshub til kommunikation i begge retninger mellem et IoT-program og dets tilknyttede enheder.
Azure Event Hubs
Azure Event Hubs er en streamingplatform til big data og tjeneste til hændelsesindtagelse. Den kan modtage og behandle millioner af hændelser pr. sekund. Data, der sendes til en hændelseshub, kan transformeres og gemmes ved hjælp af en hvilken som helst analyseudbyder i realtid, eller du kan bruge batching- eller lageradaptere.
Hvis du vil konfigurere en hændelseshub som et input til streaming af dataflow, skal du vælge ikonet Event Hub . Der vises et kort i diagramvisningen, herunder en siderude til konfigurationen.
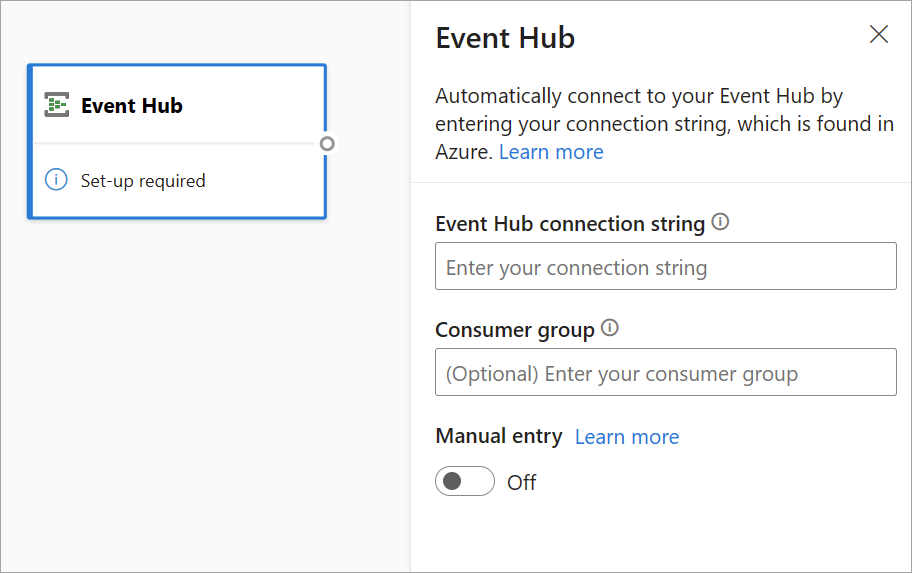
Du har mulighed for at indsætte Event Hubs forbindelsesstreng. Streamingdataflow udfylder alle nødvendige oplysninger, herunder den valgfri forbrugergruppe (som som standard er $Default). Hvis du vil angive alle felter manuelt, kan du slå til/fra-knappen til manuelt for at få dem vist. Du kan få mere at vide under Få en Event Hubs-forbindelsesstreng.
Når du har konfigureret dine Event Hubs-legitimationsoplysninger og valgt Opret forbindelse, kan du tilføje felter manuelt ved hjælp af + Tilføj felt , hvis du kender feltnavnene. Du kan også automatisk registrere felter og datatyper baseret på et eksempel på de indgående meddelelser ved at vælge Registrer felter automatisk. Hvis du vælger tandhjulsikonet, kan du redigere legitimationsoplysningerne, hvis det er nødvendigt.
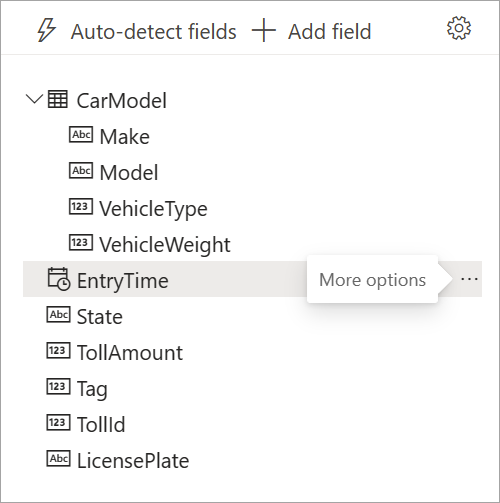
Når streaming af dataflow registrerer felterne, kan du se dem på listen. Der er også en direkte eksempelvisning af de indgående meddelelser i tabellen Dataeksempel under diagramvisningen.
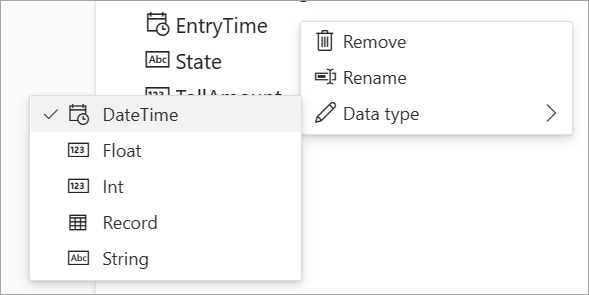
Du kan altid redigere feltnavnene eller fjerne eller ændre datatypen ved at vælge flere indstillinger (...) ud for hvert felt. Du kan også udvide, vælge og redigere indlejrede felter fra de indgående meddelelser som vist på følgende billede.
Azure IoT Hub
IoT Hub er en administreret tjeneste, der hostes i cloudmiljøet. Det fungerer som en central meddelelseshub for kommunikation i begge retninger mellem et IoT-program og dets tilknyttede enheder. Du kan forbinde millioner af enheder og deres back end-løsninger pålideligt og sikkert. Næsten alle enheder kan forbindes til en IoT-hub.
IoT Hub-konfigurationen ligner Event Hubs-konfigurationen på grund af deres fælles arkitektur. Men der er nogle forskelle, herunder hvor du kan finde event hubs-kompatible forbindelsesstreng til det indbyggede slutpunkt. Du kan få mere at vide under Læs enheds-til-sky-meddelelser fra det indbyggede slutpunkt.
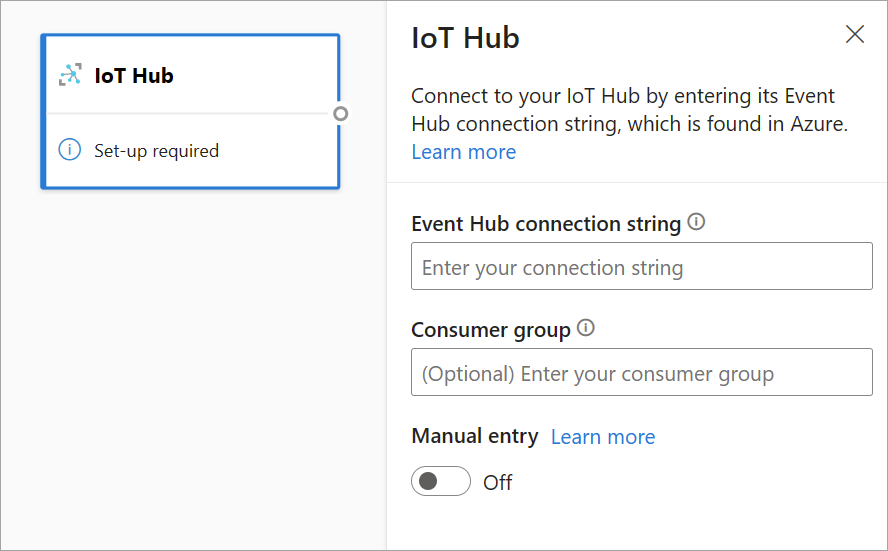
Når du har indsat forbindelsesstreng for det indbyggede slutpunkt, er al funktionalitet til markering, tilføjelse, automatisk registrering og redigering af felter, der kommer ind fra IoT Hub, den samme som i Event Hubs. Du kan også redigere legitimationsoplysningerne ved at vælge tandhjulsikonet.
Tip
Hvis du har adgang til Event Hubs eller IoT Hub i din organisations Azure-portal, og du vil bruge den som input til dit streamingdataflow, kan du finde forbindelsesstreng s på følgende placeringer:
For Event Hubs:
- I afsnittet Analytics skal du vælge Alle services>Event Hubs.
- Vælg Event Hubs Namespace>Entities/Event Hubs, og vælg derefter navnet på hændelseshubben.
- Vælg en politik på listen Politikker for delt adgang.
- Vælg Kopiér til Udklipsholder ud for feltet Forbindelsesstreng - primær nøgle .
Til IoT Hub:
- I afsnittet Tingenes internet skal du vælge Alle tjenester>IoT Hubs.
- Vælg den IoT-hub, du vil oprette forbindelse til, og vælg derefter Indbyggede slutpunkter.
- Vælg Kopiér til Udklipsholder ud for det Event Hubs-kompatible slutpunkt.
Når du bruger streamdata fra Event Hubs eller IoT Hub, har du adgang til følgende metadatatidsfelter i dit streamingdataflow:
- EventProcessedUtcTime: Den dato og det klokkeslæt, hvor hændelsen blev behandlet.
- EventEnqueuedUtcTime: Den dato og det klokkeslæt, hvor hændelsen blev modtaget.
Ingen af disse felter vises i inputeksemplet. Du skal tilføje dem manuelt.
Blob Storage
Azure Blob Storage er Microsofts objektlagerløsning til cloudmiljøet. Blob Storage er optimeret til lagring af enorme mængder ustrukturerede data. Ustrukturerede data er data, der ikke overholder en bestemt datamodel eller -definition, f.eks. tekst eller binære data.
Du kan bruge Azure Blobs som streaming- eller referenceinput. Streaming-blobs kontrolleres hvert sekund for opdateringer. I modsætning til en streaming-blob indlæses der kun en referenceblob i starten af opdateringen. Det er statiske data, der ikke forventes at blive ændret, og den anbefalede grænse for statiske data er 50 MB eller mindre.
Power BI forventer, at referenceblobs bruges sammen med streamingkilder, f.eks. via en JOIN. Derfor skal et streamingdataflow med en referenceblob også have en streamingkilde.
Konfigurationen af Azure Blobs er lidt anderledes end for en Azure Event Hubs-node. Hvis du vil finde dine Azure Blob-forbindelsesstreng, skal du se Få vist kontoadgangsnøgler.
