Scenarier med beregnede tabeller og use cases
Der er fordele ved at bruge beregnede tabeller i et dataflow. I denne artikel beskrives use cases for beregnede tabeller og beskriver, hvordan de fungerer i baggrunden.
Hvad er en beregnet tabel?
En tabel repræsenterer dataoutputtet for en forespørgsel, der er oprettet i et dataflow, efter at dataflowet er blevet opdateret. Den repræsenterer data fra en kilde og eventuelt de transformationer, der blev anvendt på den. Nogle gange kan det være en god idé at oprette nye tabeller, der er en funktion i en tidligere indtaget tabel.
Selvom det er muligt at gentage de forespørgsler, der oprettede en tabel, og anvende nye transformationer på dem, har denne fremgangsmåde ulemper: Data indtages to gange, og belastningen af datakilden fordobles.
Beregnede tabeller løser begge problemer. Beregnede tabeller ligner andre tabeller, da de henter data fra en kilde, og du kan anvende yderligere transformationer for at oprette dem. Men deres data stammer fra det anvendte lagerdataflow og ikke den oprindelige datakilde. Det vil altså være, at de tidligere blev oprettet af et dataflow og derefter genbrugt.
Beregnede tabeller kan oprettes ved at referere til en tabel i det samme dataflow eller ved at referere til en tabel, der er oprettet i et andet dataflow.

Hvorfor bruge en beregnet tabel?
Det kan være langsomt at udføre alle transformationstrin i én tabel. Der kan være mange årsager til denne nedgang – datakilden kan være langsom, eller de transformationer, du foretager, skal muligvis replikeres i to eller flere forespørgsler. Det kan være en fordel først at hente dataene fra kilden og derefter genbruge dem i en eller flere tabeller. I sådanne tilfælde kan du vælge at oprette to tabeller: én, der henter data fra datakilden, og en anden – en beregnet tabel – der anvender flere transformationer på data, der allerede er skrevet i den datasø, der bruges af et dataflow. Denne ændring kan øge ydeevnen og genbrug af data, hvilket sparer tid og ressourcer.
Hvis to tabeller f.eks. deler en del af deres transformationslogik uden en beregnet tabel, skal transformationen udføres to gange.
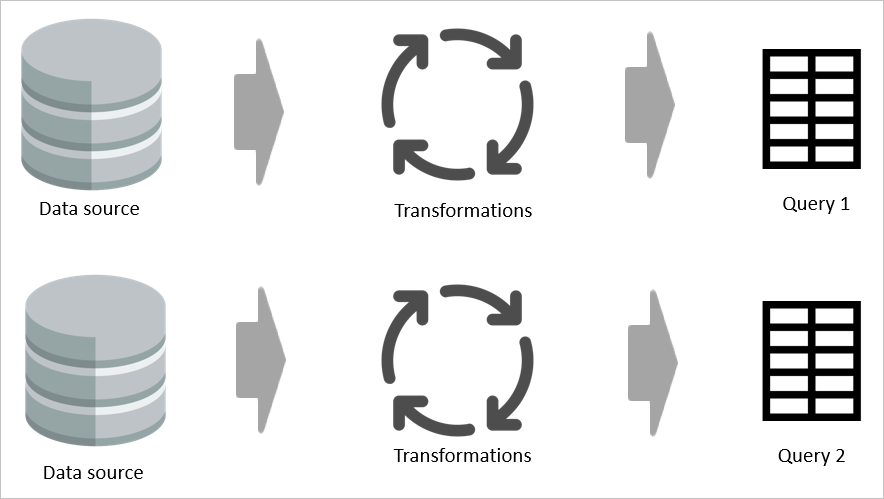
Men hvis der bruges en beregnet tabel, behandles den fælles (delte) del af transformationen én gang og gemmes i Azure Data Lake Storage. De resterende transformationer behandles derefter fra outputtet af den fælles transformation. Samlet set er denne behandling meget hurtigere.
