Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Afhængigt af din datakilde kan oplysninger om datatyper og kolonnenavne være angivet eksplicit. OData REST API'er håndterer typisk dette ved hjælp af definitionen $metadata, og Power Query-metoden OData.Feed håndterer automatisk fortolkning af disse oplysninger og anvendelse på de data, der returneres fra en OData-kilde.
Mange REST API'er har ikke mulighed for at bestemme deres skema programmeringsmæssigt. I disse tilfælde skal du inkludere en skemadefinition i din connector.
Enkel hardcoded tilgang
Den nemmeste metode er at hardcode en skemadefinition i din connector. Dette er tilstrækkeligt til de fleste use cases.
Samlet set har gennemtvingelse af et skema på de data, der returneres af din connector, flere fordele, f.eks.:
- Angivelse af de korrekte datatyper.
- Fjernelse af kolonner, der ikke behøver at blive vist for slutbrugere (f.eks. interne id'er eller tilstandsoplysninger).
- Sikring af, at hver side med data har den samme form ved at tilføje kolonner, der kan mangle i et svar (REST API'er angiver ofte, at felterne skal være null ved helt at udelade dem).
Visning af det eksisterende skema med Table.Schema
Overvej følgende kode, der returnerer en enkel tabel fra Tjenesten TripPin OData-eksempeltjenesten:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
asTable
Bemærk
TripPin er en OData-kilde, så realistisk set ville det give mere mening blot at bruge funktionens OData.Feed automatiske skemahåndtering. I dette eksempel skal du behandle kilden som en typisk REST-API og bruge Web.Contents til at demonstrere teknikken til hardcoding af et skema manuelt.
Denne tabel er resultatet:
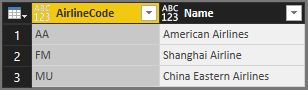
Du kan bruge den praktiske Table.Schema funktion til at kontrollere kolonnernes datatype:
let
url = "https://services.odata.org/TripPinWebApiService/Airlines",
source = Json.Document(Web.Contents(url))[value],
asTable = Table.FromRecords(source)
in
Table.Schema(asTable)

Både AirlineCode og Name er af any typen . Table.Schema returnerer en masse metadata om kolonnerne i en tabel, herunder navne, positioner, typeoplysninger og mange avancerede egenskaber, f.eks. Præcision, Skala og MaxLength. Indtil videre skal du kun beskæftige dig med den tilskrevne type (TypeName), primitiv type (Kind), og om kolonneværdien kan være null (IsNullable).
Definition af en enkel skematabel
Skematabellen består af to kolonner:
| Column | Oplysninger |
|---|---|
| Navn | Navnet på kolonnen. Dette skal svare til navnet i de resultater, der returneres af tjenesten. |
| Skriv | Den M-datatype, du vil angive. Dette kan være en primitiv type (tekst, tal, datetime osv.) eller en tilskrevet type (Int64.Type, Currency.Type osv.). |
Den hardcodede skematabel for tabellen angiver kolonnerne Airlines AirlineCode og Name til text og ser sådan ud:
Airlines = #table({"Name", "Type"}, {
{"AirlineCode", type text},
{"Name", type text}
})
Når du ser på nogle af de andre slutpunkter, skal du overveje følgende skematabeller:
Tabellen Airports indeholder fire felter, du vil bevare (herunder en af typen record):
Airports = #table({"Name", "Type"}, {
{"IcaoCode", type text},
{"Name", type text},
{"IataCode", type text},
{"Location", type record}
})
Tabellen People indeholder syv felter, herunder lists (Emails, AddressInfo), en kolonne, der kan være null (Gender), og en kolonne med en tilskrevet type (Concurrency):
People = #table({"Name", "Type"}, {
{"UserName", type text},
{"FirstName", type text},
{"LastName", type text},
{"Emails", type list},
{"AddressInfo", type list},
{"Gender", type nullable text},
{"Concurrency", Int64.Type}
})
Du kan placere alle disse tabeller i en enkelt masterskematabel SchemaTable:
SchemaTable = #table({"Entity", "SchemaTable"}, {
{"Airlines", Airlines},
{"Airports", Airports},
{"People", People}
})
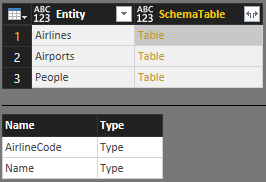
Funktionen SchemaTransformTable-hjælpefunktion
Den SchemaTransformTable hjælpefunktion , der er beskrevet nedenfor, bruges til at gennemtvinge skemaer på dine data. Det kræver følgende parametre:
| Parameter | Type | Description |
|---|---|---|
| table | table | Den tabel med data, du vil gennemtvinge skemaet på. |
| skema | table | Skematabellen, der skal læses kolonneoplysninger fra, med følgende type: type table [Name = text, Type = type]. |
| enforceSchema | Nummer | (valgfrit) En optælling, der styrer funktionens funktionsmåde. Standardværdien ( EnforceSchema.Strict = 1) sikrer, at outputtabellen stemmer overens med den skematabel, der blev angivet, ved at tilføje manglende kolonner og fjerne ekstra kolonner. Indstillingen EnforceSchema.IgnoreExtraColumns = 2 kan bruges til at bevare ekstra kolonner i resultatet. Når EnforceSchema.IgnoreMissingColumns = 3 bruges, ignoreres både manglende kolonner og ekstra kolonner. |
Logikken for denne funktion ser nogenlunde sådan ud:
- Find ud af, om der mangler kolonner fra kildetabellen.
