Hent og forbered data
Data er grundlaget for maskinel indlæring. Både datamængde og datakvalitet påvirker modellens nøjagtighed.
Hvis du vil oplære en model til maskinel indlæring, skal du:
- Identificer datakilde og format.
- Vælg, hvordan data skal håndteres.
- Design en dataindtagelsesløsning.
Hvis du vil hente og forberede de data , du bruger til at oplære modellen til maskinel indlæring, skal du udtrække data fra en kilde og gøre dem tilgængelige for den Azure-tjeneste, du vil bruge til at oplære modeller eller foretage forudsigelser.
Identificer datakilde og format
Først skal du identificere din datakilde og dens aktuelle dataformat.
| Identificer | Eksempler |
|---|---|
| Datakilde | Dataene kan f.eks. gemmes i et CRM-system (Customer Relationship Management), i en transaktionsdatabase som en SQL-database eller genereres af en IoT-enhed (Internet of Things). |
| Dataformat | Du skal forstå det aktuelle format af dataene, som kan være tabeldata eller strukturerede data, halvstrukturerede data eller ustrukturerede data. |
Derefter skal du beslutte, hvilke data du skal bruge for at oplære din model, og i hvilket format du vil have, at dataene skal betjenes af modellen.
Design en dataindtagelsesløsning
Generelt er det bedste praksis at udtrække data fra kilden, før du analyserer dem. Uanset om du bruger dataene til datakonstruktion, dataanalyse eller datavidenskab, vil du udtrække dataene fra kilden, transformere dem og indlæse dem i et serveringslag. En sådan proces kaldes også Udtræk, Transformér og Indlæs (ETL) eller Extract, Load og Transform (ELT). Serveringslag gør dine data tilgængelige for den tjeneste, du bruger til yderligere databehandling, f.eks. oplæring af modeller til maskinel indlæring.
Hvis du vil flytte og transformere data, kan du bruge en dataindtagelsespipeline. En dataindtagelsespipeline er en sekvens af opgaver, der flytter og transformerer dataene. Når du opretter en pipeline, kan du vælge at udløse opgaverne manuelt eller planlægge pipelinen, når opgaverne skal automatiseres. Sådanne pipelines kan oprettes med Azure-tjenester som Azure Synapse Analytics, Azure Databricks og også Azure Machine Learning.
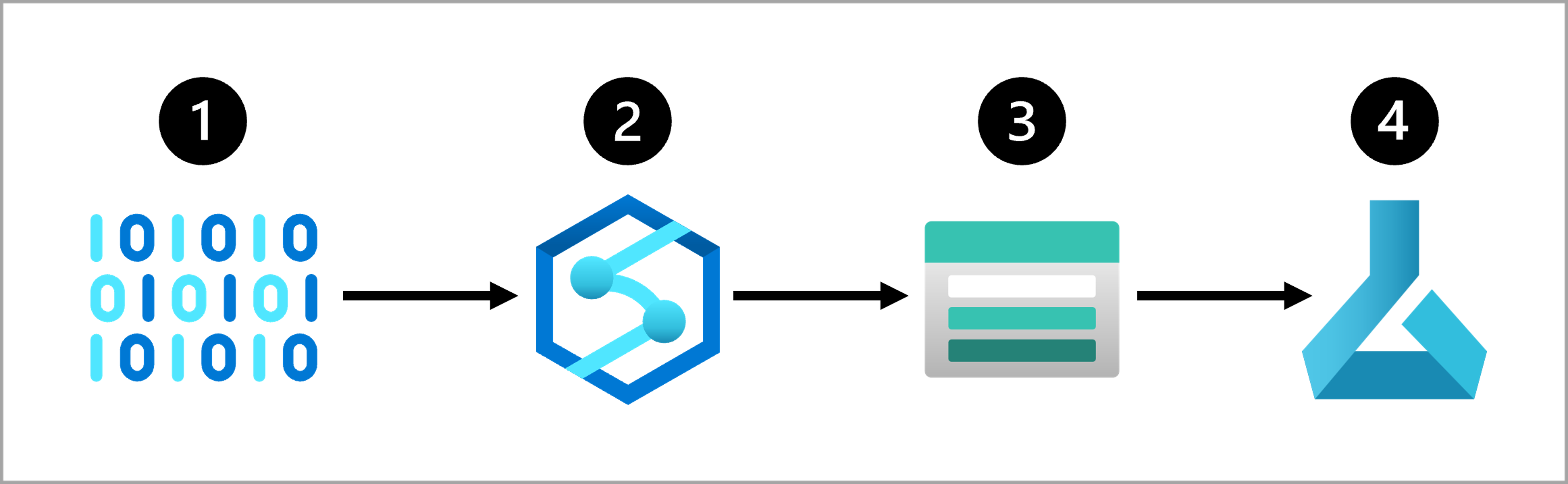
En almindelig tilgang til en dataindtagelsesløsning er at:
- Udtræk rådata fra kilden (f.eks. et CRM-system eller en IoT-enhed).