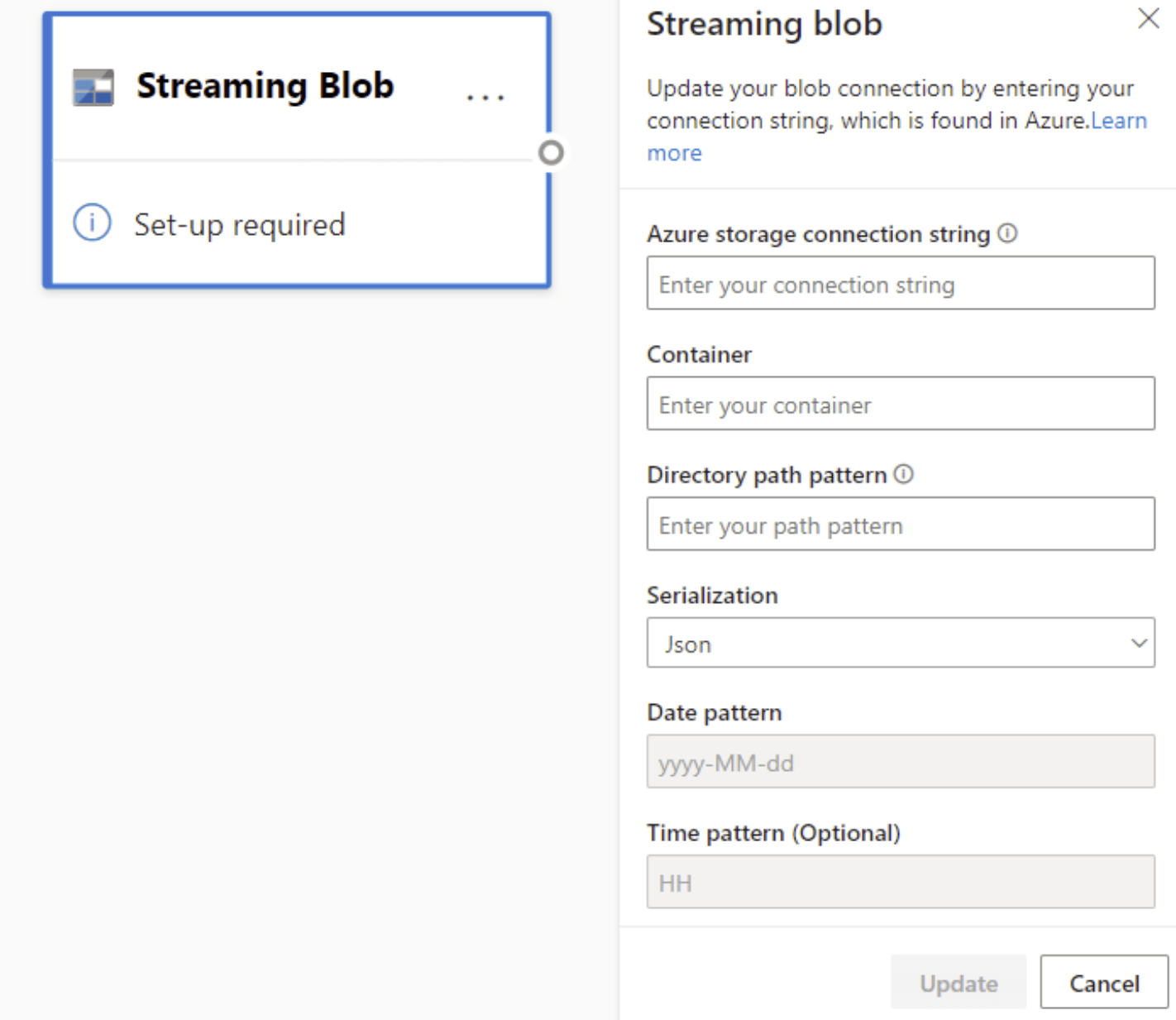
Når du har angivet Blob-forbindelsesstreng, skal du angive navnet på din objektbeholder. Du skal også angive stimønsteret i mappen for at få adgang til de filer, du vil angive som kilde for dit dataflow.
I forbindelse med streaming-blobs forventes mønsteret for mappestien at være en dynamisk værdi. Datoen skal være en del af filstien for bloben – der refereres til som {date}. Desuden understøttes en stjerne (*) i stimønsteret, f.eks. {date}/{time}/*.json, ikke.
Hvis du f.eks. har en blob kaldet ExampleContainer, som du gemmer indlejrede .json filer i, hvor det første niveau er oprettelsesdatoen, og det andet niveau er oprettelsestidspunktet (yyyy-mm-dd/hh), vil dit objektbeholderinput være "ExampleContainer". Mønsteret for mappestien er "{date}/{time}", hvor du kan ændre dato- og klokkeslætsmønsteret.

Når din blob er forbundet til slutpunktet, er al funktionalitet til valg, tilføjelse, automatisk registrering og redigering af felter, der kommer ind fra Azure Blob, den samme som i Event Hubs. Du kan også redigere legitimationsoplysningerne ved at vælge tandhjulsikonet.
Når du arbejder med data i realtid, komprimeres data ofte, og identifikatorer bruges til at repræsentere objektet. En mulig use case til blobs kan også være som referencedata for dine streamingkilder. Referencedata giver dig mulighed for at joinforbinde statiske data til streamingdata for at forbedre dine streams til analyse. Et hurtigt eksempel på, hvornår denne funktion ville være nyttig, ville være, hvis du installerede sensorer i forskellige stormagasiner for at måle, hvor mange personer der kommer ind i butikken på et givent tidspunkt. Normalt skal sensor-id'et være sluttet til en statisk tabel for at angive, hvilket stormagasin og hvilken placering sensoren er placeret på. Nu med referencedata er det muligt at joinforbinde disse data i indtagelsesfasen for at gøre det nemt at se, hvilket lager der har det højeste output fra brugerne.
Bemærk
Et streamingdataflowjob henter data fra Azure Blob Storage eller ADLS Gen2-input hvert sekund, hvis blobfilen er tilgængelig. Hvis blobfilen ikke er tilgængelig, er der en eksponentiel backoff med en maksimal tidsforsinkelse på 90 sekunder.
Datatyper
De tilgængelige datatyper for streaming af dataflowfelter omfatter:
- DateTime: Dato- og klokkeslætsfelt i ISO-format
- Flydende: Decimaltal
- Int: Heltal
- Post: Indlejret objekt med flere poster
- Streng: Tekst
Vigtigt
De datatyper, der er valgt til et streaminginput, har vigtige konsekvenser downstream for dit streamingdataflow. Vælg datatypen så tidligt som muligt i dit dataflow for at undgå at skulle stoppe den senere i forbindelse med redigeringer.
Tilføj en transformation af streamingdata
Streamingdatatransformationer adskiller sig i sagens natur fra batchdatatransformationer. Næsten alle streamingdata har en tidskomponent, der påvirker alle involverede dataforberedelsesopgaver.
Hvis du vil føje en transformation af streamingdata til dit dataflow, skal du vælge transformationsikonet på båndet for den pågældende transformation. Det respektive kort vises i diagramvisningen. Når du har valgt den, kan du se sideruden for transformationen for at konfigurere den.
Fra og med juli 2021 understøtter streamingdataflow følgende streamingtransformationer.
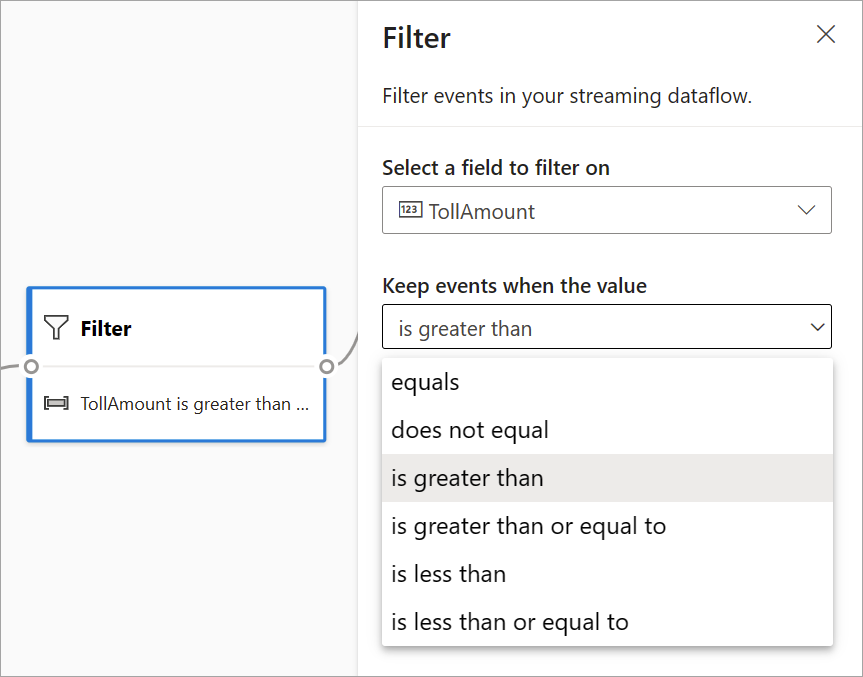
Filtrer
Brug transformationen Filter til at filtrere hændelser baseret på værdien af et felt i inputtet. Afhængigt af datatypen (tal eller tekst) bevarer transformationen de værdier, der svarer til den valgte betingelse.
Bemærk
På hvert kort kan du se oplysninger om, hvad der ellers er nødvendigt, for at transformationen er klar. Når du f.eks. tilføjer et nyt kort, får du vist meddelelsen "Konfigurer påkrævet". Hvis du mangler en nodeconnector, får du vist meddelelsen "Fejl" eller "Advarsel".
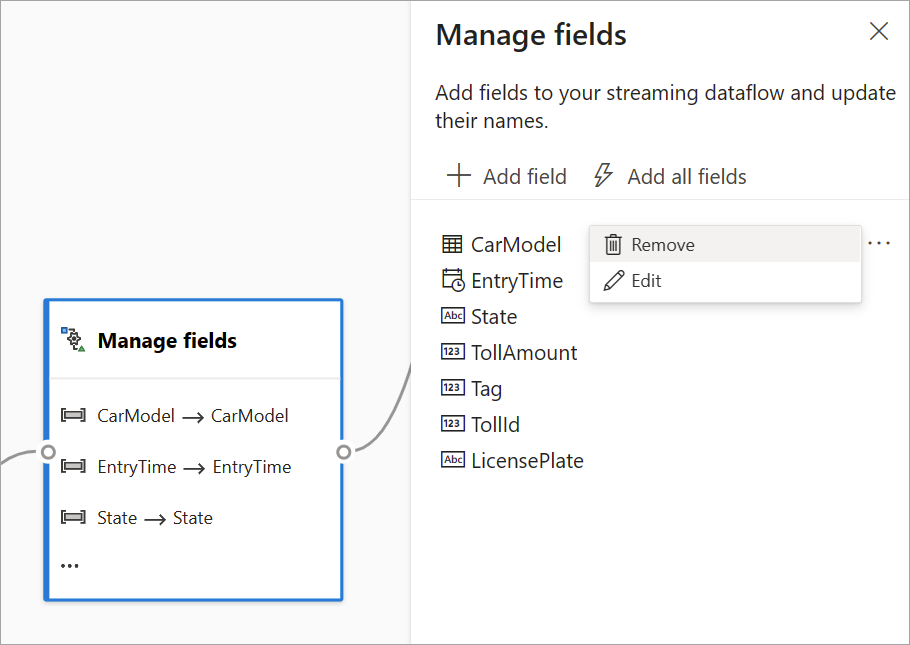
Administrer felter
Transformationen Administrer felter giver dig mulighed for at tilføje, fjerne eller omdøbe felter, der kommer ind fra et input eller en anden transformation. Indstillingerne i sideruden giver dig mulighed for at tilføje et nyt ved at vælge Tilføj felt eller tilføje alle felter på én gang.
Tip
Når du har konfigureret et kort, får du et glimt af indstillingerne på selve kortet i diagramvisningen. I området Administrer felter i det foregående billede kan du f.eks. se de første tre felter, der administreres, og de nye navne, der er tildelt til dem. Hvert kort har oplysninger, der er relevante for det.
Aggregering
Du kan bruge transformationen Aggregering til at beregne en aggregering (Sum, Minimum, Maksimum eller Gennemsnit), hver gang en ny hændelse indtræffer over en periode. Denne handling giver dig også mulighed for at filtrere eller opdele sammenlægningen baseret på andre dimensioner i dine data. Du kan have en eller flere sammenlægninger i den samme transformation.
Hvis du vil tilføje en sammenlægning, skal du vælge transformationsikonet. Forbind derefter et input, vælg sammenlægningen, tilføj eventuelle filter- eller udsnitsdimensioner, og vælg den tidsperiode, hvor du vil beregne sammenlægningen. I dette eksempel beregnes summen af vejafgiftsværdien efter den tilstand, hvor køretøjet er fra over de sidste 10 sekunder.
