Før skyen
Nu, hvor vi har defineret, hvad cloudcomputing er, kan vi se på eksempler på, hvordan databehandling blev brugt på forskellige domæner, f.eks. virksomhedscomputing, videnskabelig databehandling og personlig databehandling, før cloudcomputing opstod.
Domæner og programeksempler
Business computing: Eksempler på traditionelle administrationsoplysninger omfatter logistik og drift, ERP (Enterprise Resource Planning), CRM (Customer Relation Management), Office Productivity og Business Intelligence (BI). Sådanne værktøjer muliggjorde mere strømlinede processer, der førte til forbedret produktivitet og reducerede omkostninger på tværs af en række virksomheder.
CRM-software giver f.eks. virksomheder mulighed for at indsamle, gemme, administrere og fortolke en række data om tidligere, aktuelle og potentielle fremtidige kunder. CRM-software tilbyder en integreret visning (i realtid eller næsten i realtid) af alle organisatoriske interaktioner med kunder. For en produktionsvirksomhed kan CRM-software f.eks. bruges af et salgsteam til at planlægge møder, opgaver og opfølgninger med klienter. Et marketingteam kan målrette kunder med kampagner baseret på specifikke mønstre. Faktureringsteams kan spore tilbud og fakturaer. Det er derfor et centraliseret lager til lagring af disse oplysninger. For at aktivere denne funktionalitet bruges en række hardware- og softwareteknologier af organisationen og salgsteamene til at indsamle de data, der skal gemmes og analyseres ved hjælp af forskellige database- og analysesystemer.
Videnskabelig databehandling: Videnskabelig databehandling bruger matematiske modeller og analyseteknikker, der er implementeret på computere, til at forsøge at løse videnskabelige problemer. Et populært eksempel er computersimulering af fysiske fænomener. Dette område har forstyrret de traditionelle teoretiske og laboratorie eksperimentelle metoder ved at gøre det muligt for videnskabsfolk og ingeniører at rekonstruere kendte begivenheder eller forudsige fremtidige situationer ved at udvikle programmer til at simulere og studere forskellige systemer under forskellige omstændigheder. Sådanne simuleringer kræver typisk et meget stort antal beregninger, der ofte køres på dyre supercomputere eller distribuerede databehandlingsplatforme.
til personlig databehandling: I forbindelse med personlig databehandling kører en bruger forskellige programmer på en generel computer. Sådanne programmer kan være til office-produktivitet, f.eks. tekstbehandling og regneark. kommunikation, f.eks. mailklienter; eller underholdning, f.eks. videospil eller multimediefiler. En bruger af personlig databehandling ejer, installerer og vedligeholder typisk den software og hardware, der bruges til at udføre sådanne opgaver.
Adressering af skalering
Det har været en løbende proces at øge omfanget af databehandling, uanset om det er ved at øge antallet af kunder og begivenheder, der skal registreres, overvåges og analyseres i CRM, eller ved at øge præcisionen af numeriske simuleringer i videnskabelig databehandling eller realisme i videospilprogrammer. Behovet for større skala er desuden blevet drevet af den stigende indførelse af teknologi inden for forskellige områder eller en udvidelse af virksomheder og markeder samt den fortsatte stigning i antallet af brugere og deres behov. Organisationer skal tage højde for stigningen i skala, efterhånden som de planlægger og budgetterer for udrulningen af deres løsninger.
Organisationer planlægger typisk deres it-infrastruktur i en proces, der kaldes kapacitetsplanlægning. Under kapacitetsplanlægningsprocessen måles væksten i brugen af forskellige it-tjenester og bruges som benchmark for fremtidig udvidelse. Organisationer skal planlægge på forhånd for at skaffe, konfigurere og vedligeholde nyere og bedre servere, lager og netværksudstyr. Nogle gange er organisationer begrænset af software, fordi de muligvis kun har anskaffet et begrænset sæt licenser og kan kræve mere for at udvide infrastrukturen, så den dækker et større sæt brugere.