- Kopiér og transformér dataene med Azure Synapse Analytics.
- Gem de forberedte data i et Azure Blob Storage.
- Oplær modellen med Azure Machine Learning.
Udforsk et eksempel
Forestil dig, at du vil oplære en vejrudsigtsmodel. Du foretrækker én tabel, hvor alle temperaturmålinger i hvert minut kombineres. Du vil oprette aggregeringer af dataene og have en tabel med den gennemsnitlige temperatur pr. time. Hvis du vil oprette tabellen, skal du transformere de semistrukturerede data, der indtages fra den IoT-enhed, der måler temperaturen med intervaller, til tabeldata.
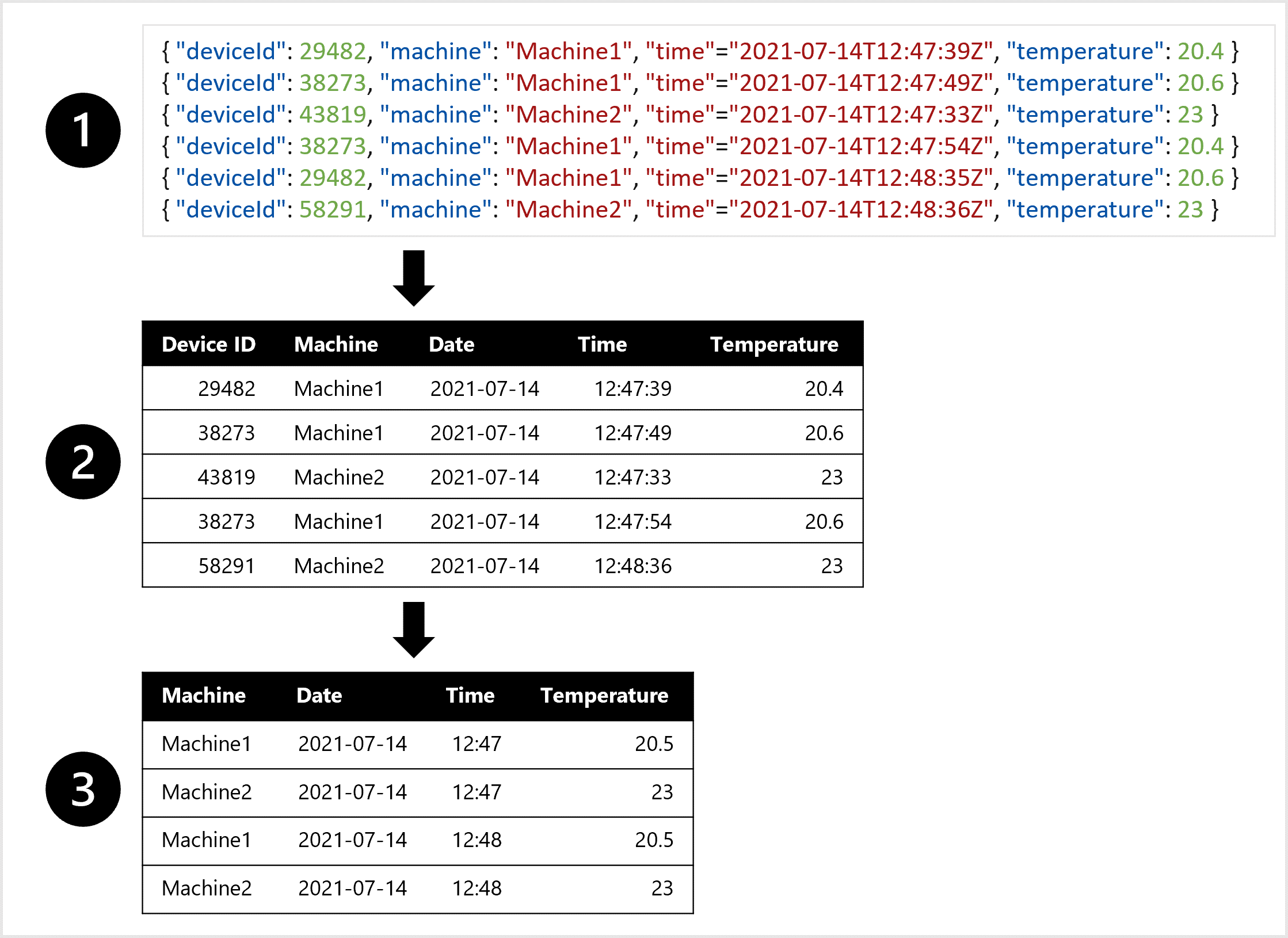
Hvis du f.eks. vil oprette et datasæt, du kan bruge til at oplære prognosemodellen, kan du:
- Udtræk datamålinger som JSON-objekter fra IoT-enhederne.
- Konvertér JSON-objekterne til en tabel.
- Transformér dataene for at få temperaturen pr. maskine pr. minut.
Lad os derefter udforske de tjenester, vi kan bruge til at oplære modeller til maskinel indlæring.