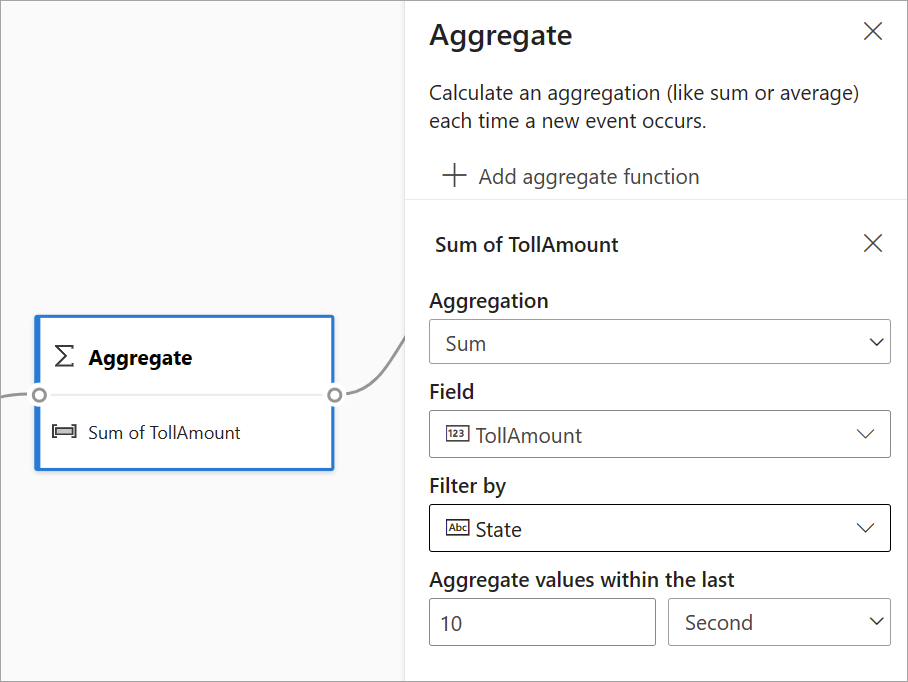
Hvis du vil føje endnu en aggregering til den samme transformation, skal du vælge Tilføj aggregeringsfunktion. Vær opmærksom på, at filteret eller udsnittet gælder for alle sammenlægninger i transformationen.
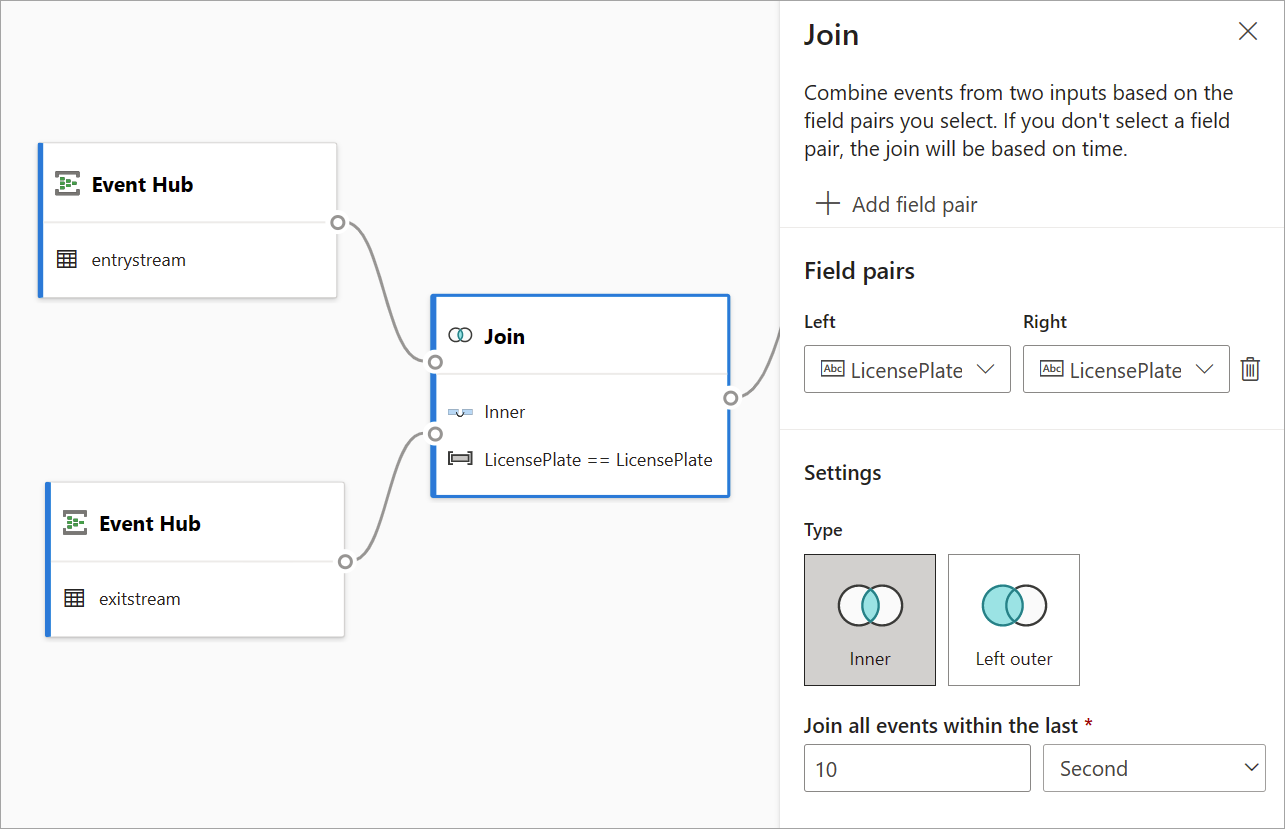
Deltag
Brug transformationen Joinforbindelse til at kombinere hændelser fra to input baseret på de feltpar, du vælger. Hvis du ikke vælger et feltpar, er joinforbindelsen som standard baseret på klokkeslæt. Standarden er det, der adskiller denne transformation fra en batch.
Som med almindelige joinforbindelser har du forskellige muligheder for din joinlogik:
- Indre joinforbindelse: Medtag kun poster fra begge tabeller, hvor parret stemmer overens. I dette eksempel er det her, at licenspladen matcher begge input.
- Venstre ydre joinforbindelse: Medtag alle poster fra venstre (første) tabel og kun de poster fra den anden, der svarer til felternes par. Hvis der ikke er et match, angives felterne fra det andet input som tomme.
Hvis du vil vælge typen af joinforbindelse, skal du vælge ikonet for den foretrukne type i sideruden.
Til sidst skal du vælge, hvilken tidsperiode joinforbindelsen skal beregnes for. I dette eksempel ser joinforbindelsen på de sidste 10 sekunder. Vær opmærksom på, at jo længere perioden er, jo mindre hyppig er outputtet – og jo flere behandlingsressourcer, du bruger til transformationen.
Alle felter fra begge tabeller er som standard inkluderet. Præfikser til venstre (første node) og højre (anden node) i outputtet hjælper dig med at differentiere kilden.
Gruppér efter
Brug transformationen Gruppér efter til at beregne sammenlægninger på tværs af alle hændelser inden for et bestemt tidsvindue. Du kan gruppere efter værdierne i et eller flere felter. Det svarer til transformationen Aggregering, men giver flere muligheder for sammenlægninger. Den indeholder også mere komplekse indstillinger for tidsvinduer. Du kan også tilføje mere end én aggregering pr. transformation på samme måde som aggregering.
De tilgængelige sammenlægninger i denne transformation er: Average, Count, Maximum, Minimum, Percentile (fortløbende og diskret), Standardafvigelse, Sum og Varians.
Sådan konfigurerer du denne transformation:
- Vælg din foretrukne aggregering.
- Vælg det felt, du vil aggregere på.
- Vælg et valgfrit gruppér efter-felt, hvis du vil have den aggregerede beregning over en anden dimension eller kategori (f.eks. State).
- Vælg din funktion til tidsvinduer.
Hvis du vil føje endnu en aggregering til den samme transformation, skal du vælge Tilføj aggregeringsfunktion. Vær opmærksom på, at feltet Gruppér efter og vinduesfunktionen gælder for alle sammenlægninger i transformationen.
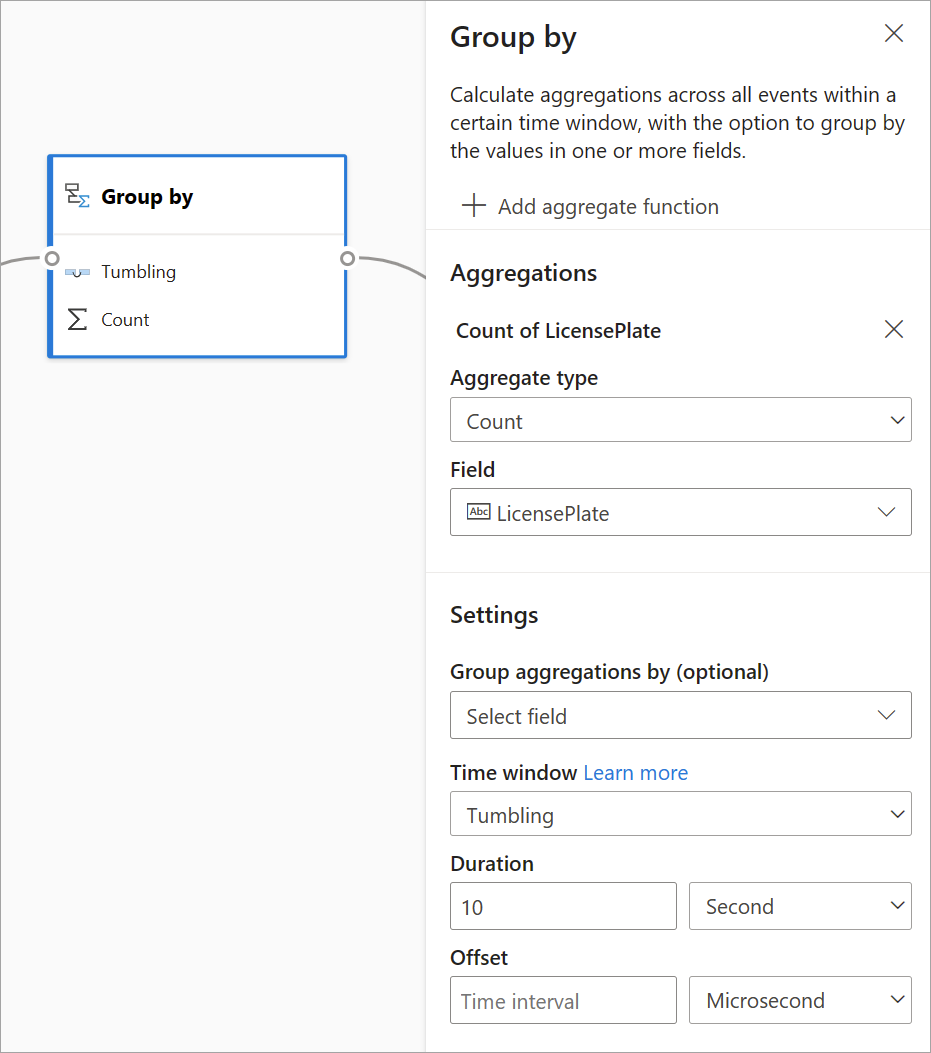
Der angives et tidsstempel for slutningen af tidsvinduet som en del af transformationsoutputtet som reference.
I et afsnit senere i denne artikel forklares hver type tidsvindue, der er tilgængeligt for denne transformation.
Fagforening
Brug transformationen Union til at forbinde to eller flere input for at føje hændelser med delte felter (med samme navn og datatype) til én tabel. Felter, der ikke stemmer overens, slippes og medtages ikke i outputtet.
