Integrer en model
Du bør planlægge, hvordan du integrerer modellen, da den påvirker den måde, du oplærer modellen på, eller hvilke oplæringsdata du bruger. Hvis du vil integrere modellen, skal du udrulle en model til et slutpunkt. Du kan udrulle en model til et slutpunkt til enten realtids- eller batchforudsigelser.
Udrul en model til et slutpunkt
Når du oplærer en model, er målet ofte at integrere modellen i et program.
Hvis du nemt vil integrere en model i et program, kan du bruge slutpunkter. Kort sagt kan et slutpunkt være en webadresse, som et program kan kalde for at få en meddelelse tilbage.
Når du udruller en model til et slutpunkt, har du to muligheder:
- Hent forudsigelser i realtid
- Hent batchforudsigelser
Hent forudsigelser i realtid
Hvis du vil have, at modellen skal score nye data, efterhånden som de kommer ind, skal du have forudsigelser i realtid.
Forudsigelser i realtid er ofte nødvendige, når en model bruges af et program, f.eks. en mobilapp eller et websted.
Forestil dig, at du har et websted, der indeholder dit produktkatalog:
- En kunde vælger et produkt på dit websted, f.eks. en skjorte.
- Baseret på kundens valg anbefaler modellen straks andre elementer fra produktkataloget. På webstedet vises modellens anbefalinger.

En kunde kan når som helst vælge et produkt i webshoppen. Du vil gerne have, at modellen finder anbefalingerne næsten med det samme. Den tid, det tager for websiden at indlæse og vise skjortedetaljerne, er den tid, det skal tage at få anbefalingerne eller forudsigelserne. Når skjorten derefter vises, kan anbefalingerne også vises.
Hent batchforudsigelser
Hvis modellen skal score nye data i batches og gemme resultaterne som en fil eller i en database, skal du bruge batchforudsigelser.
Du kan f.eks. oplære en model, der forudsiger salg af appelsinjuice for hver kommende uge. Ved at forudsige salget af appelsinjuice kan du sikre, at udbuddet er tilstrækkeligt til at imødekomme den forventede efterspørgsel.
Forestil dig, at du visualiserer alle historiske salgsdata i en rapport. Du skal inkludere det forudsagte salg i den samme rapport.
Selvom appelsinjuice sælges hele dagen, vil du kun beregne prognosen en gang om ugen. Du kan indsamle salgsdataene i løbet af ugen og kun kalde modellen, når du har salgsdataene for en hel uge. En samling af datapunkter kaldes en batch.
Beslut mellem udrulning i realtid eller batch
Hvis du vil beslutte, om du vil designe en løsning til installation i realtid eller batchinstallation, skal du overveje følgende spørgsmål:
- Hvor ofte skal forudsigelser genereres?
- Hvor hurtigt er resultaterne nødvendige?
- Skal forudsigelser genereres enkeltvist eller i batches?
- Hvor meget beregningskraft kræves for at udføre modellen?
Identificer den nødvendige hyppighed for scoring
Et almindeligt scenarie er, at du bruger en model til at score nye data. Før du kan få forudsigelser i realtid eller i batch, skal du først indsamle de nye data.
Der er forskellige måder at generere eller indsamle data på. Nye data kan også indsamles med forskellige tidsintervaller.
Du kan f.eks. indsamle temperaturdata fra en IoT-enhed (Internet of Things) hvert minut. Du kan få transaktionsdata, hver gang en kunde køber et produkt fra din webshop. Eller du kan udtrække økonomiske data fra en database hver tredje måned.
Generelt er der to typer use cases:
- Du skal bruge modellen til at score de nye data, så snart de kommer ind.