Den mest grundlæggende form for skalering er kendt som lodret skalering, hvor gamle systemer erstattes med nyere, bedre ydende systemer, der kan levere de nødvendige opgraderinger til serviceniveauet. I mange tilfælde består lodret skalering af opgradering eller udskiftning af servere og lagersystemer med nyere, hurtigere servere eller lagermatrixer med øget kapacitet. Denne proces kan tage måneder at planlægge og udføre sammen med et vindue, hvor tjenesten kan opleve en vis nedetid.
I visse typer systemer udføres skalering også vandretved at øge mængden af ressourcer, der er dedikeret til systemet. Et eksempel på dette er databehandling med høj ydeevne, hvor der kan tilføjes ekstra servere og lagerplads for at forbedre systemets ydeevne, hvilket fører til et højere antal beregninger, der kan udføres pr. sekund, eller en forøgelse af systemets lagerkapacitet. På samme måde som med lodret skalering kan denne proces tage måneder at planlægge og udføre med nedetid også en mulighed.
Da virksomheder ejede og vedligeholdte deres it-udstyr, da omkostningerne ved at håndtere omfanget fortsatte med at stige, identificerede virksomheder andre metoder til at reducere omkostningerne. Store virksomheder har konsolideret databehandlingsbehovene i forskellige afdelinger i et enkelt stort datacenter, hvor de konsoliderer fast ejendom, strøm, køling og netværk for at reducere omkostningerne. På den anden side kan små og mellemstore virksomheder lease fast ejendom, netværk, strøm, køling og fysisk sikkerhed ved at placere deres it-udstyr i et delt datacenter. Dette kaldes typisk en samplaceringstjeneste, som blev vedtaget af små og mellemstore virksomheder, der ikke ønskede at bygge deres egne datacentre i huset. Samplaceringstjenester anvendes fortsat på forskellige områder som en omkostningseffektiv tilgang til at reducere driftsomkostningerne.
Skala har påvirket alle aspekter af virksomhedscomputing. Skalering har f.eks. påvirket CRM-systemer ved at øge antallet af klienter eller via mængden af oplysninger, der er gemt og analyseret om klienter. Virksomhedscomputing har håndteret skalering via lodret og vandret skalering samt konsolidering af it-ressourcer til datacentre og samtidig placering. Inden for videnskabelig databehandling er der indført parallelle og distribuerede systemer for at opskalere problemernes størrelse og præcisionen af deres numeriske simuleringer. En definition af parallel behandling er brugen af flere homogene computere, der deler tilstand og fungerer som en enkelt stor computer for at køre beregninger i stor skala eller med høj præcision. Distribueret databehandling er brugen af flere autonome databehandlingssystemer, der er forbundet af et netværk, for at partitionere et stort problem i underopgaver, der køres samtidigt og kommunikerer via meddelelser via netværket. Det videnskabelige samfund fortsatte med at skabe innovation på disse områder for at tage fat på skalaen. I forbindelse med personlig databehandling har skalaen påvirket den gennem øgede brugerkrav, der er forårsaget af mere omfattende indhold og forskellige programmer. Brugerne skalerer derfor deres ejede personlige databehandlingsenheder op for at følge med disse krav.
Stigning i internettjenester
I slutningen af 90'erne var der en konstant stigning i indførelsen af disse databehandlingsprogrammer og -platforme på tværs af domæner. Snart forventedes software ikke kun at være funktionel, men også i stand til at producere værdi og indsigt til forretningsmæssige og personlige krav. Brugen af disse programmer blev samarbejdsbaseret. programmer blev blandet og matchet med feedoplysninger til hinanden. Det var ikke længere blot et omkostningssted for en virksomhed, men en kilde til innovation og effektivitet.