Konfigurer funktioner for tidsvinduer
Tidsvinduer er et af de mest komplekse begreber i streamingdata. Dette koncept er kernen i streaminganalyse.
Med streamingdataflow kan du konfigurere tidsvinduer, når du aggregerer data som en mulighed for transformationen Gruppér efter .
Bemærk
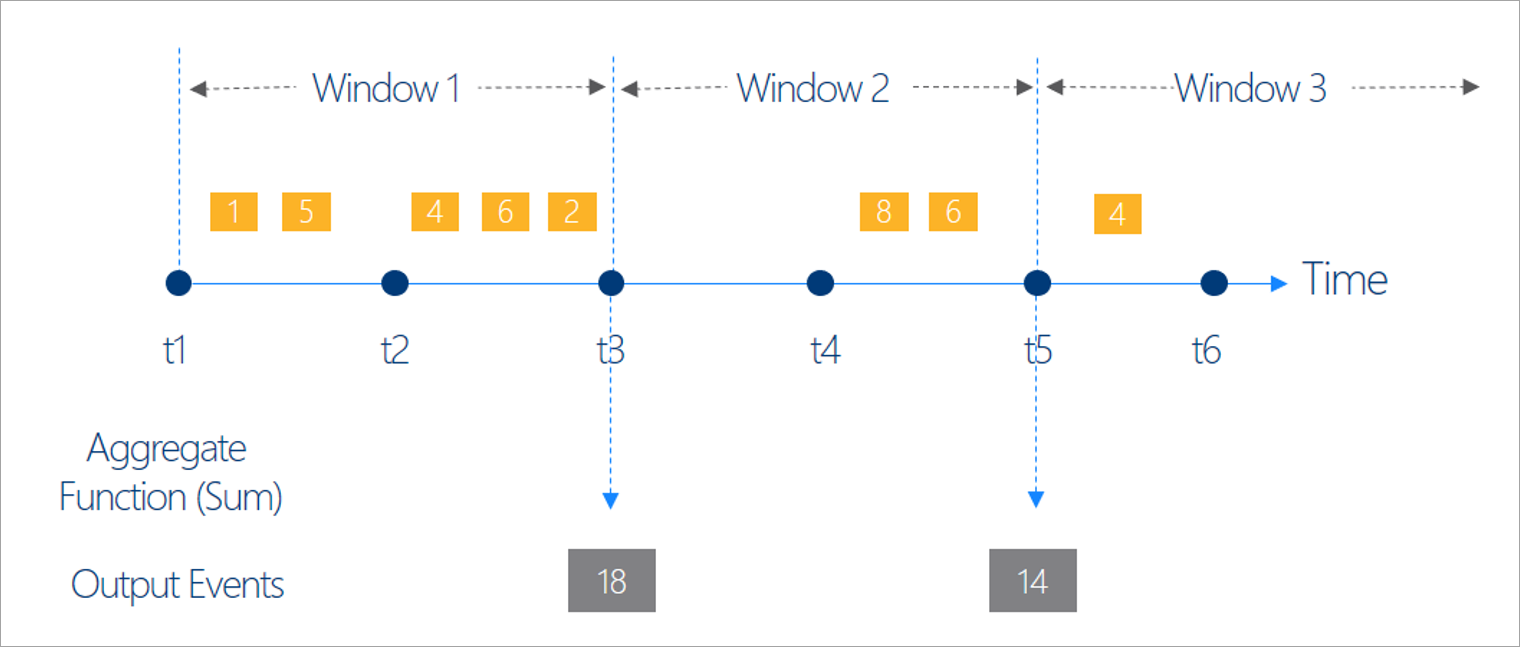
Vær opmærksom på, at alle outputresultaterne for vindueshandlinger beregnes i slutningen af tidsvinduet. Outputtet af vinduet vil være en enkelt hændelse, der er baseret på aggregeringsfunktionen. Denne hændelse har tidsstemplet for slutningen af vinduet, og alle vinduesfunktioner er defineret med en fast længde.
Der er fem slags tidsvinduer at vælge imellem: tumbling, hopping, glidende, session og snapshot.
Tumbling-vindue
Tumbling er den mest almindelige type tidsvindue. De vigtigste egenskaber ved tumbling vinduer er, at de gentager, har samme tidslængde og ikke overlapper hinanden. En hændelse kan ikke tilhøre mere end ét tumblingvindue.
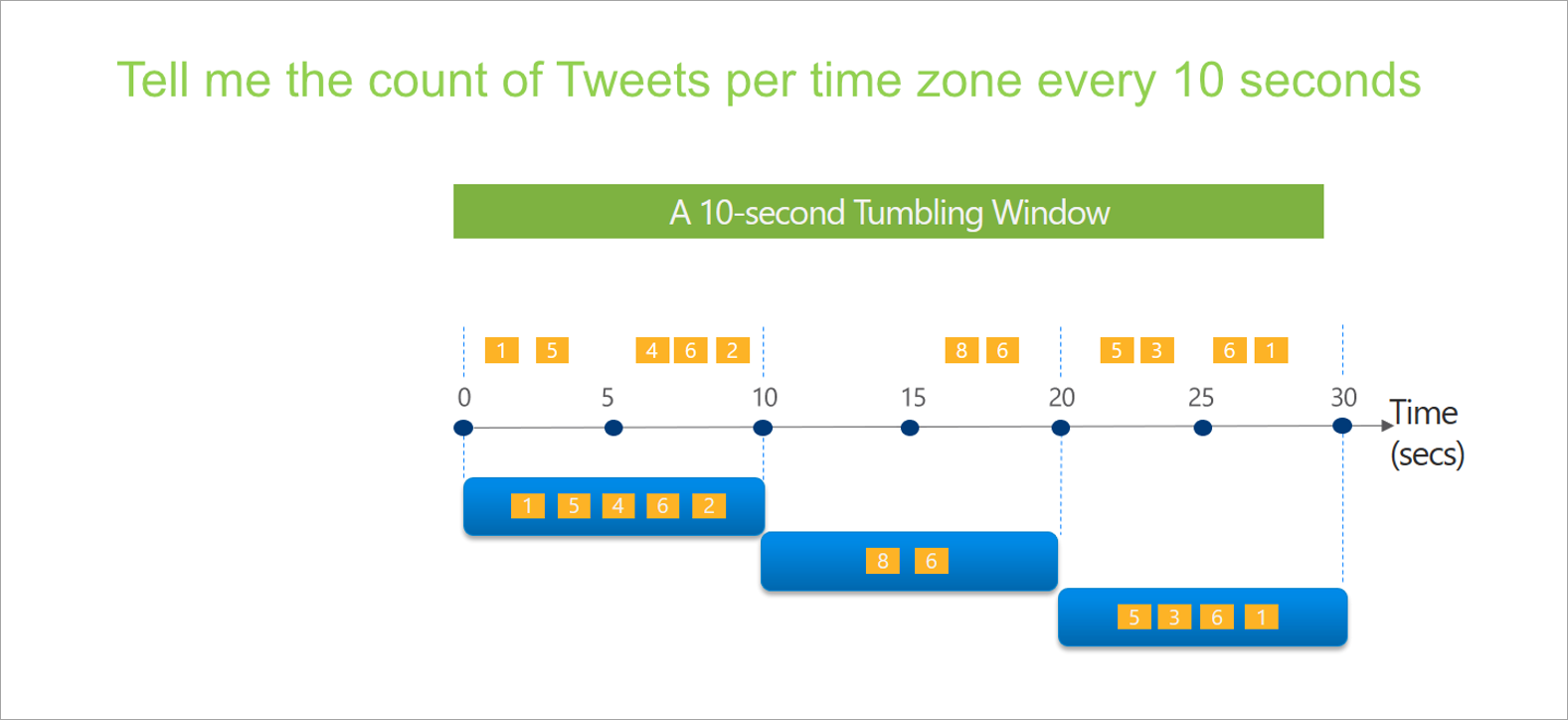
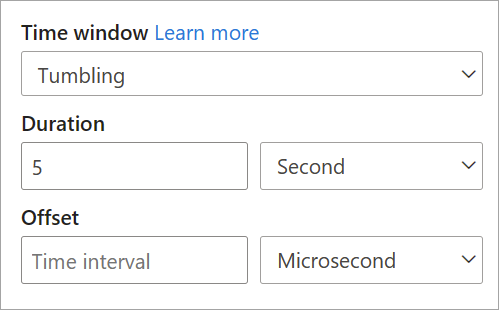
Når du konfigurerer et tumblingvindue i streamingdataflow, skal du angive vinduets varighed (det samme for alle vinduer i dette tilfælde). Du kan også angive en valgfri forskydning. Som standard inkluderer tumblingvinduer slutningen af vinduet og udelukker starten. Du kan bruge denne parameter til at ændre denne funktionsmåde og inkludere hændelserne i starten af vinduet og udelade dem i sidste ende.
Vinduet Hopping
Hopping vinduer "hop" fremad i tiden med en fast periode. Du kan tænke på dem som tumbling vinduer, der kan overlappe og udsendes oftere end vinduets størrelse. Hændelser kan tilhøre mere end ét resultatsæt for et hoppingvindue. Hvis du vil gøre et hoppingvindue til det samme som et tumblingvindue, kan du angive, at hopstørrelsen skal være den samme som vinduesstørrelsen.
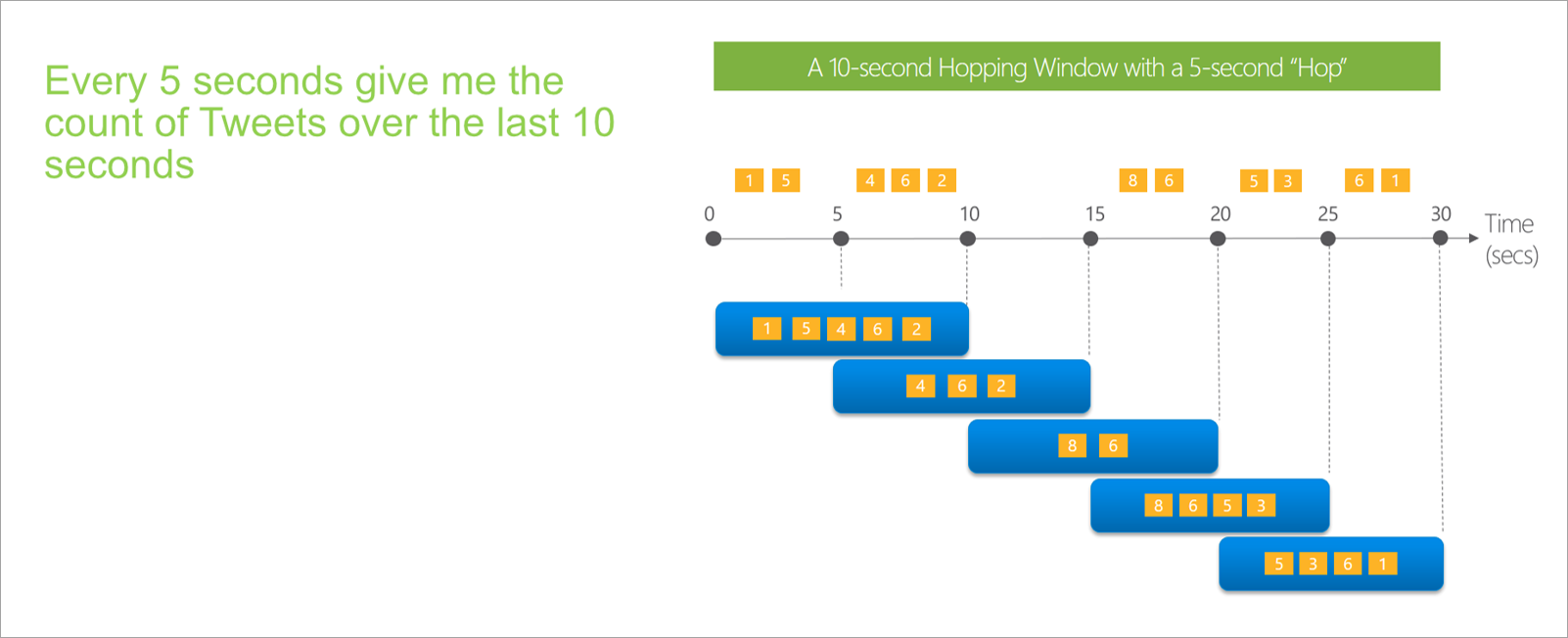
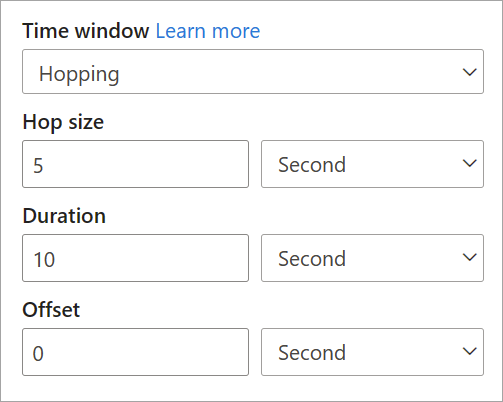
Når du konfigurerer et hoppingvindue i streamingdataflow, skal du angive vinduets varighed (samme som med tumblingvinduer). Du skal også angive hopstørrelsen, som fortæller streamingdataflows, hvor ofte sammenlægningen skal beregnes for den definerede varighed.