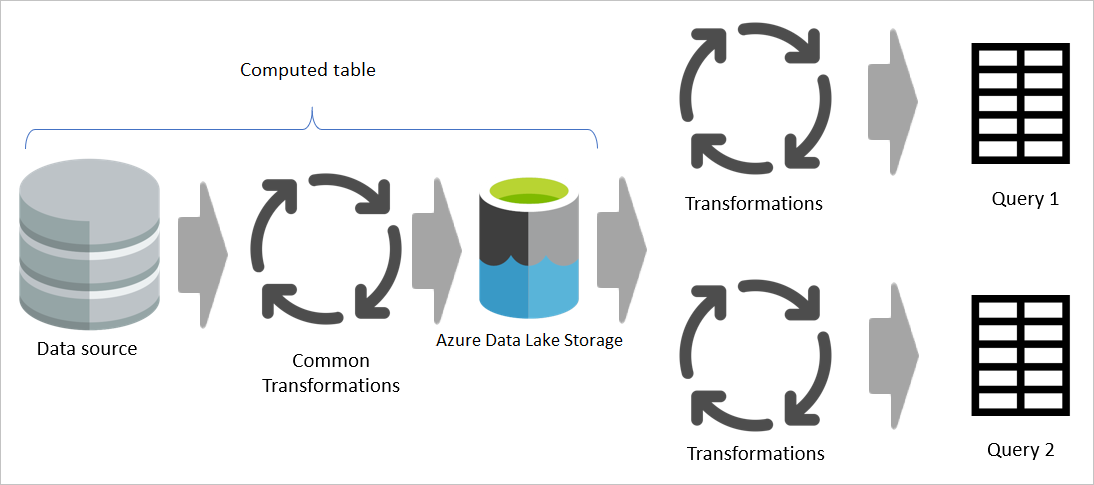
En beregnet tabel indeholder ét sted som kildekoden for transformationen og fremskynder transformationen, fordi den kun skal udføres én gang i stedet for flere gange. Belastningen af datakilden reduceres også.
Eksempelscenarie for brug af en beregnet tabel
Hvis du bygger en aggregeret tabel i Power BI for at fremskynde datamodellen, kan du oprette den aggregerede tabel ved at referere til den oprindelige tabel og anvende flere transformationer på den. Ved hjælp af denne fremgangsmåde behøver du ikke at replikere transformationen fra kilden (den del, der er fra den oprindelige tabel).
Følgende figur viser f.eks. tabellen Orders.

Ved hjælp af en reference fra denne tabel kan du oprette en beregnet tabel.
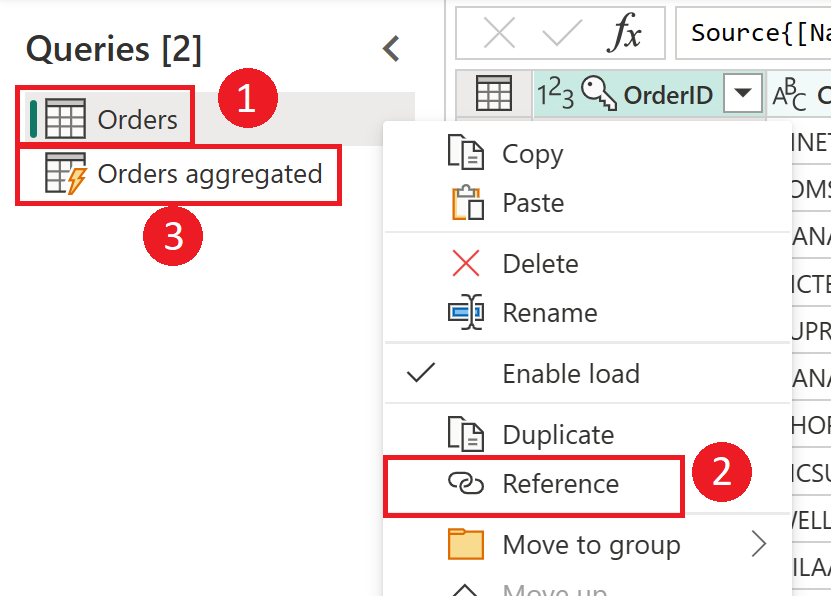
Skærmbillede, der viser, hvordan du opretter en beregnet tabel fra tabellen Orders. Højreklik først på tabellen Orders i ruden Forespørgsler, og vælg indstillingen Reference i rullemenuen. Denne handling opretter den beregnede tabel, som omdøbes her til Samlet ordre.
