Bemærk
Adgang til denne side kræver godkendelse. Du kan prøve at logge på eller ændre mapper.
Adgang til denne side kræver godkendelse. Du kan prøve at ændre mapper.
Denne artikel indeholder nogle eksempelscenarier for hvert af de tre mulige resultater for forespørgselsdelegering. Den indeholder også nogle forslag til, hvordan du får mest muligt ud af forespørgselsfoldningsmekanismen, og hvilken effekt den kan have i dine forespørgsler.
Scenariet
Forestil dig et scenarie, hvor du ved hjælp af Wide World Importers-databasen til Azure Synapse Analytics SQL-databasen har til opgave at oprette en forespørgsel i Power Query, der opretter forbindelse til fact_Sale tabellen og henter de sidste 10 salg med kun følgende felter:
- Udsalgsnøgle
- Kundes nøgle
- Nøgle til fakturadato
- Beskrivelse
- Antal
Notat
Til demonstrationsformål bruger denne artikel den database, der er beskrevet i selvstudiet om indlæsning af Wide World Importers-databasen i Azure Synapse Analytics. Den største forskel i denne artikel er, at fact_Sale tabellen kun indeholder data for år 2000, med i alt 3.644.356 rækker.
Selvom resultaterne muligvis ikke stemmer nøjagtigt overens med de resultater, du får ved at følge selvstudiet fra Azure Synapse Analytics-dokumentationen, er målet med denne artikel at vise de kernebegreber og den indflydelse, som forespørgselsdelegering kan have i dine forespørgsler.

I denne artikel beskrives tre måder at opnå det samme output på med forskellige niveauer af forespørgselsdelegering:
- Ingen forespørgselsdelegering
- Delvis forespørgselsdelegering
- Fuld forespørgselsdelegering
Eksempel på ingen forespørgselsdelegering
Important
Forespørgsler, der udelukkende er afhængige af ustrukturerede datakilder, eller som ikke har et beregningsprogram, f.eks. CSV- eller Excel-filer, har ikke funktioner til forespørgselsdelegering. Det betyder, at Power Query evaluerer alle de påkrævede datatransformationer ved hjælp af Power Query-programmet.
Når du har oprettet forbindelse til databasen fact_Sale og navigeret til tabellen, skal du vælge transformeringen Bevar nederste rækker , der findes i gruppen Reducer rækker under fanen Hjem .
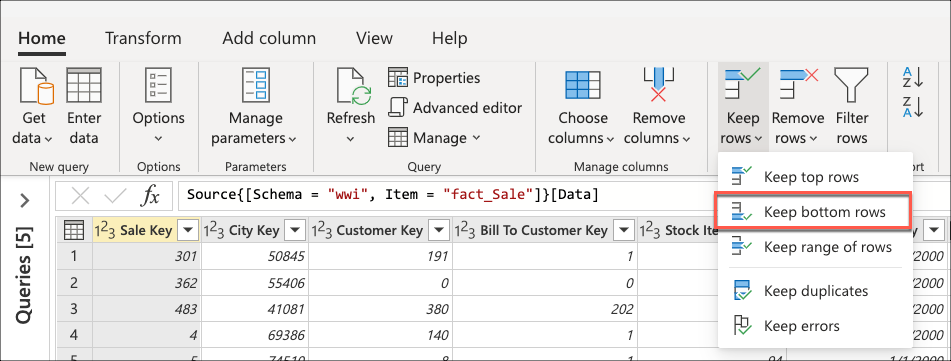
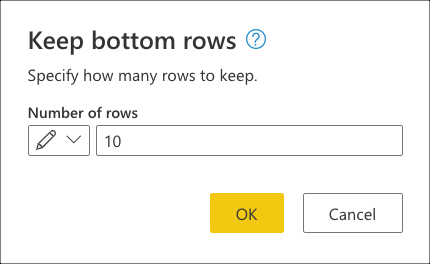
Når du har valgt denne transformering, vises en ny dialogboks. I denne nye dialogboks kan du angive antallet af rækker, du vil beholde. I dette tilfælde skal du angive værdien 10 og derefter vælge OK.
Tips
I dette tilfælde giver udførelse af denne handling resultatet af de sidste 10 salg. I de fleste scenarier anbefaler vi, at du angiver en mere eksplicit logik, der definerer, hvilke rækker der betragtes som sidst, ved at anvende en sorteringshandling på tabellen.