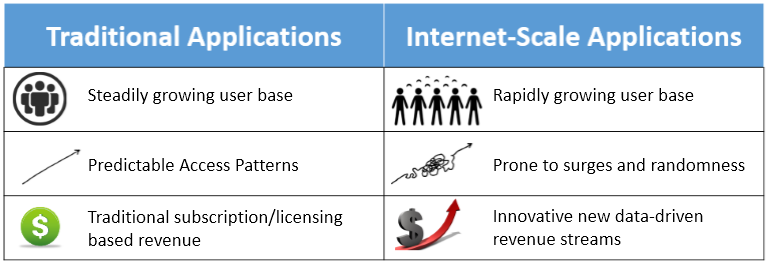
Figur 2: Sammenlign traditionel databehandling og databehandling i internetskala
Det 21. århundrede har været præget af en eksplosion i mængden og kapaciteten af trådløs kommunikation, World Wide Web og internettet. Disse ændringer har ført til et netværksdrevet og datadrevet samfund, hvor produktion, udbredelse og adgang til digitaliserede oplysninger forenkles. Internettet anslås at have skabt en global markedsplads for milliarder af brugere, op fra 25 millioner i 1994.1 Denne stigning i data og forbindelser er værdifuld for virksomheder. Data skaber værdi på flere måder, herunder ved at muliggøre eksperimentering, segmentere populationer og understøtte beslutningstagning med automatisering.2 Ved at omfavne digitale teknologier forventes verdens ti største økonomier at øge deres output med over en billion dollars i 2020.
Det stigende antal forbindelser, der aktiveres af internettet, har også drevet dens værdi. Forskere har antaget, at værdien af et netværk varierer overlinjet som en funktion af antallet af brugere. På internet-skala er det derfor en prioritet at få og bevare kunder. Dette gøres ved at oprette pålidelige og dynamiske tjenester og foretage ændringer baseret på observerede datamønstre.
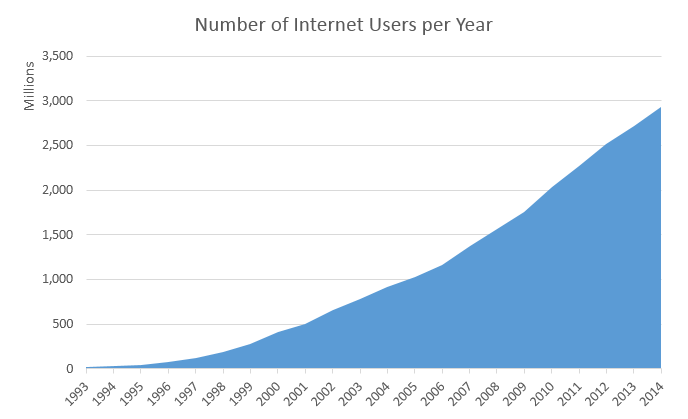
figur 3: Stigende antal internetbrugere pr. år
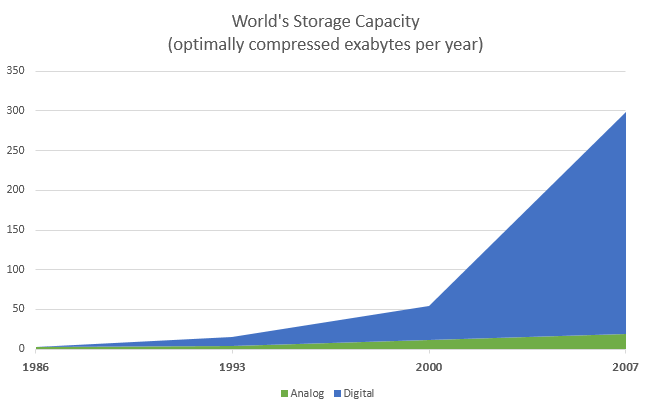
Figur 4: Stigende mængde data, der gemmes om året5
Nogle eksempler på internet-skala systemer omfatter:
- Søgemaskiner, der gennemsøger, gemmer, indekserer og søger i store (op til petabyte-størrelse) datasæt. Google startede f.eks. som et gigantisk webindeks, der gennemsøgte og analyserede webtrafik en gang med få dages mellemrum og matchede disse indekser med nøgleord. Nu opdaterer det sine indeks i næsten realtid og er en af de mest populære måder at få adgang til oplysninger på internettet. Dets indeks har billioner af sider med en størrelse på tusindvis af terabyte.4
- Sociale netværk som Facebook og LinkedIn, der giver brugerne mulighed for at oprette personlige og professionelle relationer og opbygge fællesskaber baseret på lignende interesser. Facebook understøtter nu over en milliard aktive brugere pr. måned.