Den beregnede tabel kan have yderligere transformationer. Du kan f.eks. bruge Gruppér efter til at aggregere dataene på kundeniveau.
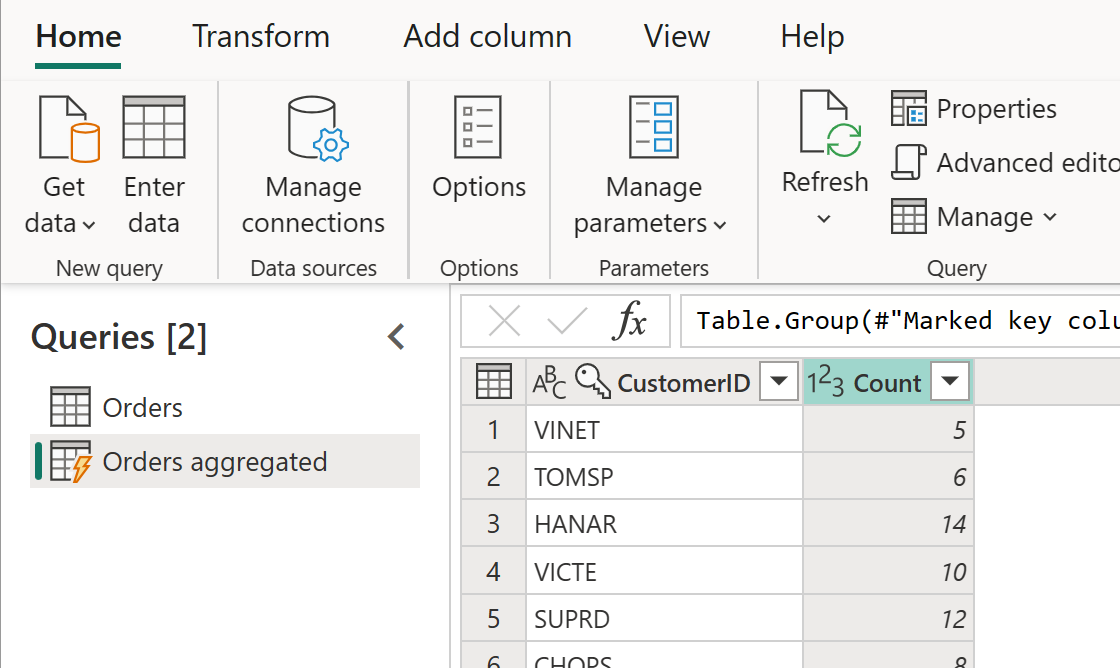
Det betyder, at tabellen Orders Aggregated henter data fra tabellen Orders og ikke fra datakilden igen. Da nogle af de transformationer, der skal udføres, allerede er udført i tabellen Orders, er ydeevnen bedre, og datatransformationen er hurtigere.
Beregnet tabel i andre dataflow
Du kan også oprette en beregnet tabel i andre dataflow. Den kan oprettes ved at hente data fra et dataflow med Microsoft Power Platform-dataflowconnectoren.