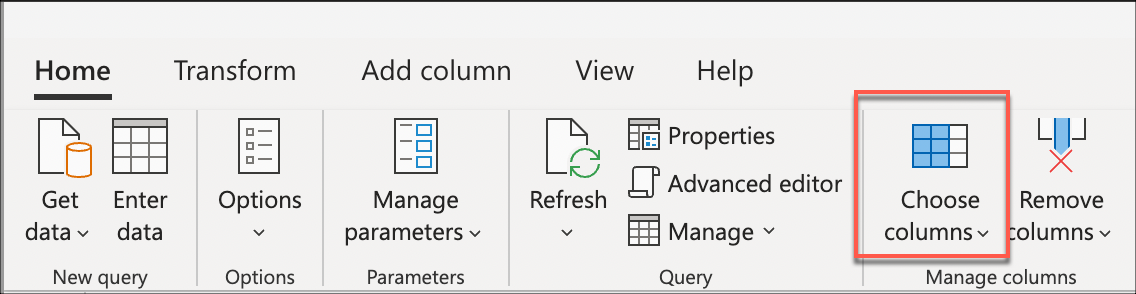
Vælg derefter transformationen Vælg kolonner , der findes i gruppen Administrer kolonner under fanen Hjem . Du kan derefter vælge de kolonner, du vil beholde fra din tabel, og fjerne resten.
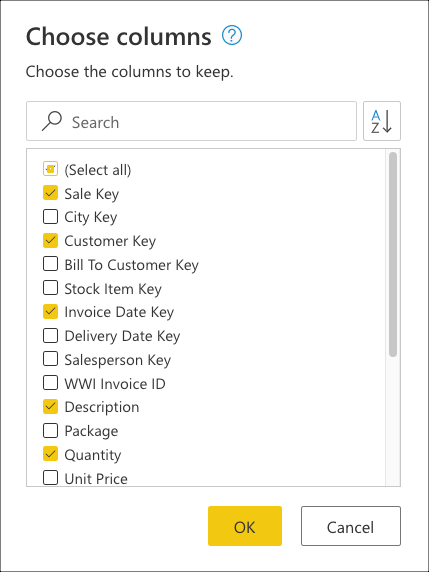
Til sidst skal du i dialogboksen Vælg kolonner vælge Sale Key, Customer Key, Invoice Date Key, Descriptionog Quantity kolonner og derefter vælge OK.
Følgende kodeeksempel er det fulde M-script for den forespørgsel, du har oprettet:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Kept bottom rows" = Table.LastN(Navigation, 10),
#"Choose columns" = Table.SelectColumns(
#"Kept bottom rows",
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
)
in
#"Choose columns""
Ingen forespørgselsdelegering: Om forespørgselsevalueringen
Under Anvendte trin i Power Query-editoren skal du bemærke, at indikatorerne for forespørgselsdelegering for Bevarede nederste rækker og Vælg kolonner er markeret som trin, der evalueres uden for datakilden eller med andre ord af Power Query-programmet.
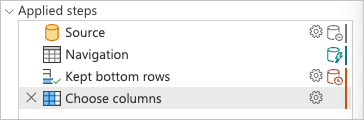
Du kan højreklikke på det sidste trin i forespørgslen, det der hedder Vælg kolonner, og vælge den indstilling, der læser Vis forespørgselsplan. Målet med forespørgselsplanen er at give dig en detaljeret visning af, hvordan forespørgslen køres. Du kan få mere at vide om denne funktion ved at gå til Forespørgselsplan.

Hver boks i det forrige billede kaldes en node. En node repræsenterer handlingsopdelingen for at opfylde denne forespørgsel. Noder, der repræsenterer datakilder, f.eks. SQL Server i det forrige eksempel og noden Value.NativeQuery , repræsenterer, hvilken del af forespørgslen der overføres til datakilden. Resten af noderne, i dette tilfælde Table.LastN og Table.SelectColumns fremhævet i rektanglet på det forrige billede, evalueres af Power Query-programmet. Disse to noder repræsenterer de to transformeringer, du har tilføjet, Bevarede nederste rækker og Vælg-kolonner. Resten af noderne repræsenterer handlinger, der sker på datakildeniveau.
Hvis du vil se den nøjagtige anmodning, der sendes til din datakilde, skal du vælge Vis detaljer i noden Value.NativeQuery .

Denne datakildeanmodning er på datakildens oprindelige sprog. I dette tilfælde er sproget SQL, og denne sætning repræsenterer en anmodning om alle rækker og felter fra fact_Sale tabellen.