Parameteren offset er også tilgængelig i hoppevinduer af samme årsag som i tumblingvinduer. Den definerer logikken for at inkludere og udelade hændelser for starten og slutningen af vinduet hopping.
Skydevindue
Skydevinduer, i modsætning til tumbling- eller hoppingvinduer, beregner kun sammenlægningen for punkter i tiden, hvor indholdet af vinduet faktisk ændres. Når en hændelse kommer ind i eller lukker vinduet, beregnes sammenlægningen. Så hvert vindue har mindst én hændelse. På samme måde som med hoppingvinduer kan hændelser tilhøre mere end ét skydevindue.
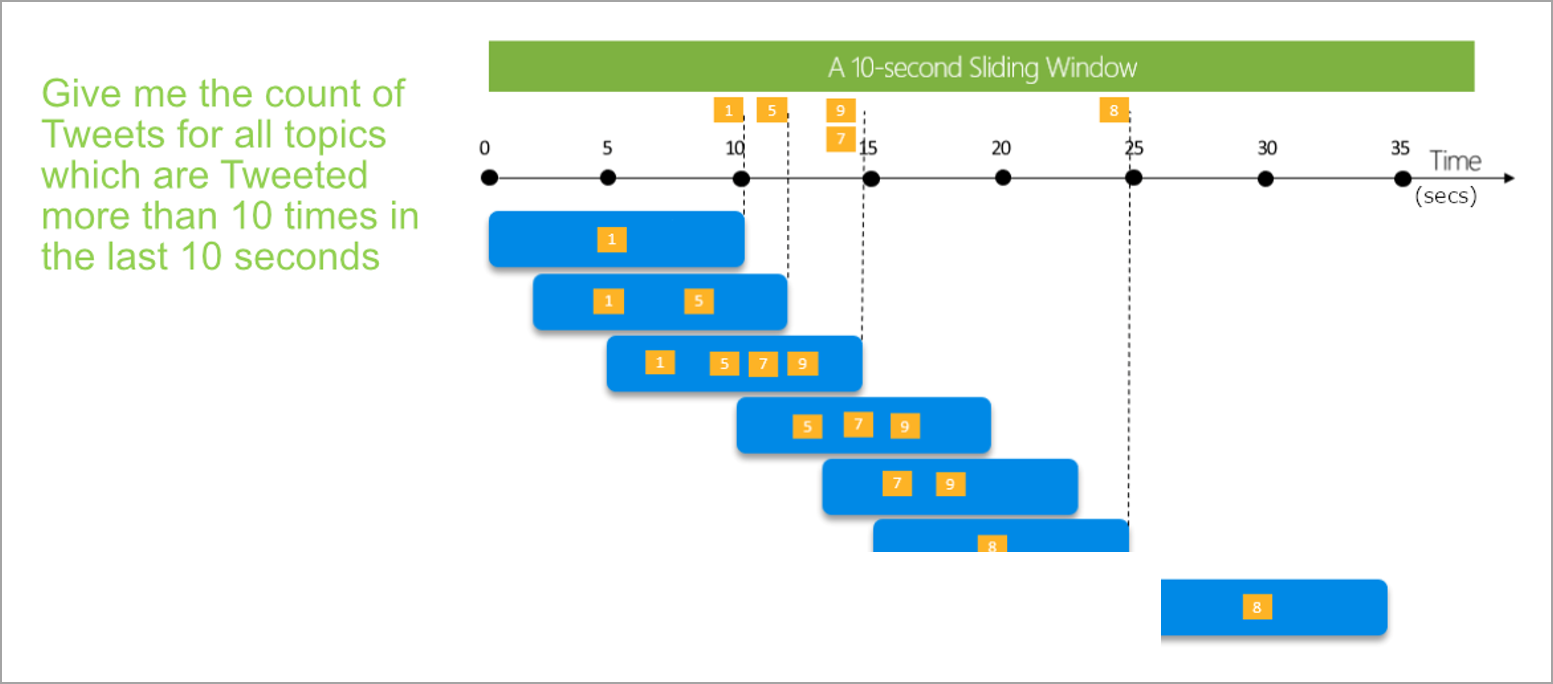
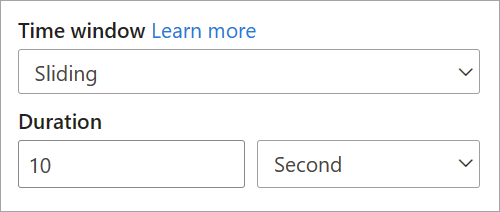
Den eneste parameter, du skal bruge til et glidende vindue, er varigheden, fordi hændelserne selv definerer, hvornår vinduet starter. Ingen forskydningslogik er nødvendig.
Sessionsvindue
Sessionsvinduer er den mest komplekse type. De grupperer hændelser, der ankommer på lignende tidspunkter, og filtrerer tidsperioder, hvor der ikke er nogen data. I dette vindue er det nødvendigt at angive:
- Timeout: Hvor lang tid der skal ventes, hvis der ikke er nye data.
- En maksimal varighed: Den længste tid, som aggregeringen beregner, hvis dataene bliver ved med at komme.
Du kan også definere en partition, hvis du vil.
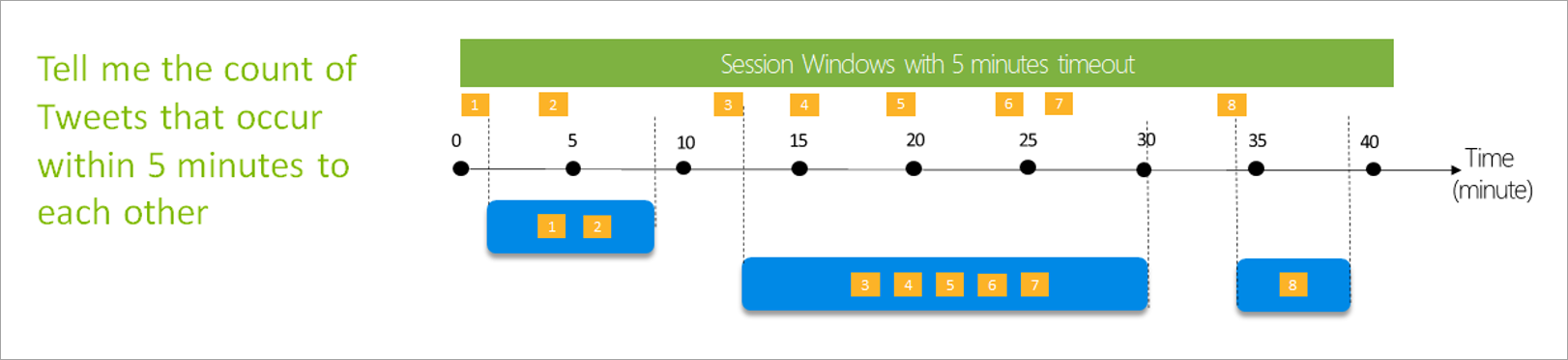
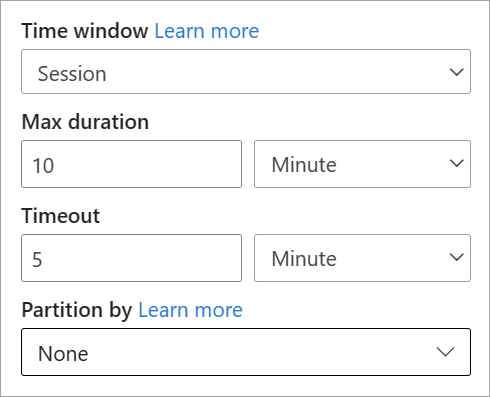
Du kan konfigurere et sessionsvindue direkte i sideruden for transformationen. Hvis du angiver en partition, grupperer sammenlægningen kun hændelser for den samme nøgle.
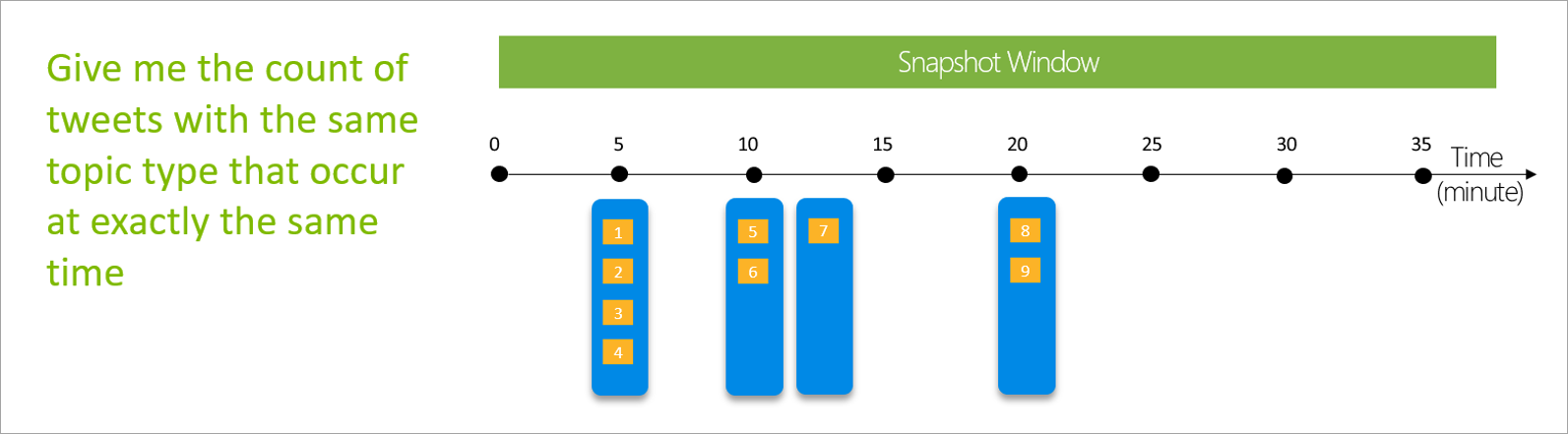
Vinduet Snapshot
Snapshot af windows-gruppehændelser, der har samme tidsstempel. I modsætning til andre vinduer kræver et snapshot ikke nogen parametre, fordi det bruger tiden fra systemet.