- Online detailtjenester som Amazon, der vedligeholder en global beholdning af millioner af produkter, som sælges til over 200 millioner kunder, med nettoomsætningsmængder på næsten 90 milliarder dollars om året.
- omfattende streaming af multimedieprogrammer, der gør det muligt for folk at se og dele videoer og andre former for omfattende indhold. Et sådant eksempel, YouTube, håndterer uploads på 300 minutters video pr. sekund.
- kommunikationssystemer i realtid til lyd-, video- og tekstchat som Skype, som giver mere end 50 milliarder minutters opkald pr. måned.
- produktivitets- og samarbejdspakker, der leverer millioner af dokumenter til mange samtidige brugere, hvilket giver mulighed for vedvarende opdateringer i realtid. Microsoft 365 hævder f.eks. at understøtte 50 millioner aktive samarbejdspartnere om måneden.
- CRM-programmer af udbydere som Salesforce, der er udrullet i mere end 100.000 organisationer. Store CRM'er giver nu intuitive dashboards til at spore status, analyse for at finde de kunder, der genererer mest forretning, og indtægtsprognoser for at forudsige fremtidig vækst.
- Datamining og business intelligence programmer, der analyserer brugen af andre tjenester (som dem ovenfor) for at finde ineffektivitet og muligheder for monetarisering.
Det er klart, at disse systemer forventes at håndtere en stor mængde samtidige brugere. Dette kræver en infrastruktur med kapacitet til at håndtere store mængder netværkstrafik, generere data og gemme data sikkert uden mærkbare forsinkelser. Disse tjenester får deres værdi ved at levere en konstant og pålidelig kvalitet. De giver også omfattende brugergrænseflader til mobilenheder og webbrowsere, hvilket gør dem nemme at bruge, men sværere at bygge og vedligeholde.
Her er en oversigt over kravene til internetbaserede systemer:
- Ubiquity: Tilgængelig overalt på et hvilket som helst tidspunkt fra en lang række enheder. En sælger forventer f.eks., at deres CRM-tjeneste leverer rettidige opdateringer på en mobilenhed for at gøre besøg hos klienter kortere, hurtigere og mere effektive. Tjenesten skal fungere problemfrit under en række netværksforbindelser.
- Høj tilgængelighed: Tjenesten skal være "altid oppe". Oppetid måles i forhold til antallet af niere. Tre niere eller 99,9%betyder, at en tjeneste ikke er tilgængelig i 9 timer om året. Fem niere (ca. 6 minutter om året) er en typisk grænse for en tjeneste med høj tilgængelighed. Selv et par minutters nedetid i online detailprogrammer kan påvirke millioner af dollars i salg.
- Lav ventetid: Hurtige og dynamiske adgangstider. Selv lidt langsommere indlæsningstider for sider har vist sig at reducere brugen af websiden markant. Hvis du f.eks. øger søgeventetiden fra 100 ms til 400 ms, reduceres antallet af søgninger pr. bruger fra 0,8% til 0,6%, og ændringen fortsætter, selv efter at ventetiden er reduceret til oprindelige niveauer.
- skalerbarhed: Evnen til at håndtere en variabel belastning, typisk på grund af sæsonudsving og viralitet, som forårsager spidsbelastninger og lavpunkter i trafikken over lange og korte perioder. På dage som "Black Friday" og "Cyber Monday," detailhandlere som Amazon skal håndtere flere gange netværkstrafikken end i gennemsnit.