Hvis du konsulterer denne datakildeanmodning, kan det hjælpe dig med bedre at forstå den historie, som forespørgselsplanen forsøger at formidle:
-
Sql.Database: Denne node repræsenterer datakildens adgang. Opretter forbindelse til databasen og sender metadataanmodninger for at forstå dens muligheder. -
Value.NativeQuery: Repræsenterer den anmodning, der blev genereret af Power Query for at opfylde forespørgslen. Power Query sender dataanmodningerne i en oprindelig SQL-sætning til datakilden. I dette tilfælde repræsenterer det alle poster og felter (kolonner) frafact_Saletabellen. I dette scenarie er dette tilfælde uønsket, da tabellen indeholder millioner af rækker, og interessen kun er i de sidste 10. -
Table.LastN: Når Power Query modtager alle poster frafact_Saletabellen, bruger den Power Query-programmet til at filtrere tabellen og kun beholde de sidste 10 rækker. -
Table.SelectColumns: Power Query bruger outputtet fra nodenTable.LastNog anvender en ny transformering kaldetTable.SelectColumns, som vælger de specifikke kolonner, du vil beholde fra en tabel.
Til evalueringen skulle denne forespørgsel downloade alle rækker og felter fact_Sale fra tabellen. Denne forespørgsel tog i gennemsnit 6 minutter og 1 sekund at blive behandlet i en standardforekomst af Power BI-dataflow (som tegner sig for evaluering og indlæsning af data til dataflow).
Eksempel på delvis forespørgselsdelegering
Når du har oprettet forbindelse til databasen og navigeret til fact_Sale tabellen, starter du med at vælge de kolonner, du vil beholde fra tabellen. Vælg transformationen Vælg kolonner , der findes i gruppen Administrer kolonner under fanen Hjem . Denne transformering hjælper dig med eksplicit at vælge de kolonner, du vil beholde fra tabellen, og fjerne resten.
I dialogboksen Vælg kolonner skal du vælge kolonnerne Sale Key, Customer Key, Invoice Date KeyDescription, og Quantity og derefter vælge OK.
Du kan nu oprette logik, der sorterer tabellen, så den har de sidste salg nederst i tabellen. Marker kolonnen Sale Key , som er den primære nøgle og den trinvise sekvens eller indeks i tabellen. Sorter tabellen kun ved hjælp af dette felt i stigende rækkefølge fra kontekstmenuen for kolonnen.
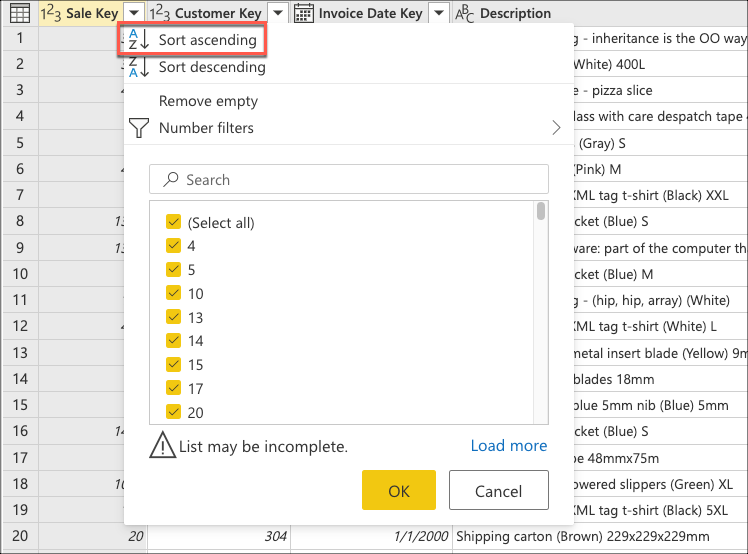
Vælg derefter tabellens kontekstmenu, og vælg transformeringen Behold nederste rækker .
Angiv værdien 10 i Behold nederste rækker, og vælg derefter OK.
Følgende kodeeksempel er det fulde M-script for den forespørgsel, du har oprettet:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Ascending}}),
#"Kept bottom rows" = Table.LastN(#"Sorted rows", 10)
in
#"Kept bottom rows"
Eksempel på delvis forespørgselsdelegering: Om forespørgselsevalueringen
Når du kontrollerer ruden anvendte trin, bemærker du, at indikatorerne for forespørgselsdelegering viser, at den sidste transformering, du har tilføjet, Kept bottom rowser markeret som et trin, der evalueres uden for datakilden eller med andre ord af Power Query-programmet.
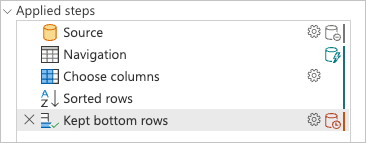
Du kan højreklikke på det sidste trin i forespørgslen, det navngivne Kept bottom rows, og vælge indstillingen Forespørgselsplan for bedre at forstå, hvordan din forespørgsel kan evalueres.

Hver boks i det forrige billede kaldes en node. En node repræsenterer alle de processer, der skal ske (fra venstre mod højre), for at din forespørgsel kan evalueres. Nogle af disse noder kan evalueres i din datakilde, mens andre, f.eks. noden for Table.LastN, repræsenteret af trinnet Bevarede nederste rækker , evalueres ved hjælp af Power Query-programmet.