Definer output
Når du har konfigureret input og transformationer, er det tid til at definere et eller flere output. Fra og med juli 2021 understøtter streamingdataflow Power BI-tabeller som den eneste type output.
Dette output er en dataflowtabel (dvs. et objekt), som du kan bruge til at oprette rapporter i Power BI Desktop. Du skal forbinde noderne i det forrige trin med det output, du opretter, for at få det til at fungere. Derefter skal du navngive tabellen.
Når du har oprettet forbindelse til dit dataflow, vil denne tabel være tilgængelig for dig, så du kan oprette visualiseringer, der opdateres i realtid for dine rapporter.
Dataeksempel og fejl
Streamingdataflow indeholder værktøjer, der kan hjælpe dig med at oprette, foretage fejlfinding og evaluere ydeevnen af din analysepipeline til streaming af data.
Eksempelvisning af livedata for input
Når du opretter forbindelse til en begivenhedshub eller IoT-hub og vælger dens kort i diagramvisningen ( fanen Dataeksempel ), får du en direkte forhåndsvisning af data, der kommer ind, hvis alle følgende er sande:
- Data pushes.
- Inputtet er konfigureret korrekt.
- Der er tilføjet felter.
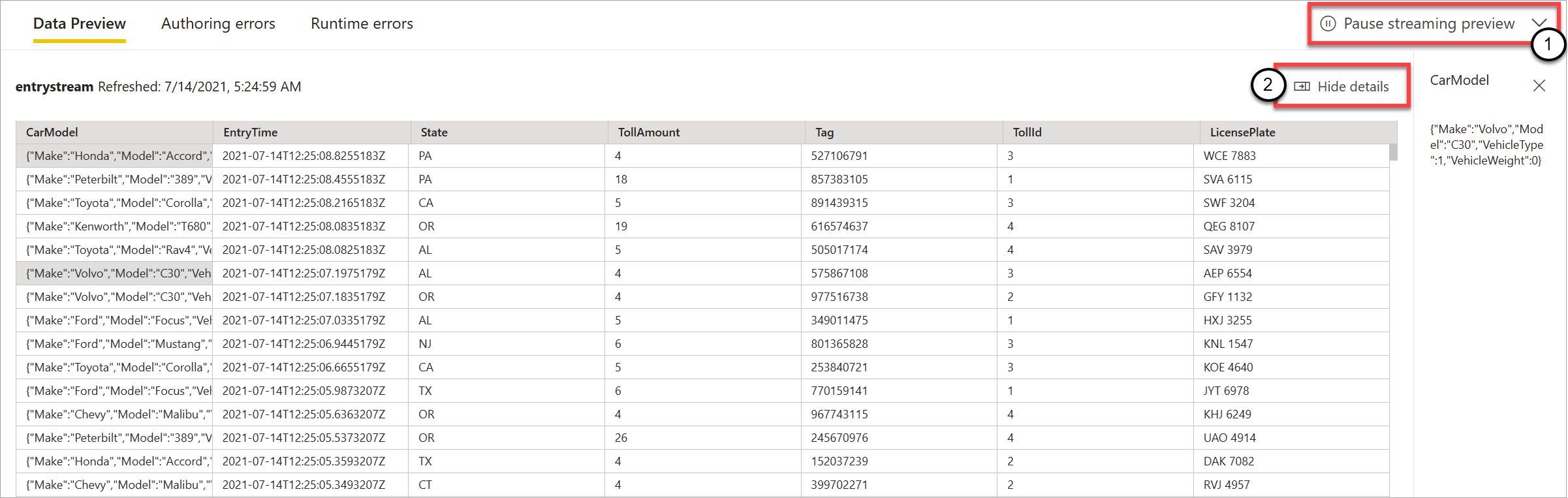
Som vist på følgende skærmbillede kan du afbryde prøveversionen (1), hvis du vil se eller foretage detailudledning i noget bestemt. Eller du kan starte det igen, hvis du er færdig.
Du kan også se detaljerne for en bestemt post (en "celle" i tabellen) ved at markere den og derefter vælge Vis detaljer eller Skjul detaljer (2). Skærmbilledet viser den detaljerede visning af et indlejret objekt i en post.
Statisk eksempelvisning af transformationer og output
Når du har tilføjet og konfigureret trin i diagramvisningen, kan du teste deres funktionsmåde ved at vælge knappen statiske data.

Når du har gjort det, evaluerer streamingdataflow alle transformationer og output, der er konfigureret korrekt. Streaming af dataflow viser derefter resultaterne i eksempelvisningen af statiske data som vist på følgende billede.
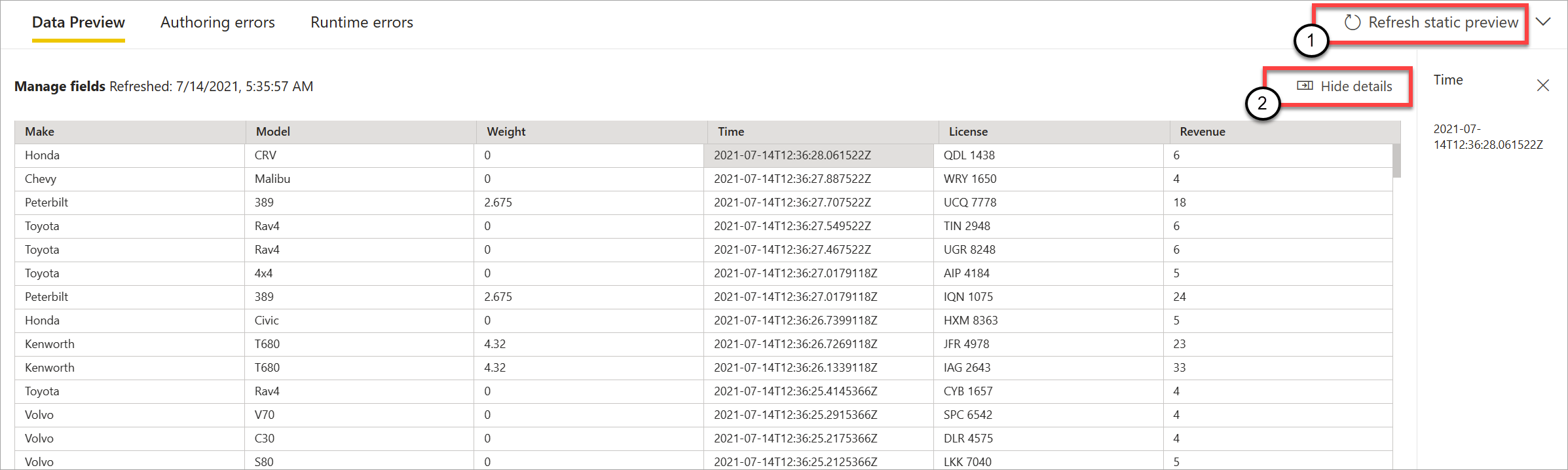
Du kan opdatere eksempelvisningen ved at vælge Opdater statisk prøveversion (1). Når du gør dette, tager streamingdataflow nye data fra inputtet og evaluerer alle transformationer og output igen med eventuelle opdateringer, som du kan udføre. Indstillingen Vis eller skjul detaljer er også tilgængelig (2).
Oprettelsesfejl
Hvis du har oprettelsesfejl eller -advarsler, viser fanen Oprettelsesfejl (1) dem som vist på følgende skærmbillede. Listen indeholder oplysninger om fejlen eller advarslen, typen af kort (input, transformation eller output), fejlniveauet og en beskrivelse af fejlen eller advarslen (2). Når du vælger en af fejlene eller advarslerne, vælges det pågældende kort, og ruden på konfigurationssiden åbnes, så du kan foretage de nødvendige ændringer.

Kørselsfejl
Den sidste tilgængelige fane i prøveversionen er Kørselsfejl (1), som vist på følgende skærmbillede. Under denne fane vises eventuelle fejl i processen med at indtage og analysere streamingdataflowet, når du har startet det. Du kan f.eks. få vist en kørselsfejl, hvis en meddelelse blev beskadiget, og dataflowet ikke kunne indtage det og udføre de definerede transformationer.
Da dataflow kan køre i lang tid, giver denne fane mulighed for at filtrere efter tidsperiode og downloade listen over fejl og opdatere den, hvis det er nødvendigt (2).

Rediger indstillinger for streaming af dataflow
Som med almindelige dataflow kan indstillingerne for streaming af dataflow ændres afhængigt af ejernes og forfatternes behov. Følgende indstillinger er entydige for streamingdataflow. I resten af indstillingerne kan du på grund af den delte infrastruktur mellem de to typer dataflow antage, at brugen er den samme.
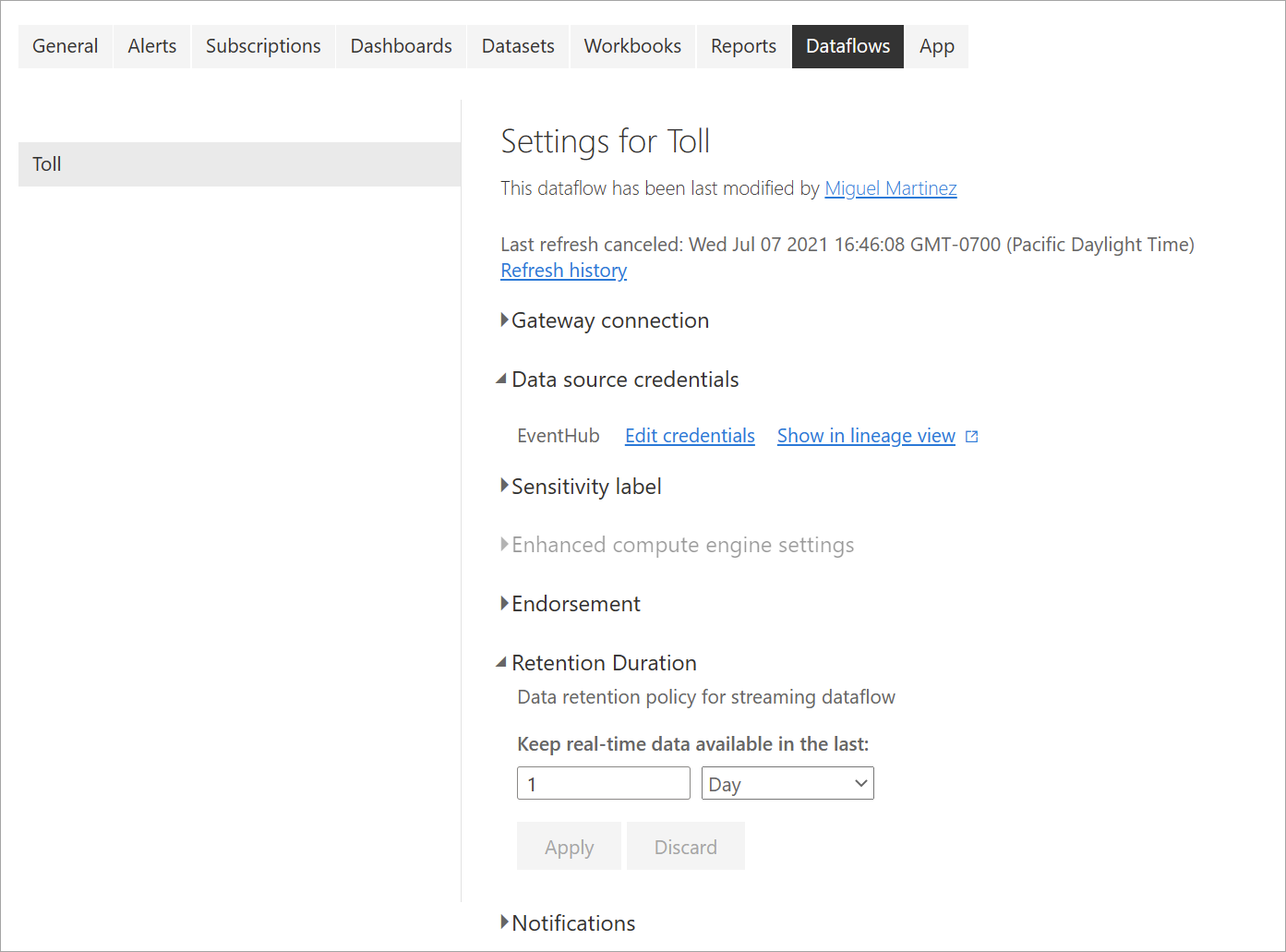
Opdateringshistorik: Da streamingdataflow kører løbende, viser opdateringshistorikken kun oplysninger om, hvornår dataflowet starter, hvornår det annulleres, eller hvornår det mislykkes (med oplysninger og fejlkoder, når det er relevant). Disse oplysninger svarer til, hvad der vises for almindelige dataflow. Du kan bruge disse oplysninger til at foretage fejlfinding af problemer eller til at give Power BI-support med de ønskede oplysninger.