- Omkostningseffektivitet: En internettjeneste kræver meget mere infrastruktur end et traditionelt program samt bedre administration. En måde at strømline omkostningerne på er ved at gøre det nemmere at administrere tjenester og reducere antallet af administratorer, der håndterer en tjeneste. Mindre tjenester har råd til at have et lavt service-til-administrator-forhold (f.eks. 2:1, hvilket betyder, at en enkelt administrator skal vedligeholde to tjenester). For at opretholde rentabiliteten skal tjenester som Microsoft Bing have et højt service-til-administrator-forhold (f.eks. 2500:1, hvilket betyder, at en enkelt administrator vedligeholder 2.500 tjenester).6
- interoperabilitet: Mange af disse tjenester bruges ofte sammen og skal derfor være en nem grænseflade til genbrug og skal understøtte standardiserede mekanismer til import og eksport af data. Mange andre tjenester (f.eks. Uber) kan f.eks. integrere Google Maps i deres produkter for at give brugerne forenklede placerings- og navigationsoplysninger.
Vi vil nu udforske nogle af de tidlige løsninger på de forskellige problemer ovenfor.7 Den første udfordring, der skal løses, var den store tur-retur tid for tidlige webtjenester, der for det meste var placeret i USA. De tidligste mekanismer til at håndtere problemerne med lav ventetid (på grund af fjernservere) og serverfejl var ganske enkelt baseret på redundans. En teknik til at opnå dette var ved at "spejle" indhold, hvor kopier af populære websider ville blive gemt på forskellige steder i verden. Dette minimerede mængden af belastning på den centrale server, reducerede den ventetid, slutbrugerne opfattede, og gjorde det muligt at skifte trafik til en anden server i tilfælde af fejl. Ulempen ved dette var en stigning i kompleksiteten for at håndtere uoverensstemmelser, hvis selv én kopi af dataene skulle ændres. Denne teknik er derfor mere nyttig til statiske, læsetunge arbejdsbelastninger, f.eks. visning af billeder, videoer eller musik. På grund af denne tekniks effektivitet bruger de fleste internetbaserede tjenester CDN'er (Content Delivery Networks) til at gemme distribuerede globale cacher med populært indhold. Cable News Network (CNN) vedligeholder f.eks. nu replikaer af videoerne på flere "edge"-servere på forskellige steder i hele verden med tilpasset reklame pr. placering.
Selvfølgelig gav det ikke altid mening for individuelle virksomheder at købe snesevis af servere over hele verden. Omkostningseffektivitet blev ofte opnået ved hjælp af delte hostingtjenester. Her udlejes aktier af en enkelt webserver til flere lejere, og omkostningerne ved servervedligeholdelse afskrives. Delte hostingtjenester kan være meget ressourceeffektive, da ressourcerne kan overprovisioneres under den antagelse, at ikke alle tjenester opererer på spidsbelastningskapacitet på samme tid. (En overprovisioned fysisk server er en server, hvor den samlede kapacitet for alle lejere er større end serverens faktiske kapacitet). Ulempen var, at det var næsten umuligt at isolere lejernes tjenester fra deres naboers tjenester. Således kan en enkelt overbelastet eller fejlbehæftet tjeneste påvirke alle sine naboer negativt. Et andet problem opstod, fordi lejere ofte kan være skadelige og forsøge at udnytte deres fordel med placering til at stjæle data eller afvise tjenesten til andre brugere.
For at modvirke dette blev virtuelle private servere udviklet som varianter af den delte hostingmodel. En lejer leveres med en virtuel maskine (VM) på en delt fysisk server. (Vi taler mere om virtuelle maskiner og deres egenskaber senere.) Disse VM'er blev ofte statisk allokeret og knyttet til en enkelt fysisk maskine, så de var svære at skalere og ofte havde brug for manuel gendannelse efter eventuelle fejl. Selvom de ikke længere kunne overprovisioned, havde de bedre ydeevne og sikkerhedsisolering mellem tjenester, der er placeret i fællesskab, end simpel ressourcedeling.