Hvis du vil se den nøjagtige anmodning, der sendes til din datakilde, skal du vælge Vis detaljer i noden Value.NativeQuery .

Denne anmodning er på datakildens oprindelige sprog. I dette tilfælde er sproget SQL, og denne sætning repræsenterer en anmodning for alle rækkerne, hvor kun de anmodede felter fra tabellen fact_Sale er sorteret Sale Key efter feltet.
Hvis du konsulterer denne datakildeanmodning, kan det hjælpe dig med bedre at forstå den historie, som den fulde forespørgselsplan forsøger at formidle. Rækkefølgen af noderne er en sekventiel proces, der starter med at anmode om dataene fra din datakilde:
-
Sql.Database: Opretter forbindelse til databasen og sender metadataanmodninger for at forstå dens muligheder. -
Value.NativeQuery: Repræsenterer den anmodning, der genereres af Power Query for at opfylde forespørgslen. Power Query sender dataanmodningerne i en oprindelig SQL-sætning til datakilden. I dette tilfælde repræsenterer det alle poster, hvor kun de anmodede felter frafact_Saletabellen i databasen er sorteret i stigende rækkefølge efterSales Keyfeltet. -
Table.LastN: Når Power Query modtager alle poster frafact_Saletabellen, bruger den Power Query-programmet til at filtrere tabellen og kun beholde de sidste 10 rækker.
Til evalueringen skulle denne forespørgsel downloade alle rækker og kun de påkrævede felter fra fact_Sale tabellen. Det tog i gennemsnit 3 minutter og 4 sekunder at blive behandlet i en standardforekomst af Power BI-dataflow (som tager højde for evaluering og indlæsning af data til dataflow).
Eksempel på fuld forespørgselsdelegering
Når du har oprettet forbindelse til databasen og navigeret til fact_Sale tabellen, skal du starte med at vælge de kolonner, du vil beholde fra tabellen. Vælg transformationen Vælg kolonner , der findes i gruppen Administrer kolonner under fanen Hjem . Denne transformering hjælper dig med eksplicit at vælge de kolonner, du vil beholde fra tabellen, og fjerne resten.
I Vælg kolonner skal du vælge kolonnerne Sale Key, Customer Key, Invoice Date KeyDescription, og Quantity og derefter vælge OK.
Du kan nu oprette logik, der sorterer tabellen, så den har de sidste salg øverst i tabellen. Marker kolonnen Sale Key , som er den primære nøgle og den trinvise sekvens eller indeks i tabellen. Sorter kun tabellen ved hjælp af dette felt i faldende rækkefølge fra kolonnens genvejsmenu.
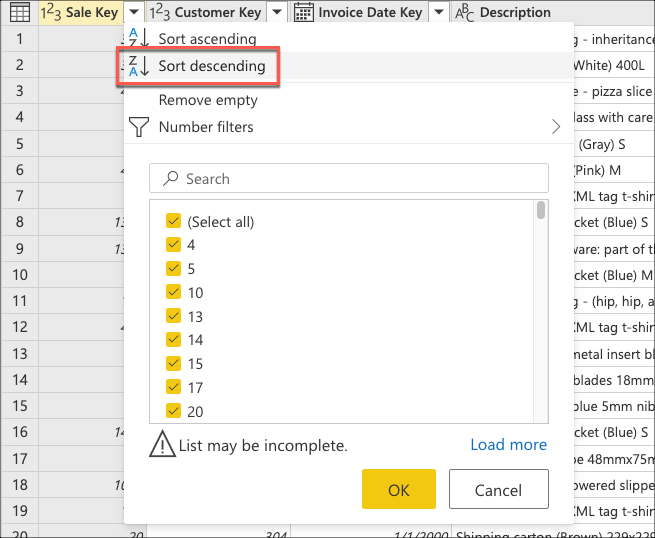
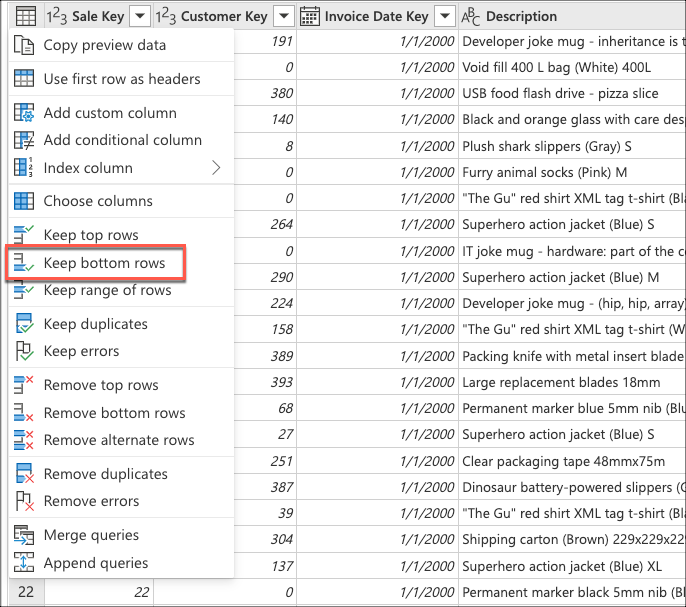
Vælg derefter genvejsmenuen for tabellen, og vælg transformeringen Behold de øverste rækker .