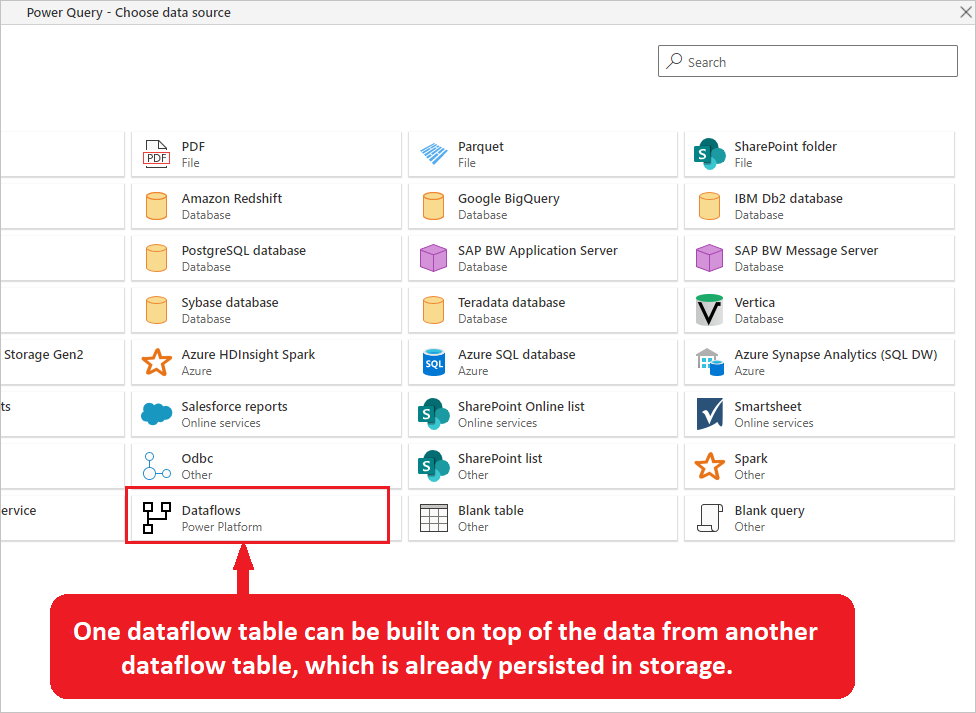
Billedet fremhæver Power Platform-dataflowconnectoren fra vinduet Vælg datakilde i Power Query. Inkluderet er også en beskrivelse, der angiver, at én dataflowtabel kan bygges oven på dataene fra en anden dataflowtabel, som allerede er permanent på lageret.
Begrebet beregnet tabel er at have en tabel på lager og andre tabeller, der hentes fra den, så du kan reducere læsetiden fra datakilden og dele nogle af de almindelige transformationer. Denne reduktion kan opnås ved at hente data fra andre dataflow via dataflowconnectoren eller referere til en anden forespørgsel i det samme dataflow.
Beregnet tabel: Med transformationer eller uden?
Nu, hvor du ved, at beregnede tabeller er gode til at forbedre ydeevnen af datatransformationen, er det et godt spørgsmål at stille, om transformationer altid skal udskydes til den beregnede tabel, eller om de skal anvendes på kildetabellen. Skal data altid indtages i én tabel og derefter transformeres i en beregnet tabel? Hvad er fordele og ulemper?
Indlæs data uden transformation for Tekst/CSV-filer
Når en datakilde ikke understøtter forespørgselsdelegering (f.eks. Tekst/CSV-filer), er der kun ringe fordel ved at anvende transformationer, når du henter data fra kilden, især hvis datamængderne er store. Kildetabellen skal blot indlæse data fra Text/CSV-filen uden at anvende transformationer. Derefter kan beregnede tabeller hente data fra kildetabellen og udføre transformationen oven på de indtagne data.
Du kan spørge, hvad er værdien af at oprette en kildetabel, der kun indtager data? En sådan tabel kan stadig være nyttig, fordi hvis dataene fra kilden bruges i mere end én tabel, reducerer den belastningen af datakilden. Derudover kan data nu genbruges af andre personer og dataflow. Beregnede tabeller er især nyttige i scenarier, hvor datamængden er stor, eller når en datakilde tilgås via en datagateway i det lokale miljø, fordi de reducerer trafikken fra gatewayen og belastningen af de underliggende datakilder.
Udføre nogle af de almindelige transformationer for en SQL-tabel
Hvis din datakilde understøtter forespørgselsdelegering, er det godt at udføre nogle af transformationerne i kildetabellen, fordi forespørgslen er foldet til datakilden, og kun de transformerede data hentes fra den. Disse ændringer forbedrer den overordnede ydeevne. Det sæt transformationer, der er almindelige i beregnede downstreamtabeller, skal anvendes i kildetabellen, så de kan foldes til kilden. Andre transformationer, der kun gælder for downstream-tabeller, skal udføres i beregnede tabeller.
Feedback
Kommer snart: I hele 2024 udfaser vi GitHub-problemer som feedbackmekanisme for indhold og erstatter det med et nyt feedbacksystem. Du kan få flere oplysninger under: https://aka.ms/ContentUserFeedback.
Indsend og få vist feedback om