Legitimationsoplysninger for datakilde: Denne indstilling viser de input, der er konfigureret for det specifikke streamingdataflow.
Forbedrede indstillinger for beregningsprogram: Streamingdataflow skal bruge det forbedrede beregningsprogram til at levere visualiseringer i realtid, så denne indstilling er slået til som standard og kan ikke ændres.
Opbevaringsvarighed: Denne indstilling er specifik for streamingdataflow. Her kan du definere, hvor længe du vil beholde data i realtid, så de kan visualiseres i rapporter. Historiske data gemmes som standard i Azure Blob Storage. Denne indstilling er specifik for realtidssiden af dine data (varmt lager). Minimumværdien er 1 dag eller 24 timer.
Vigtigt
Mængden af varme data, der gemmes af denne opbevaringsvarighed, påvirker direkte ydeevnen af dine visualiseringer i realtid, når du opretter rapporter oven på disse data. Jo mere opbevaring du har her, jo mere kan dine visualiseringer i realtid i rapporter påvirkes af lav ydeevne. Hvis du har brug for at udføre historiske analyser, skal du bruge det kolde lager, der er angivet til streaming af dataflow.
Kør og rediger et streamingdataflow
Når du har gemt og konfigureret dit streamingdataflow, er alt klar til at køre det. Du kan derefter begynde at indtage data i Power BI med den streaminganalyselogik, du har defineret.
Kør dit streamingdataflow
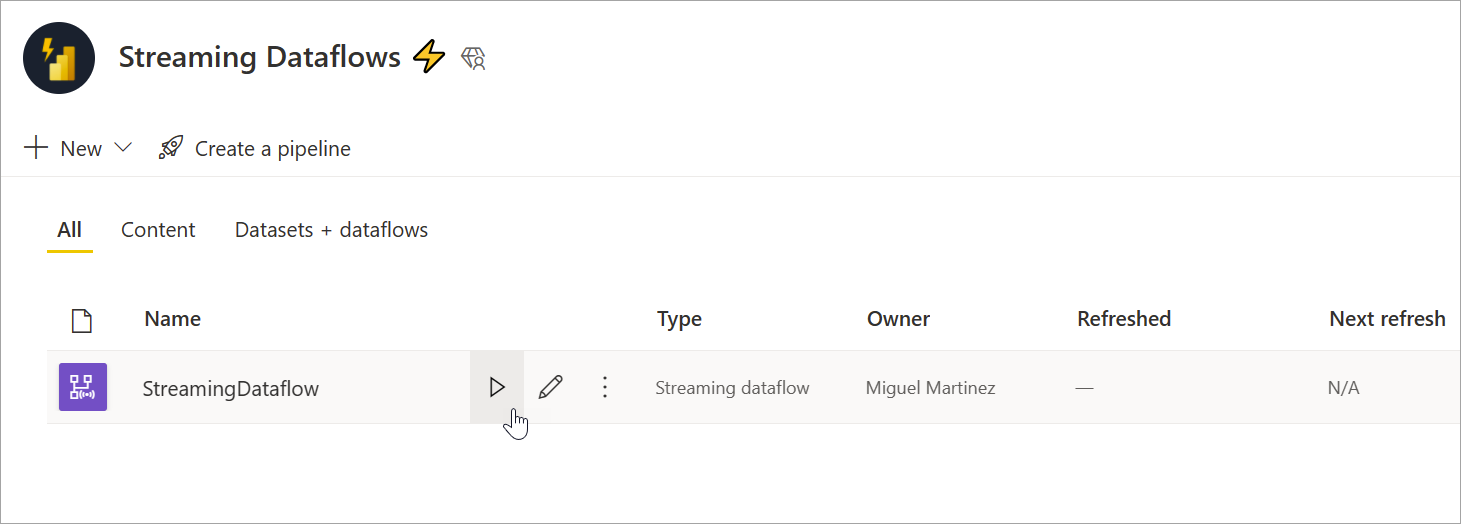
Hvis du vil starte dit streamingdataflow, skal du først gemme dit dataflow og gå til det arbejdsområde, hvor du oprettede det. Peg på streamingdataflowet, og vælg den afspilningsknap, der vises. En pop op-meddelelse fortæller dig, at streamingdataflowet startes.
Bemærk
Det kan tage op til fem minutter, før data begynder at blive indtaget, og at du kan se data, der kommer ind, for at oprette rapporter og dashboards i Power BI Desktop.
Rediger dit streamingdataflow
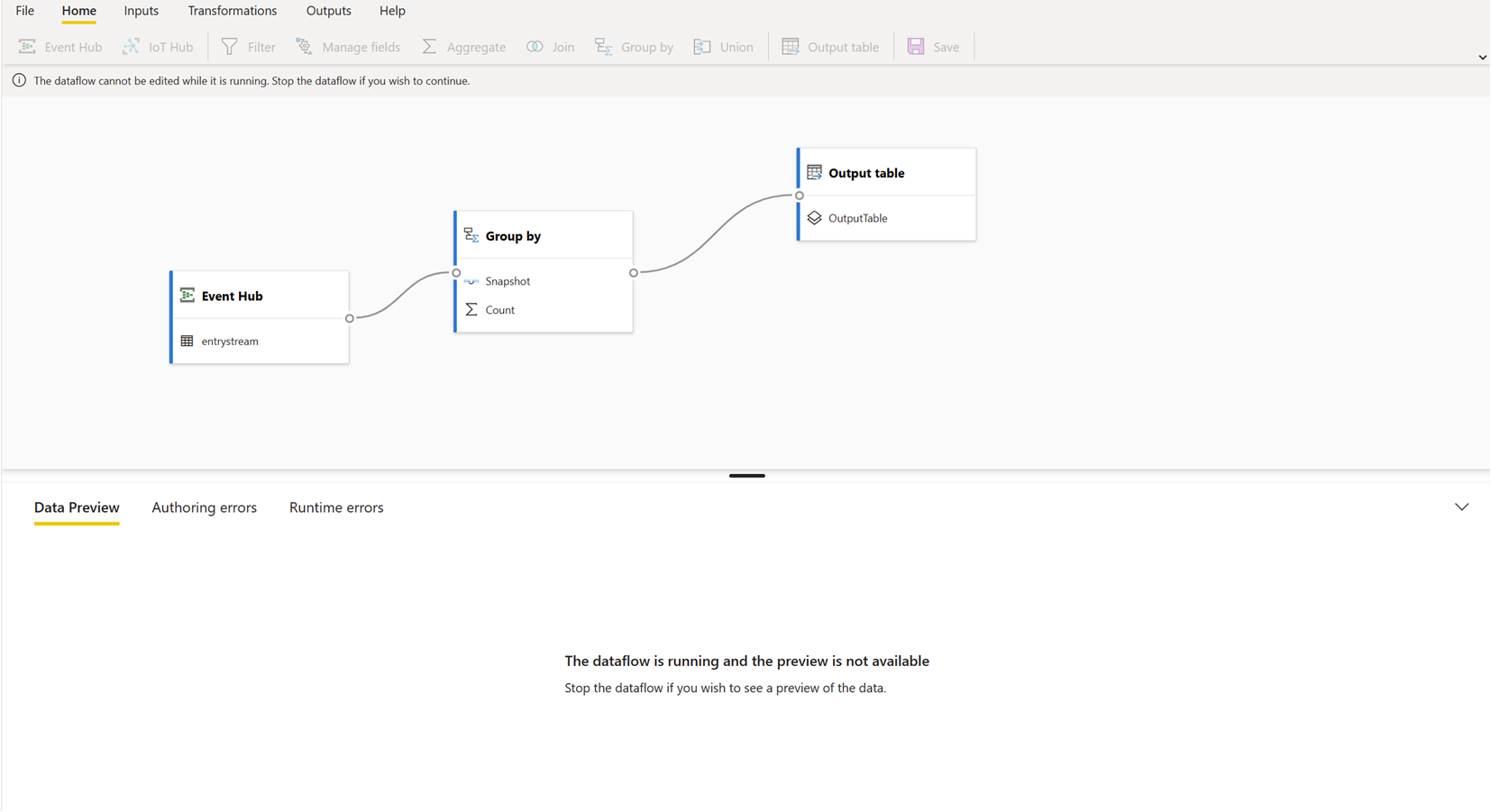
Mens der kører et streamingdataflow, kan det ikke redigeres. Men du kan gå ind i et streamingdataflow, der kører, og se den analyselogik, som dataflowet er bygget på.
Når du går ind i et kørende streamingdataflow, deaktiveres alle redigeringsindstillinger, og der vises en meddelelse: "Dataflowet kan ikke redigeres, mens det kører. Stop dataflowet, hvis du vil fortsætte." Dataeksemplet er også deaktiveret.
Hvis du vil redigere dit streamingdataflow, skal du stoppe det. Et stoppet dataflow resulterer i manglende data.
Den eneste tilgængelige oplevelse, mens et streamingdataflow kører, er fanen Kørselsfejl , hvor du kan overvåge dataflowets funktionsmåde for alle mistede meddelelser og lignende situationer.
Overvej datalager, når du redigerer dit dataflow
Når du redigerer et dataflow, skal du tage højde for andre overvejelser. På samme måde som med eventuelle ændringer i et skema for almindelige dataflow, mister du data, der allerede er pushet og gemt i Power BI, hvis du foretager ændringer i en outputtabel. Grænsefladen indeholder tydelige oplysninger om konsekvenserne af disse ændringer i dit streamingdataflow sammen med valg af ændringer, du foretager, før du gemmer.
Denne oplevelse er bedre vist med et eksempel. På følgende skærmbillede vises den meddelelse, du får, når du føjer en kolonne til én tabel, ændrer navnet på en anden tabel og lader en tredje tabel være den samme som før.

I dette eksempel slettes de data, der allerede er gemt i begge tabeller, og som havde skema- og navneændringer, hvis du gemmer ændringerne. For den tabel, der forblev den samme, får du mulighed for at slette gamle data og starte fra bunden eller gemme dem til senere analyse sammen med nye data, der kommer ind.
Vær opmærksom på disse nuancer, når du redigerer dit streamingdataflow, især hvis du har brug for historiske data, der er tilgængelige senere til yderligere analyse.