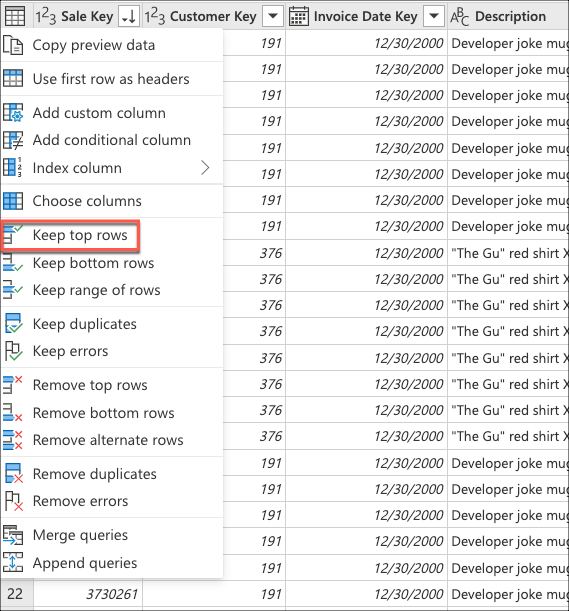
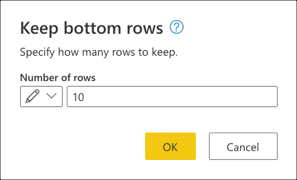
Angiv værdien 10 i Behold de øverste rækker, og vælg derefter OK.
Følgende kodeeksempel er det fulde M-script for den forespørgsel, du har oprettet:
let
Source = Sql.Database(ServerName, DatabaseName),
Navigation = Source{[Schema = "wwi", Item = "fact_Sale"]}[Data],
#"Choose columns" = Table.SelectColumns(
Navigation,
{"Sale Key", "Customer Key", "Invoice Date Key", "Description", "Quantity"}
),
#"Sorted rows" = Table.Sort(#"Choose columns", {{"Sale Key", Order.Descending}}),
#"Kept top rows" = Table.FirstN(#"Sorted rows", 10)
in
#"Kept top rows"
Eksempel på fuld forespørgselsdelegering: Om forespørgselsevalueringen
Når du kontrollerer ruden anvendte trin, skal du være opmærksom på, at indikatorerne for forespørgselsdelegering viser, at de transformeringer, du har tilføjet, Vælg kolonner, Sorterede rækker og Bevarede øverste rækker, er markeret som trin, der evalueres i datakilden.

Du kan højreklikke på det sidste trin i forespørgslen, det der hedder Bevarede øverste rækker, og vælge den indstilling, der læser Forespørgselsplan.

Denne anmodning er på datakildens oprindelige sprog. I dette tilfælde er sproget SQL, og denne sætning repræsenterer en anmodning om alle rækker og felter fra fact_Sale tabellen.
Hvis du konsulterer denne datakildeforespørgsel, kan det hjælpe dig med bedre at forstå den historie, som den fulde forespørgselsplan forsøger at formidle:
-
Sql.Database: Opretter forbindelse til databasen og sender metadataanmodninger for at forstå dens muligheder. -
Value.NativeQuery: Repræsenterer den anmodning, der genereres af Power Query for at opfylde forespørgslen. Power Query sender dataanmodningerne i en oprindelig SQL-sætning til datakilden. I dette tilfælde repræsenterer det en anmodning om kun de 10 øverste poster ifact_Saletabellen, hvor kun de påkrævede felter er sorteret i faldende rækkefølge ved hjælp afSale Keyfeltet.
Notat
Selvom der ikke er nogen klausul, der kan bruges til at VÆLGE de nederste rækker i en tabel på T-SQL-sproget, er der en TOP-delsætning, der henter de øverste rækker i en tabel.
Til evalueringen downloader denne forespørgsel kun 10 rækker med kun de felter, du har anmodet om fra fact_Sale tabellen. Det tog i gennemsnit 31 sekunder for denne forespørgsel at blive behandlet i en standardforekomst af Power BI-dataflow (som tager højde for evaluering og indlæsning af data til dataflow).