Et andet problem med deling af offentlige ressourcer var, at det krævede lagring af private data på tredjepartsinfrastrukturen. Nogle af de internetbaserede tjenester, som vi beskrev ovenfor, havde ikke råd til at miste kontrollen over datalageret, da enhver offentliggørelse af deres kunders private data ville have katastrofale konsekvenser. Derfor var disse virksomheder nødt til at bygge deres egen globale infrastruktur. Før fremkomsten af den offentlige cloud kunne sådanne tjenester kun udrulles af store virksomheder som Google og Amazon. Hver af disse virksomheder vil bygge store, homogene datacentre over hele verden ved hjælp af råvarer uden for hylden komponenter, hvor et datacenter kan opfattes som en enkelt, massiv warehouse-scale computer (WSC). En WSC gav en nem abstraktion til globalt at distribuere programmer og data, samtidig med at ejerskabet bevares.
På grund af stordriftsfordelene kan udnyttelsen af et datacenter optimeres for at reducere omkostningerne. Selvom dette stadig ikke var så effektivt som offentligt at dele ressourcer (clouden), havde disse computere i lagerskala mange ønskelige egenskaber, der fungerede som grundlag for opbygning af internetbaserede tjenester. Omfanget af beregningsprogrammer skrider fra at betjene en fast brugerbase til at betjene en dynamisk global befolkning. Standardiserede WSCs gjorde det muligt for store virksomheder at betjene så store målgrupper. En ideel infrastruktur kombinerer ydeevnen og pålideligheden af en WSC med den delte hostingmodel. Dette ville gøre det muligt for selv en lille virksomhed at udvikle og lancere en globalt konkurrencedygtig applikation uden det høje omkostninger ved at bygge store datacentre.
En anden tilgang til deling af ressourcer var gittercomputing, hvilket gjorde det muligt at dele autonome databehandlingssystemer på tværs af institutioner og geografiske placeringer. Flere akademiske og videnskabelige institutioner vil samarbejde og samle deres ressourcer mod et fælles mål. Hver institution deltager derefter i en "virtuel organisation" ved at dedikere et bestemt sæt ressourcer via veldefinerede delingsregler. Ressourcer vil ofte være heterogene og løst koblet, hvilket kræver komplekse programmeringskonstruktioner til at sy sammen. Gitrene var gearet til at støtte ikke-kommerciel forskning og akademiske projekter, og de var afhængige af eksisterende open source-teknologier.
Clouden var en logisk efterfølger, der kombinerede mange af funktionerne i ovenstående løsninger. I stedet for at universiteter f.eks. bidrager og deler adgang til en pulje af ressourcer ved hjælp af et gitter, giver cloudmiljøet dem mulighed for at lease databehandlingsinfrastruktur, der blev administreret centralt af en cloudtjenesteudbyder (CSP). Da centraludbyderen vedligeholdte en stor ressourcepulje for at tilfredsstille alle klienter, gjorde cloudmiljøet det nemmere at skalere efterspørgslen dynamisk op og ned inden for kort tid. I stedet for åbne standarder som gitteret er cloudcomputing dog afhængig af beskyttede protokoller, og brugeren skal have et vist tillidsniveau til CSP'en.
Senere i dette modul dækker vi, hvordan clouden har udviklet sig til at gøre databehandling til et offentligt værktøj, der kan forbruges og bruges.
Referencer
- Realtidsstatistikprojekt (2015). internetstatistik
- IBM (2017). Hvad er Big Data?
- Google Inc. (2015). Sådan fungerer søgning
- Hilbert, Martin og Lopez, Priscila (2011). Verdens teknologiske kapacitet til at gemme, kommunikere og beregne oplysninger
- Hamilton, James R og andre (2007). om design og installation af Internet-Scale-tjenester
- Brewer, Eric og andre (2001). Erfaringer fra gigantiske tjenester