Indførelsen
Azure Databricks er en cloudbaseret dataplatform, der samler det bedste inden for datateknik, datavidenskab og maskinel indlæring i et enkelt, samlet arbejdsområde. Den er bygget oven på Apache Spark og giver organisationer mulighed for nemt at behandle, analysere og visualisere enorme mængder data i realtid.
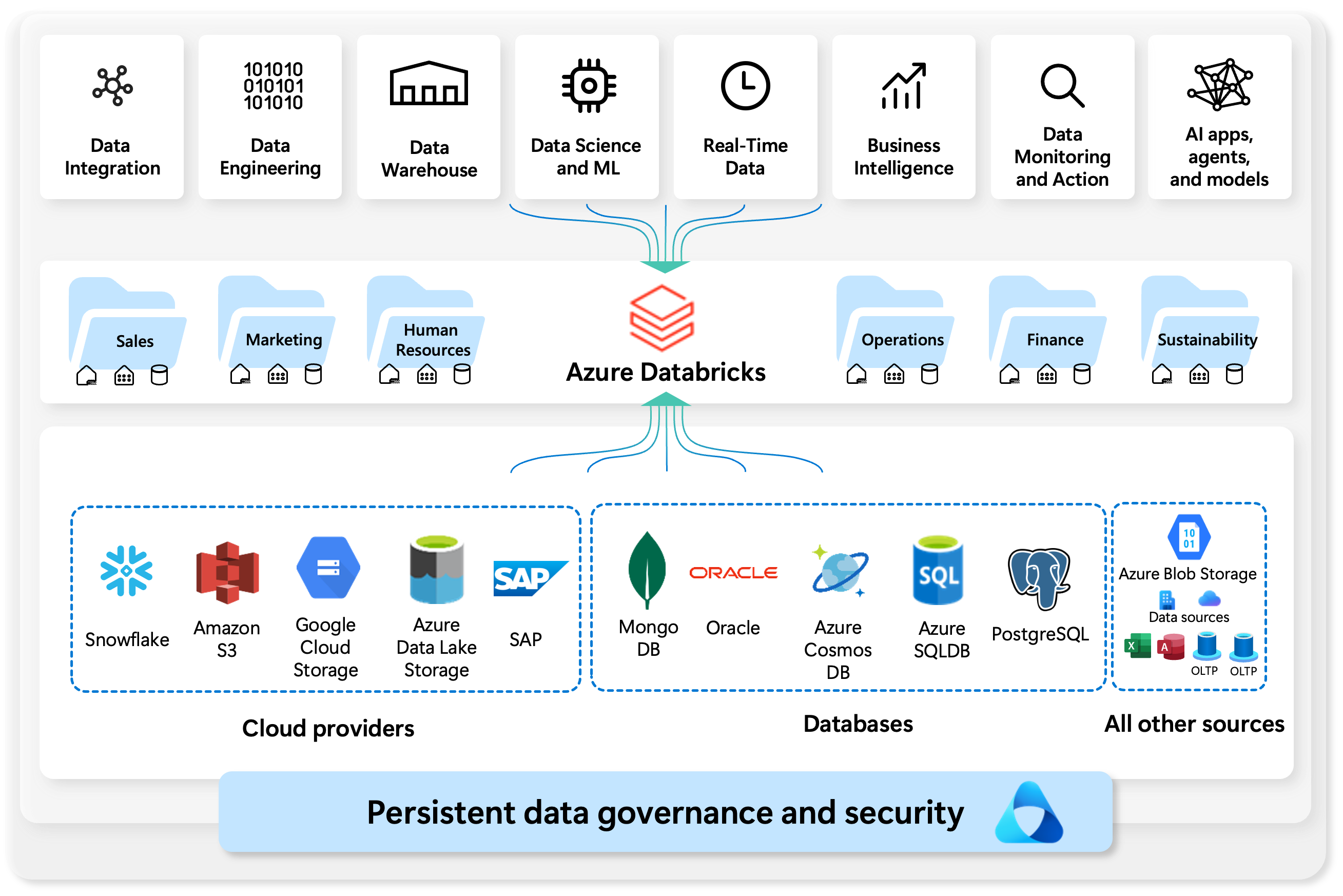
Ved at oprette forbindelse til en lang række datakilder – fra cloududbydere som Azure SQL Database, Amazon S3 og Google Cloud Storage til virksomhedssystemer som SAP og Oracle – gør Azure Databricks det nemt at integrere og transformere data overalt.
Når data er indtaget, kan teams på tværs af salg, marketing, drift, økonomi, HR og bæredygtighed bruge Databricks til avanceret analyse, maskinel indlæring, business intelligence og AI-baseret indsigt.
Azure Databricks hjælper i bund og grund organisationer:
- Integrer data fra flere kilder
- Konstruer og transformer rådata til brugbare formater
- Gem og administrer data effektivt med styring og sikkerhed
- Anvend realtidsanalyse, maskinel indlæring og AI-modeller
- Skab bedre forretningsbeslutninger og resultater
Data Lakehouse
Et datalakehouse er en datastyringstilgang, der blander styrkerne ved både datasøer og datavarehuse. Det tilbyder skalerbar lagring og behandling, der giver organisationer mulighed for at håndtere forskellige arbejdsbelastninger – såsom maskinlæring og business intelligence – uden at være afhængige af separate, afbrudte systemer. Ved at centralisere data understøtter et søhus en enkelt kilde til sandhed, reducerer dobbeltomkostninger og sikrer, at oplysningerne forbliver opdaterede.
Mange søhuse følger et lagdelt designmønster, hvor data gradvist forbedres, beriges og forfines, efterhånden som de bevæger sig gennem forskellige stadier af behandlingen. Denne lagdelte tilgang – almindeligvis kaldet medaljonarkitekturen – organiserer data i faser, der bygger på hinanden, hvilket gør det nemmere at administrere og bruge effektivt.
Databricks søhuset bruger to nøgleteknologier:
- Delta Lake: et optimeret lagerlag, der understøtter ACID-transaktioner og håndhævelse af skemaer.
- Unity Catalog: en samlet, finkornet styringsløsning til data og AI.