Sammenligning af ydeevne
Hvis du vil have en bedre forståelse af den effekt, som forespørgselsdelegering har i disse forespørgsler, kan du opdatere dine forespørgsler, registrere den tid, det tager at opdatere hver forespørgsel fuldt ud, og sammenligne dem. For nemheds skyld indeholder denne artikel de gennemsnitlige opdateringstidspunkter, der er registreret ved hjælp af Power BI-dataflowopdateringsmekanikeren, mens der oprettes forbindelse til et dedikeret Azure Synapse Analytics-miljø med DW2000c som serviceniveau.
Opdateringstidspunktet for hver forespørgsel var som følger:
| Eksempel | Mærkat | Tid i sekunder |
|---|---|---|
| Ingen forespørgselsdelegering | Ingen | 361 |
| Delvis forespørgselsdelegering | Partiel | 184 |
| Fuld forespørgselsdelegering | Fuld | 31 |
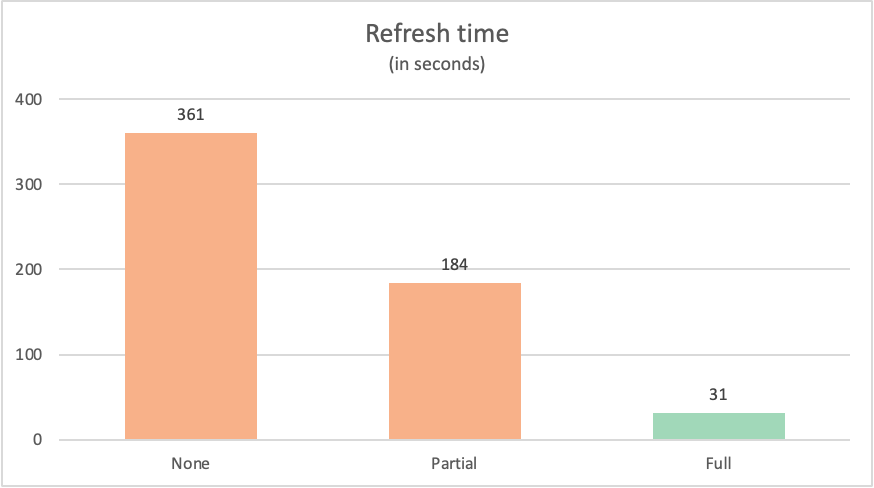
Det er ofte tilfældet, at en forespørgsel, der foldes helt tilbage til datakilden, overgår lignende forespørgsler, der ikke foldes helt tilbage til datakilden. Der kan være mange grunde til, at det er tilfældet. Disse årsager spænder fra kompleksiteten af de transformeringer, som din forespørgsel udfører, til de forespørgselsoptimeringer, der er implementeret på din datakilde, f.eks. indekser og dedikeret databehandling og netværksressourcer. Der er stadig to specifikke nøgleprocesser, som forespørgselsdelegering forsøger at bruge, der minimerer den effekt, som begge disse processer har med Power Query:
- Data i transit
- Transformeringer, der udføres af Power Query-programmet
I de følgende afsnit forklares den effekt, som disse to processer har i de tidligere nævnte forespørgsler.
Data i transit
Når en forespørgsel udføres, forsøger den at hente dataene fra datakilden som et af de første trin. Hvilke data der hentes fra datakilden, defineres af forespørgselsdelegeringsmekanismen. Denne mekanisme identificerer de trin fra forespørgslen, der kan overføres til datakilden.
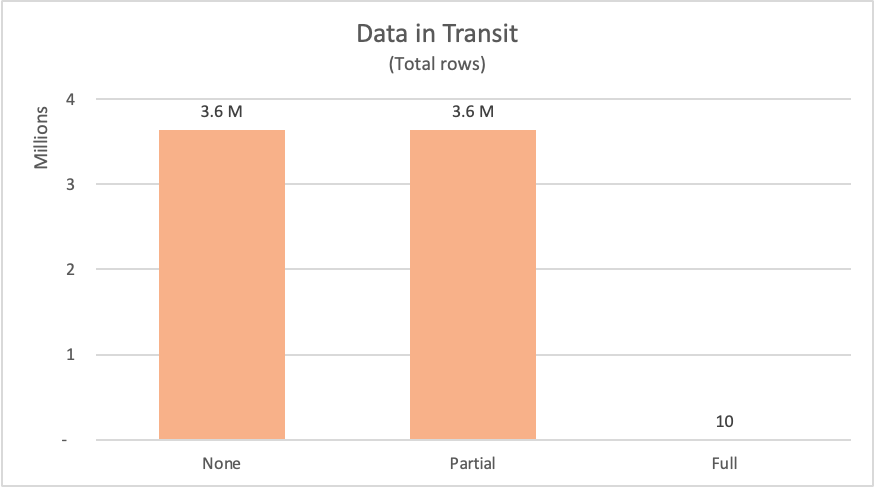
I følgende tabel vises antallet af de rader, der anmodes om fra databasens fact_Sale tabel. Tabellen indeholder også en kort beskrivelse af den SQL-sætning, der sendes for at anmode om sådanne data fra datakilden.