- Du kan planlægge eller udløse modellen for at score de nye data, du har indsamlet over tid.
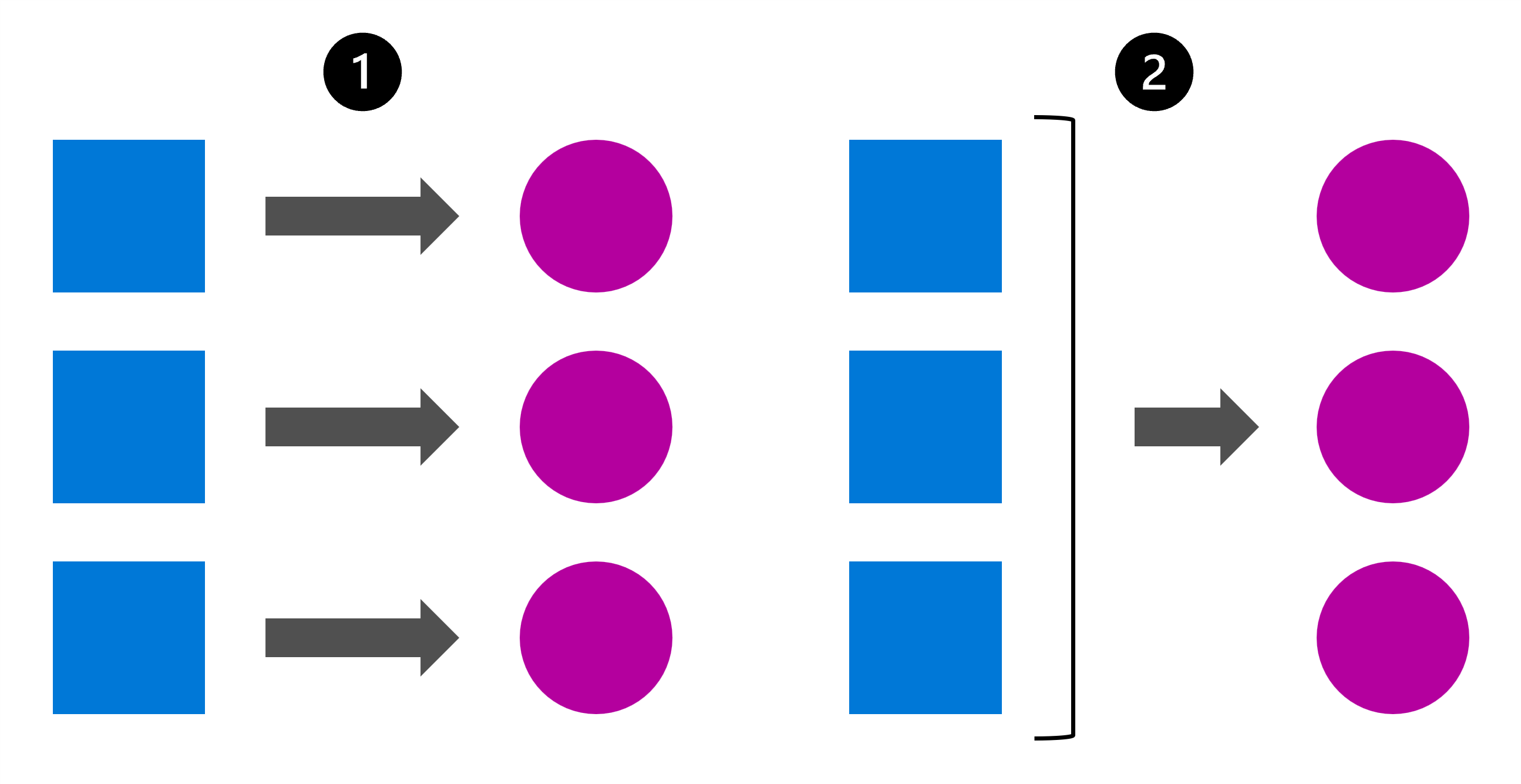
Uanset om du vil have forudsigelser i realtid eller batch, afhænger det ikke nødvendigvis af, hvor ofte nye data indsamles. I stedet afhænger det af, hvor ofte og hvor hurtigt du har brug for, at forudsigelserne genereres.
Hvis du har brug for modellens forudsigelser med det samme, når der indsamles nye data, skal du bruge forudsigelser i realtid. Hvis modellens forudsigelser kun forbruges på bestemte tidspunkter, skal du bruge batchforudsigelser.
Beslut antallet af forudsigelser
Et andet vigtigt spørgsmål, du skal stille dig selv, er, om du har brug for, at forudsigelserne genereres enkeltvist eller i batches.
En nem måde at illustrere forskellen mellem individuelle forudsigelser og batchforudsigelser på er ved at forestille sig en tabel. Antag, at du har en tabel med kundedata, hvor hver række repræsenterer en kunde. For hver kunde har du nogle demografiske data og adfærdsdata, f.eks. hvor mange produkter de har købt fra din webshop, og hvornår deres sidste køb var.
Baseret på disse data kan du forudsige kundeafgang: om en kunde vil købe fra din webshop igen eller ej.
Når du har oplært modellen, kan du beslutte, om du vil generere forudsigelser:
- Individuelt: Modellen modtager en enkelt række med data og returnerer, om den enkelte kunde vil købe igen.
- Batch: Modellen modtager flere rækker med data i én tabel og returnerer, om hver kunde køber igen. Resultaterne sorteres i en tabel, der indeholder alle forudsigelser.
Du kan også generere individuelle forudsigelser eller batchforudsigelser, når du arbejder med filer. Når du f.eks. arbejder med en computervisionsmodel, skal du muligvis score et enkelt billede enkeltvist eller en samling af billeder i ét batch.
Overvej beregningsomkostningerne
Ud over at bruge beregning, når du oplærer en model, skal du også bruge beregning, når du udruller en model. Afhængigt af om du udruller modellen til et realtids- eller batchslutpunkt, skal du bruge forskellige beregningstyper. Hvis du vil beslutte, om du vil udrulle din model til et realtids- eller batchslutpunkt, skal du overveje omkostningerne for hver beregningstype.
Hvis du har brug for forudsigelser i realtid, skal du bruge en beregning, der altid er tilgængelig og kan returnere resultaterne (næsten) med det samme. Objektbeholderteknologier som Azure Container Instance (ACI) og Azure Kubernetes Service (AKS) er ideelle til scenarier, da de giver en letvægtsinfrastruktur til din udrullede model.
Men når du udruller en model til et slutpunkt i realtid og bruger denne objektbeholderteknologi, er beregningen altid aktiveret. Når en model er udrullet, betaler du løbende for beregningen, da du ikke kan afbryde beregningen midlertidigt eller stoppe beregningen, da modellen altid skal være tilgængelig til øjeblikkelige forudsigelser.
Hvis du har brug for batchforudsigelser, skal du også bruge beregning, der kan håndtere en stor arbejdsbelastning. Ideelt set skal du bruge en beregningsklyng , der kan score dataene i parallelle batches ved hjælp af flere noder.
Når du arbejder med beregningsklynger, der kan behandle data i parallelle batches, klargøres beregningen af arbejdsområdet, når batch-scoren udløses, og skaleres ned til 0 noder, når der ikke er nye data at behandle. Ved at lade arbejdsområdet skalere en inaktiv beregningsklynge ned, kan du spare betydelige omkostninger.