Udviklingen af cloudcomputing
- 9 minutter
Lad os se på udviklingen i cloudcomputing.
Begivenheder og innovationer
Begrebet cloudcomputing dukkede først op i begyndelsen af 1950'erne, da flere akademikere, herunder Herb Grosch, John McCarthy og Douglas Parkhill forestillede sig databehandling som et værktøj, der ligner elektrisk strøm.1, 2 I løbet af de næste par årtier har flere nye teknologier lagt grunden til cloudcomputing. For nylig førte hurtig vækst på World Wide Web og fremkomsten af store internetgiganter, såsom Google og Amazon, endelig til oprettelsen af et økonomisk og forretningsmiljø, der gjorde det muligt for cloudcomputingmodellen at blomstre.
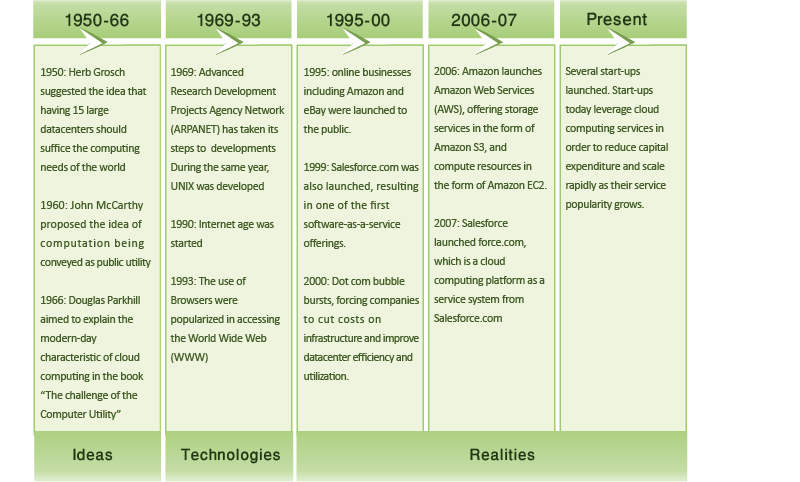
Figur 5: Udviklingen i cloudcomputing-
Udvikling af cloudcomputing
Siden 1960'erne har nogle af de tidligste former for computere, der blev brugt af organisationer, været mainframe-computere. Flere brugere kan dele og oprette forbindelse til mainframes via grundlæggende serielle forbindelser ved hjælp af terminaler. Mainframen var ansvarlig for al logik, lagring og behandling af data, og de terminaler, der var forbundet til dem, havde begrænset beregningskraft, hvis der var nogen. Disse systemer har fortsat været udbredt i mere end 30 år og eksisterer i en vis grad fortsat i dag.
Med fødslen af personlig databehandling førte billigere, mindre, mere effektive processorer og hukommelse til et sving i den modsatte retning, hvor brugerne kørte deres egen software og gemte data lokalt. Denne situation førte til problemer med ineffektiv datadeling og regler for at opretholde orden i en organisations it-miljø.
Gradvist blev lokalnetværk (LAN'er) gennem udviklingen af højhastighedsnetværksteknologier født, der gjorde det muligt for computere at oprette forbindelse og kommunikere med hinanden. Leverandørerne designede således systemer, der kunne indkapsle fordelene ved både personlige computere og mainframes, hvilket resulterede i klient-serverprogrammer, der blev populære i forhold til LAN'er. Klienter vil typisk køre klientsoftware (og behandle nogle data) eller en terminal (til ældre programmer), der er forbundet til en server. Serveren i klient-servermodellen havde program-, lager- og datalogik.
Til sidst, i 1990'erne, den globale information alder dukkede op, med internettet hurtigt ved at blive vedtaget. Netværksbåndbredden er forbedret i mange størrelsesordener fra almindelig opkaldsadgang til dedikeret fiberforbindelse i dag. Derudover opstod billigere og mere kraftfuld hardware. Desuden har udviklingen af World Wide Web og dynamiske websteder nødvendiggjort flere arkitekturer.
Multitier-arkitekturer har aktiveret modularisering af software ved at adskille programpræsentation, programlogik og lager som individuelle enheder. Med denne modularisering og afkobling var det ikke længe før, disse individuelle softwareenheder kørte på forskellige fysiske servere (typisk på grund af forskelle i hardware- og softwarekrav). Dette førte til en stigning i antallet af individuelle servere i organisationer; Det førte dog også til dårlig gennemsnitlig udnyttelse af serverhardware. I 2009 anslog International Data Corporation (IDC), at den gennemsnitlige x86-server havde en udnyttelsesgrad på ca. 5 til 10%.3
Virtual machine teknologi modnet godt nok i 2000'erne til at blive tilgængelig som kommerciel software. Virtualisering gør det muligt for en hel server at blive indkapslet som et billede, som kan køres problemfrit på hardware og gøre det muligt for flere virtuelle servere at køre samtidigt og dele hardwareressourcer. Virtualisering gør det muligt at konsolidere servere, hvilket forbedrer systemudnyttelsen.
Samtidig fik gittercomputing trækkraft i det videnskabelige samfund i et forsøg på at løse store problemer på en distribueret måde. Med gittercomputing fungerer computerressourcer fra flere administrative domæner samlet for et fælles mål. Gittercomputing medførte mange værktøjer til administration af ressourcer (f.eks. planlæggere og belastningsjusteringer) til administration af databehandlingsressourcer i stor skala.
I takt med at de forskellige databehandlingsteknologier udviklede sig, var det også økonomierne i forbindelse med databehandling. Selv i de tidlige dage med mainframe-baseret databehandling tilbød firmaer som IBM at hoste og køre computere og software til forskellige organisationer, f.eks. banker og flyselskaber. I internetalderen bliver tredjepartswebhosting også populær. Med virtualisering har udbydere dog en enestående fleksibilitet i forhold til at imødekomme flere klienter på en enkelt server og dele hardware og ressourcer mellem dem.
Udviklingen af disse teknologier kombineret med den økonomiske model for brugscomputing er det, der i sidste ende udviklede sig til cloudcomputing.
Aktivering af teknologier
Cloudcomputing har forskellige støtteteknologier, som omfatter netværk, virtualisering og ressourcestyring, utility computing, programmeringsmodeller, parallel og distribueret databehandling og lagringsteknologier.
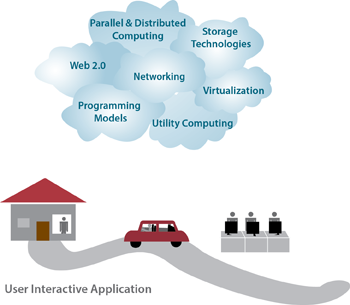
Figur 6: Aktivering af teknologier inden for cloudcomputing
Fremkomsten af højhastigheds- og allestedsnærværende netværksteknologier har i høj grad bidraget til cloudcomputing som et levedygtigt paradigme. Moderne netværk gør det muligt for computere at kommunikere hurtigt og pålideligt, hvilket er vigtigt, hvis vi skal bruge tjenester fra en cloududbyder. Dette gør det muligt at sammenligne brugeroplevelsen med software, der kører i et eksternt datacenter, med oplevelsen af software, der kører på en personlig computer. Webmail er et populært eksempel, ligesom office produktivitet software. Virtualisering er desuden nøglen til aktivering af cloudcomputing. Som nævnt ovenfor gør virtualisering det muligt at administrere kompleksiteten af cloudmiljøet ved at abstraktisere og dele sine ressourcer på tværs af brugere via flere virtuelle maskiner. Hver virtuel maskine kan udføre sit eget operativsystem og tilknyttede programprogrammer. Virtualisering til cloudcomputing beskrives i et senere modul.
Teknologier som lagersystemer i stor skala, distribuerede filsystemer og nye databasearkitekturer er afgørende for administration og lagring af data i cloudmiljøet. Cloudlagerteknologier dækkes i et senere modul.
Utility computing tilbyder mange opladningsstrukturer til leasing af beregningsressourcer. Eksempler omfatter pay-per-resource-hour, pay-per-guaranteed-throughput og pay-per-data lagret pr. måned.
Parallel og distribueret databehandling gør det muligt for distribuerede enheder, der er placeret på netværkscomputere, at kommunikere og koordinere deres handlinger for at løse visse problemer, der repræsenteres som parallelle programmer. Det er i sagens natur svært at skrive parallelle programmer til distribuerede klynger. Der kræves en programmeringsmodel for at opnå høj programmeringseffektivitet og fleksibilitet i cloudmiljøet.
Programmeringsmodeller til cloudmiljøer giver brugerne fleksibilitet til at udtrykke parallelle programmer som sekventielle beregningsenheder (f.eks. funktioner i MapReduce og vertices i GraphLab). Sådanne programmeringsmodellers runtime-systemer paralleliserer, distribuerer og planlægger beregningsenheder, administrerer kommunikation mellem enheder og tolererer fejl. Cloudprogrammeringsmodeller beskrives i et senere modul.
Referencer
- Simson L. Garfinkel (1999). Arkitekter i Informationssamfundet: Thirty-Five År for Laboratoriet for Datalogi på MIT Press
- Douglas J. Parkhill (1966). Udfordringen ved computerværktøjet Addison-Wesley forlag, Læsning, MA
- Michelle Bailey (2009). The Economics of Virtualization: Moving Toward a Application-Based Cost Model VMware Sponsored IDC Whitepaper
Tjek din viden
Feedback
Var denne side nyttig?
No
Har du brug for hjælp til dette emne?
Vil du prøve at bruge Ask Learn til at tydeliggøre eller guide dig gennem dette emne?