| Eksempel | Mærkat | Anmodede rækker | Beskrivelse |
|---|---|---|---|
| Ingen forespørgselsdelegering | Ingen | 3644356 | Anmodning om alle felter og alle poster fra fact_Sale tabellen |
| Delvis forespørgselsdelegering | Partiel | 3644356 | Anmodning om alle poster, men kun obligatoriske felter fra fact_Sale tabellen, efter at den er sorteret Sale Key efter feltet |
| Fuld forespørgselsdelegering | Fuld | 10 | Anmod om kun de påkrævede felter og TOP 10-posterne i tabellen, når de fact_Sale er sorteret i faldende rækkefølge efter Sale Key feltet |
Når du anmoder om data fra en datakilde, skal datakilden beregne resultaterne for anmodningen og derefter sende dataene til anmoderen. Selvom computerressourcerne allerede er blevet nævnt, kan netværksressourcerne til at flytte dataene fra datakilden til Power Query og derefter få Power Query til effektivt at modtage dataene og forberede dem til de transformeringer, der sker lokalt, tage noget tid, afhængigt af størrelsen på dataene.
I forbindelse med de viste eksempler skulle Power Query anmode om over 3,6 millioner rækker fra datakilden til eksemplerne på ingen forespørgselsdelegering og delvis forespørgselsdelegering. I det fulde eksempel på forespørgselsdelegering anmodede den kun om 10 rækker. For de anmodede felter anmodede eksemplet om ingen forespørgselsdelegering alle de tilgængelige felter fra tabellen. Både eksemplerne på delvis forespørgselsdelegering og den fulde forespørgselsdelegering sendte kun en anmodning om præcis de felter, de havde brug for.
Advarsel!
Det anbefales, at du implementerer trinvise opdateringsløsninger, der bruger forespørgselsdelegering til forespørgsler eller tabeller med store mængder data. Forskellige produktintegrationer af Power Query implementerer timeout for at afslutte langvarige forespørgsler. Nogle datakilder implementerer også timeouts på langvarige sessioner og forsøger at udføre dyre forespørgsler mod deres servere. Flere oplysninger: Brug af trinvis opdatering med dataflow og trinvis opdatering til semantiske modeller
Transformeringer, der udføres af Power Query-programmet
I denne artikel kan du se, hvordan du kan bruge forespørgselsplanen til bedre at forstå, hvordan din forespørgsel kan evalueres. I forespørgselsplanen kan du se de nøjagtige noder for de transformeringshandlinger, der udføres af Power Query-programmet.
I følgende tabel vises noderne fra forespørgselsplanerne for de tidligere forespørgsler, der ville være blevet evalueret af Power Query-programmet.
| Eksempel | Mærkat | Transformeringsnoder for Power Query-program |
|---|---|---|
| Ingen forespørgselsdelegering | Ingen |
Table.LastN, Table.SelectColumns |
| Delvis forespørgselsdelegering | Partiel | Table.LastN |
| Fuld forespørgselsdelegering | Fuld | – |
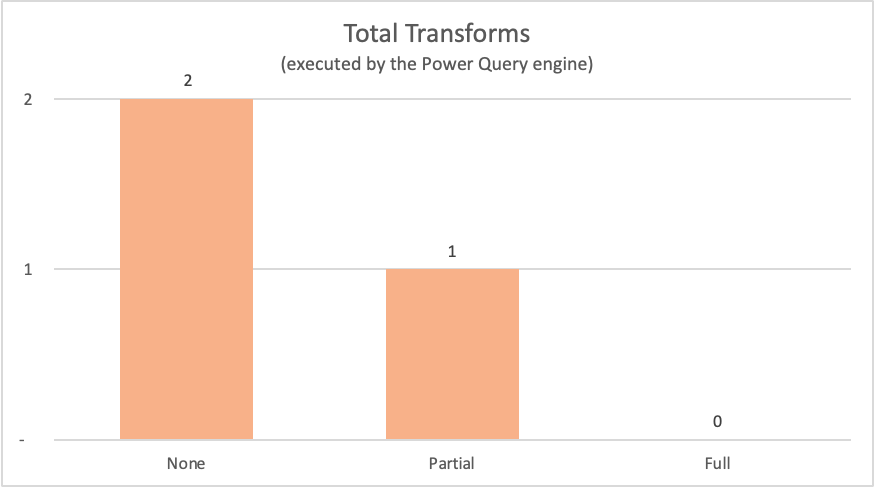
I de eksempler, der vises i denne artikel, kræver det fulde eksempel på forespørgselsdelegering ikke, at der sker nogen transformeringer i Power Query-programmet, da den påkrævede outputtabel kommer direkte fra datakilden. I modsætning hertil krævede de to andre forespørgsler en vis beregning for at ske på Power Query-programmet. På grund af mængden af data, der skal behandles af disse to forespørgsler, tager processen for disse eksempler længere tid end det fulde eksempel på forespørgselsdelegering.