Forbrug et streamingdataflow
Når dit streamingdataflow kører, er du klar til at begynde at oprette indhold oven på dine streamingdata. Der er ingen strukturelle ændringer sammenlignet med, hvad du skal gøre for at oprette rapporter, der opdateres i realtid. Der er nogle nuancer og opdateringer, du skal overveje, så du kan drage fordel af denne nye type dataforberedelse til streamingdata.
Konfigurer datalager
Som vi nævnte før, gemmer streamingdataflow data på følgende to placeringer. Brugen af disse kilder afhænger af, hvilken type analyse du forsøger at foretage.
- Hot storage (analyse i realtid): Når data kommer ind i Power BI fra streaming af dataflow, gemmes data et varmt sted, hvor du kan få adgang til dem med visualiseringer i realtid. Hvor mange data der gemmes i dette lager, afhænger af den værdi, du har defineret for Opbevaringsvarighed i indstillingerne for streamingdataflow. Standarden (og minimum) er 24 timer.
- Koldt lager (historisk analyse): Enhver tidsperiode, der ikke falder i den periode, du har defineret for opbevaringsvarighed , gemmes i kølelager (blobs) i Power BI, så du kan forbruge, hvis det er nødvendigt.
Bemærk
Der er overlapning mellem disse to datalagerplaceringer. Hvis du har brug for at bruge begge placeringer sammen (f.eks. procentvis ændring i dag-for-dag), skal du muligvis deduplicere dine poster. Det afhænger af de time intelligence-beregninger, du foretager, og opbevaringspolitikken.
Opret forbindelse til streamingdataflow fra Power BI Desktop
Power BI Desktop indeholder en connector kaldet Dataflow, som du kan bruge. Som en del af denne connector til streaming af dataflow kan du se to tabeller, der svarer til det tidligere beskrevne datalager.
Sådan opretter du forbindelse til dine data til streamingdataflow:
Gå til Hent data, vælg Power Platform, og vælg derefter connectoren Dataflows .
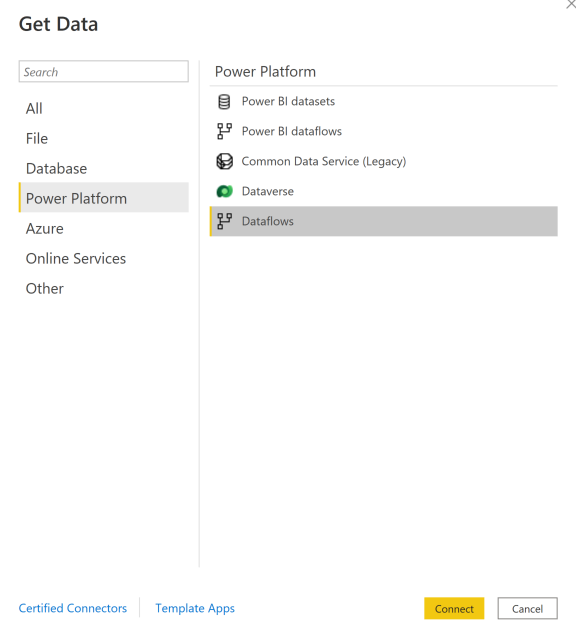
Log på med dine Power BI-legitimationsoplysninger.
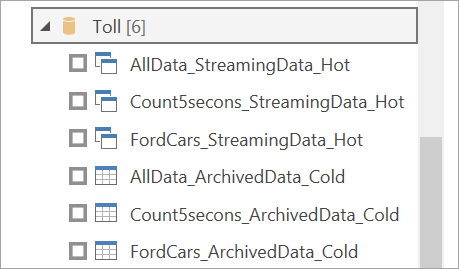
Vælg arbejdsområder. Søg efter det, der indeholder dit streamingdataflow, og vælg det pågældende dataflow. (I dette eksempel kaldes streamingdataflowetAfgiftsbelagt.
Bemærk, at alle outputtabeller vises to gange: én til streaming af data (varm) og en til arkiverede data (kold). Du kan skelne mellem dem ved hjælp af de navne, der tilføjes efter tabelnavnene og af ikonerne.
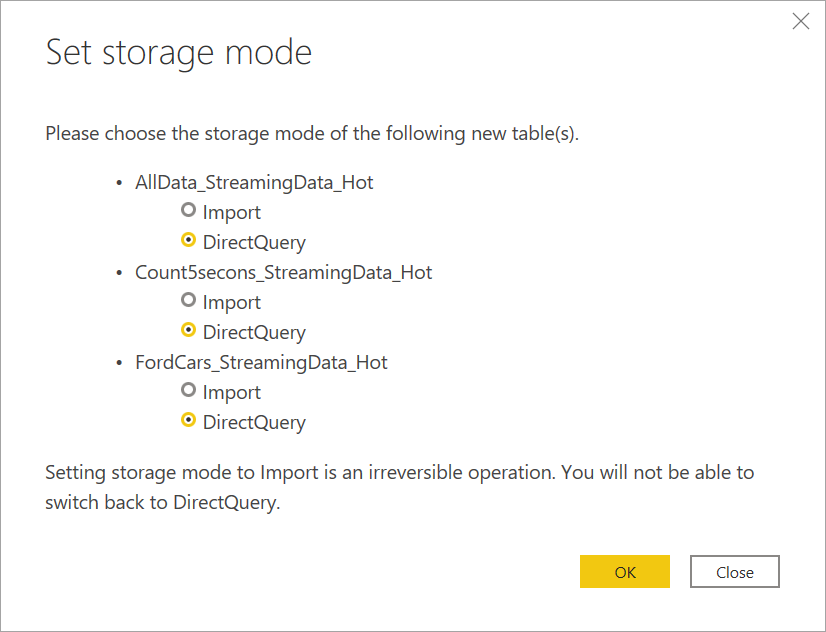
Opret forbindelse til streamingdataene. Den arkiverede datacase er den samme, og den er kun tilgængelig i importtilstand. Vælg de tabeller, der indeholder mærkaterne Streaming og Hot, og vælg derefter Indlæs.
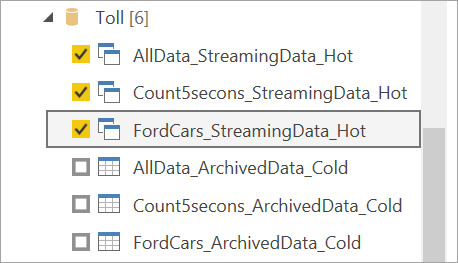
Når du bliver bedt om at vælge en lagringstilstand, skal du vælge DirectQuery , hvis dit mål er at oprette visualiseringer i realtid.
Nu kan du oprette visualiseringer, målinger og meget mere ved hjælp af de funktioner, der er tilgængelige i Power BI Desktop.
Bemærk
Den almindelige Power BI-dataflowconnector er stadig tilgængelig og fungerer sammen med streamingdataflow med to advarsler:
- Det giver dig kun mulighed for at oprette forbindelse til varmt lager.
- Dataeksemplet i connectoren fungerer ikke sammen med streamingdataflow.
Slå automatisk sideopdatering til for visualiseringer i realtid
Når din rapport er klar, og du har tilføjet alt det indhold, du vil dele, er det eneste trin tilbage at sikre, at dine visualiseringer opdateres i realtid. Du kan bruge en funktion, der kaldes automatisk sideopdatering. Denne funktion giver dig mulighed for at opdatere visualiseringer fra en DirectQuery-kilde så ofte som et sekund.
Du kan få flere oplysninger om funktionen under Automatisk sideopdatering i Power BI. Denne artikel indeholder oplysninger om, hvordan du bruger den, hvordan du konfigurerer den, og hvordan du kontakter din administrator, hvis du har problemer. Følgende er de grundlæggende oplysninger om, hvordan du konfigurerer det:
Gå til den rapportside, hvor visualiseringerne skal opdateres i realtid.
Ryd alle visualiseringer på siden. Hvis det er muligt, skal du vælge sidens baggrund.
Gå til formatruden (1), og slå Sideopdatering til (2).
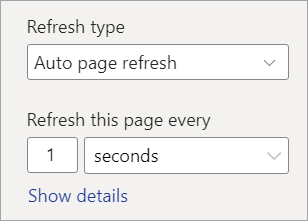
Konfigurer den ønskede frekvens (op til hvert sekund, hvis din administrator har tilladt det).
Hvis du vil dele en rapport i realtid, skal du først publicere tilbage til Power BI-tjeneste. Derefter kan du konfigurere dine legitimationsoplysninger for dataflowet for den semantiske model og dele.
Tip
Hvis din rapport ikke opdateres så hurtigt, som du har brug for det, eller i realtid, skal du se dokumentationen for automatisk sideopdatering. Følg ofte stillede spørgsmål og fejlfindingsvejledningen for at finde ud af, hvorfor problemet kan opstå.
Overvejelser og begrænsninger
Generelle begrænsninger
- Der kræves et Power BI Premium-abonnement (kapacitet eller Premium pr. bruger) for at oprette og køre streamingdataflow.
- Der må kun angives én type dataflow pr. arbejdsområde.
- Det er ikke muligt at sammenkæde almindelige dataflow og streame dataflow.
- Kapaciteter, der er mindre end A3, tillader ikke brug af streamingdataflow.
- Hvis dataflow eller det forbedrede beregningsprogram ikke er aktiveret i en lejer, kan du ikke oprette eller køre streamingdataflow.
- Arbejdsområder, der er forbundet til en lagerkonto, understøttes ikke.
- Hvert streamingdataflow kan levere op til 1 MB pr. sekund af dataoverførselshastigheden.
Tilgængelighed
Prøveversionen af streamingdataflow er ikke tilgængelig i følgende områder:
- Det centrale Indien
- Det nordlige Tyskland
- Det østlige Norge
- Det vestlige Norge
- Det centrale Forenede Arabiske Emirater
- Det nordlige Sydafrika
- Det vestlige Sydafrika
- Det nordlige Schweiz
- Det vestlige Schweiz
- Det sydøstlige Brasilien
Licenser
Antallet af tilladte streamingdataflow pr. lejer afhænger af den licens, der bruges:
For almindelige kapaciteter skal du bruge følgende formel til at beregne det maksimale antal streamingdataflow, der er tilladt i en kapacitet:
Maksimalt antal streamingdataflow pr. kapacitet = vCores i kapaciteten x 5
P1 har f.eks. 8 vCores: 8 * 5 = 40 streamingdataflows.
For Premium pr. bruger er ét streamingdataflow tilladt pr. bruger. Hvis en anden bruger vil bruge et streamingdataflow i et Premium pr. bruger-arbejdsområde, skal vedkommende også have en Premium pr. bruger-licens.
Oprettelse af dataflow
Når du opretter streamingdataflow, skal du være opmærksom på følgende:
- Ejeren af et streamingdataflow kan kun foretage ændringer, og de kan kun foretage ændringer, hvis dataflowet ikke kører.
- Streamingdataflow er ikke tilgængelige i Mit arbejdsområde.
Opret forbindelse fra Power BI Desktop
Du kan kun få adgang til koldt lager ved hjælp af den dataflowconnector, der er tilgængelig fra og med opdateringen af Power BI Desktop fra juli 2021. Den tidligere Power BI-dataflowconnector tillader kun forbindelser til lagring af streamingdata (varm). Connectorens dataeksempel fungerer ikke.
Relateret indhold
Denne artikel indeholdt en oversigt over selvbetjent forberedelse af streamingdata ved hjælp af streamingdataflow. Følgende artikler indeholder oplysninger om, hvordan du tester denne funktion, og hvordan du bruger andre streamingdatafunktioner i Power BI: