Forstå begreber i dyb læring
I din hjerne har du nerveceller kaldet neuroner, som er forbundet med hinanden ved nerveudvidelser, der passerer elektrokemiske signaler gennem netværket.

Når den første neuron i netværket stimuleres, behandles inputsignalet, og hvis det overskrider en bestemt grænse, aktiveres neuron og overfører signalet til de neuroner, som det er forbundet til. Disse neuroner igen kan aktiveres og sende signalet på gennem resten af netværket. Over tid styrkes forbindelserne mellem neuronerne ved hyppig brug, når du lærer at reagere effektivt. Hvis du f.eks. får vist et billede af en pingvin, giver dine neuronforbindelser dig mulighed for at behandle oplysningerne på billedet og din viden om en pingvins egenskaber for at identificere den som sådan. Over tid, hvis du får vist flere billeder af forskellige dyr, vokser netværket af neuroner, der er involveret i at identificere dyr baseret på deres karakteristiske, stærkere. Med andre ord bliver du bedre til præcist at identificere forskellige dyr.
Dyb læring emulerer denne biologiske proces ved hjælp af kunstige neurale netværk, der behandler numeriske input i stedet for elektrokemiske stimuli.
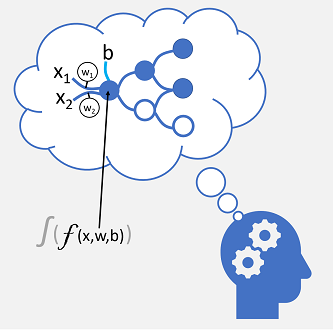
De indgående nerveforbindelser erstattes af numeriske input, der typisk identificeres som x. Når der er mere end én inputværdi, betragtes x som en vektor med elementer med navnet x1, x2 osv.
Knyttet til hver x værdi er en vægt (w), som bruges til at styrke eller svække effekten af x-værdien for at simulere læring. Derudover tilføjes en bias (b) input for at muliggøre detaljeret kontrol over netværket. Under oplæringsprocessen justeres værdierne w og b for at tilpasse netværket, så det "lærer" at producere korrekte output.
Neuron selv indkapsler en funktion, der beregner en vægtet sum af x, w og b. Denne funktion er igen omsluttet af en aktiveringsfunktion , der begrænser resultatet (ofte til en værdi mellem 0 og 1) for at afgøre, om neuron passerer et output på det næste lag af neuroner i netværket eller ej.
Oplæring af en model til dyb læring
Modeller til dyb læring er neurale netværk, der består af flere lag af kunstige neuroner. Hvert lag repræsenterer et sæt funktioner, der udføres på x-værdierne med tilknyttede w-vægte og b-forskelle , og det endelige lag resulterer i et output af det y-mærkat , som modellen forudsiger. I tilfælde af en klassificeringsmodel (som forudsiger den mest sandsynlige kategori eller klasse for inputdataene), er outputtet en vektor, der indeholder sandsynligheden for hver mulige klasse.
Følgende diagram repræsenterer en detaljeret læringsmodel, der forudsiger klassen af et dataobjekt baseret på fire funktioner ( x-værdierne ). Outputtet af modellen ( y-værdierne ) er sandsynligheden for hver af tre mulige klassemærkater.
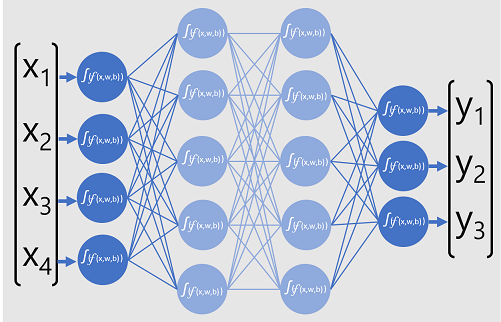
For at oplære modellen understøtter en deep learning-struktur flere batches af inputdata (som de faktiske mærkatværdier er kendt for), anvender funktionerne i alle netværkslag og måler forskellen mellem outputsandsynlighederne og de faktiske kendte klassemærkater for oplæringsdataene. Den samlede forskel mellem forudsigelsesoutputtet og de faktiske mærkater kaldes tabet.
Efter at have beregnet det samlede tab for alle batches af data bruger deep learning-strukturen en optimering til at bestemme, hvordan vægte og forskelle i modellen skal justeres for at reducere det samlede tab. Disse justeringer er derefter backpropagated til lagene i den neurale netværksmodel, og derefter overføres dataene gennem netværket igen, og tabet genberegnes. Denne proces gentages flere gange (hver gentagelse kaldes en epoke), indtil tabet er minimeret, og modellen har "lært" de rigtige vægte og forskelle for at kunne forudsige nøjagtigt.
Under hver epoke justeres vægt og bias for at minimere tabet. Det beløb, de justeres af, er underlagt den læringsfrekvens , du angiver til optimeringsfunktionen. Hvis læringsfrekvensen er for lav, kan oplæringsprocessen tage lang tid at bestemme de optimale værdier. men hvis den er for høj, finder optimeringsfunktionen muligvis aldrig de optimale værdier.