- Find ud af, om der er ekstra kolonner.
- Ignorer strukturerede kolonner (af typen
list,recordogtable), og kolonner, der er angivet til typeany. - Bruges
Table.TransformColumnTypestil at angive hver kolonnetype. - Omarranger kolonner baseret på den rækkefølge, de vises i skematabellen.
- Angiv typen på selve tabellen ved hjælp af
Value.ReplaceType.
Bemærk
Det sidste trin til at angive tabeltypen fjerner behovet for, at Power Query-brugergrænsefladen udleder typeoplysninger, når resultaterne vises i forespørgselseditoren, hvilket nogle gange kan resultere i et dobbeltkald til API'en.
Sætte det hele sammen
I den større kontekst af en komplet udvidelse finder skemahåndteringen sted, når en tabel returneres fra API'en. Denne funktionalitet finder typisk sted på det laveste niveau i sideinddelingsfunktionen (hvis der findes en), hvor enhedsoplysninger overføres fra en navigationstabel.
Da så meget af implementeringen af sideinddelings- og navigationstabeller er kontekstspecifik, vises det komplette eksempel på implementering af en hardcoded skemahåndteringsmekanisme ikke her. Dette TripPin-eksempel viser, hvordan en end-to-end-løsning kan se ud.
Sofistikeret tilgang
Den hardcodede implementering, der er beskrevet ovenfor, gør et godt stykke arbejde med at sikre, at skemaer forbliver konsistente for enkle JSON-repsonser, men det er begrænset til at fortolke det første niveau i svaret. Dybt indlejrede datasæt vil drage fordel af følgende fremgangsmåde, som udnytter M-typer.
Her er en hurtig opdatering af typer på M-sproget fra sprogspecifikationen:
En typeværdi er en værdi, der klassificerer andre værdier. En værdi, der er klassificeret af en type, siges at være i overensstemmelse med denne type. M-typesystemet består af følgende typer:
- Primitive typer, som klassificerer primitive værdier (
binary,date,datetimezonedatetime,duration,list,logical,null,number,record, ,text,time,type) og også omfatter en række abstrakte typer (function,table,anyognone).- Posttyper, der klassificerer postværdier baseret på feltnavne og værdityper.
- Listetyper, der klassificerer lister ved hjælp af en basistype for et enkelt element.
- Funktionstyper, som klassificerer funktionsværdier baseret på typerne af deres parametre og returnerer værdier.
- Tabeltyper, der klassificerer tabelværdier baseret på kolonnenavne, kolonnetyper og nøgler.
- Typer, der kan være null, og som klassificerer værdien null ud over alle de værdier, der er klassificeret af en basistype.
- Typetyper, der klassificerer værdier, der er typer.
Ved hjælp af det rå JSON-output, du får (og/eller ved at slå definitionerne op i tjenestens $metadata), kan du definere følgende posttyper for at repræsentere komplekse OData-typer:
LocationType = type [
Address = text,
City = CityType,
Loc = LocType
];
CityType = type [
CountryRegion = text,
Name = text,
Region = text
];
LocType = type [
#"type" = text,
coordinates = {number},
crs = CrsType
];
CrsType = type [
#"type" = text,
properties = record
];
Bemærk, hvordan LocationType refererer CityType til og LocType til at repræsentere de strukturerede kolonner.
For de enheder på øverste niveau, som du vil have vist som tabeller, kan du definere tabeltyper:
AirlinesType = type table [
AirlineCode = text,
Name = text
];
AirportsType = type table [
Name = text,
IataCode = text,
Location = LocationType
];
PeopleType = type table [
UserName = text,
FirstName = text,
LastName = text,
Emails = {text},
AddressInfo = {nullable LocationType},
Gender = nullable text,
Concurrency Int64.Type
];
Du kan derefter opdatere variablen SchemaTable (som du kan bruge som opslagstabel for tilknytninger af enheder til type) for at bruge disse nye typedefinitioner:
SchemaTable = #table({"Entity", "Type"}, {
{"Airlines", AirlinesType},
{"Airports", AirportsType},
{"People", PeopleType}
});
Du kan stole på en fælles funktion (Table.ChangeType) til at gennemtvinge et skema på dine data på samme måde, som du brugte SchemaTransformTable i den tidligere øvelse. I modsætning til SchemaTransformTabletager Table.ChangeType en faktisk M-tabeltype som et argument og anvender dit skema rekursivt for alle indlejrede typer. Dens signatur er:
Table.ChangeType = (table, tableType as type) as nullable table => ...
Bemærk
For fleksibilitet kan funktionen bruges på tabeller samt lister over poster (hvilket er den måde, tabeller repræsenteres på i et JSON-dokument).
Du skal derefter opdatere connectorkoden for at ændre schema parameteren fra til table og typeføje et kald til Table.ChangeType. Igen er detaljerne for at gøre det meget implementeringsspecifikke og derfor ikke værd at gå i detaljer her. Dette udvidede TripPin-connectoreksempel viser en end-to-end-løsning, der implementerer denne mere avancerede tilgang til håndtering af skema.