Transformeringer kan grupperes i følgende kategorier:
| Type operatør | Beskrivelse |
|---|---|
| Fjern | Operatorer, der er datakildenoder. Evalueringen af disse operatorer sker uden for Power Query. |
| Streaming | Operatører er gennemgangsoperatører. Med et simpelt filter kan du f.eks. normalt filtrere resultaterne, når de passerer gennem operatoren, og behøver ikke at samle alle rækker, Table.SelectRows før du flytter dataene.
Table.SelectColumns og Table.ReorderColumns er andre eksempler på denne slags operatører. |
| Fuld scanning | Operatorer, der skal samle alle rækkerne, før dataene kan gå videre til den næste operator i kæden. Hvis du f.eks. vil sortere data, skal Power Query indsamle alle dataene. Andre eksempler på fuld scanningsoperatører er Table.Group, Table.NestedJoin, og Table.Pivot. |
Tips
Selvom ikke alle transformationer er ens fra et præstationssynspunkt, er det i de fleste tilfælde normalt bedre at have færre transformationer.
Overvejelser og forslag
- Følg de bedste fremgangsmåder, når du opretter en ny forespørgsel, som angivet i Bedste fremgangsmåder i Power Query.
- Brug indikatorerne for forespørgselsdelegering til at kontrollere, hvilke trin der forhindrer forespørgslen i at folde. Omarranger dem om nødvendigt for at øge foldningen.
- Brug forespørgselsplanen til at finde ud af, hvilke transformeringer der sker i Power Query-programmet for et bestemt trin. Overvej at ændre din eksisterende forespørgsel ved at omarrangere dine trin. Kontrollér derefter forespørgselsplanen for det sidste trin i forespørgslen igen, og se, om forespørgselsplanen ser bedre ud end den forrige. Den nye forespørgselsplan har f.eks. færre noder end den forrige, og de fleste af noderne er "Streaming"-noder og ikke "fuld scanning". For datakilder, der understøtter foldning, repræsenterer alle noder i forespørgselsplanen, bortset fra
Value.NativeQueryog datakildeadgangsnoder, transformeringer, der ikke blev foldet. - Når det er tilgængeligt, kan du bruge indstillingen Vis oprindelig forespørgsel (eller Vis datakildeforespørgsel) til at sikre, at forespørgslen kan foldes tilbage til datakilden. Hvis denne indstilling er deaktiveret for dit trin, og du bruger en kilde, der normalt aktiverer den, har du oprettet et trin, der stopper forespørgselsdelegering. Hvis du bruger en kilde, der ikke understøtter denne indstilling, kan du stole på indikatorerne for forespørgselsdelegering og forespørgselsplanen.
- Brug værktøjerne til forespørgselsdiagnosticering til bedre at forstå de anmodninger, der sendes til din datakilde, når der er funktioner til forespørgselsdelegering tilgængelige for connectoren.
- Når du kombinerer data, der stammer fra brugen af flere connectorer, forsøger Power Query at skubbe så meget arbejde som muligt til begge datakilder, samtidig med at de niveauer for beskyttelse af personlige oplysninger, der er defineret for hver datakilde, overholdes.
- Læs artiklen om niveauer for beskyttelse af personlige oplysninger for at beskytte dine forespørgsler mod at køre mod en fejl i Firewall til beskyttelse af personlige oplysninger.
- Brug andre værktøjer til at kontrollere forespørgselsdelegering ud fra perspektivet for den anmodning, der modtages af datakilden. Baseret på eksemplet i denne artikel kan du bruge Microsoft SQL Server Profiler til at kontrollere de anmodninger, der sendes af Power Query og modtages af Microsoft SQL Server.
- Hvis du føjer et nyt trin til en fuldt foldet forespørgsel, og det nye trin også foldes, kan Power Query sende en ny anmodning til datakilden i stedet for at bruge en cachelagret version af det forrige resultat. I praksis kan denne proces resultere i, at tilsyneladende enkle handlinger på en lille mængde data tager længere tid at opdatere i prøveversionen end forventet. Denne længere opdatering skyldes, at Power Query forespørger datakilden igen i stedet for at arbejde ud fra en lokal kopi af dataene.