Beskriv normalisering
Databasenormalisering er en designproces, der bruges til at organisere data i tabeller og kolonner i en database. Hver tabel skal indeholde data, der er relateret til et bestemt objekt, og kun indeholde oplysninger, der understøtter det pågældende objekt. Det primære mål med normalisering er at minimere dublerede data i databasen, hvilket hjælper med at forhindre forringelse af ydeevnen under indsættelser og opdateringer. Hvis en kundes adresse f.eks. skal opdateres, er det nemmere at implementere ændringen, hvis adressen er gemt på en enkelt placering, f.eks. tabellen Customers .
De mest almindelige former for normalisering er første, anden og tredje normale formularer.
Første normale formular
Den første normale formular har følgende specifikationer:
- Opret en separat tabel for hvert sæt relaterede data
- Fjern gentagne grupper i individuelle tabeller
- Identificer hvert sæt relaterede data med en primær nøgle
I denne model bør du undgå at bruge flere kolonner i en enkelt tabel til at gemme lignende data. Hvis et produkt f.eks. kan komme i flere farver, bør du ikke have flere kolonner i en enkelt række, der indeholder de forskellige farveværdier. Den første følgende tabel, , ProductColorser ikke i første normale form, fordi den har gentagne værdier for farve. For produkter med kun én farve er der spildt plads. Hvis et produkt fås i mere end tre farver, bliver det desuden upraktisk at angive et maksimalt antal kolonner. I stedet kan vi genoprette tabellen, som vist i den anden tabel, ProductColor.
Den første normale formular kræver også, at der er en entydig nøgle til tabellen, som er en kolonne (eller kolonner), hvis værdi entydigt identificerer hver række. I den anden tabel er ingen af kolonnerne entydige alene, men tilsammen udgør kombinationen af ProductID og Color en entydig nøgle. Når der er brug for flere kolonner for at oprette en entydig nøgle, kaldes den for en sammensat nøgle.
ProductColorsbord:#B0 ProductID-#C1 #C1 #B0 Color1 #C1 #B0 Color2 #C1 #B0 Color3 1 Rød Grøn Gul 2 Gul 3 Blå Rød 4 Blå 5 Rød ProductColorbord:#B0 ProductID-#C1 Farve 1 Rød 1 Grøn 1 Gul 2 Gul 3 Blå 3 Rød 4 Blå 5 Rød
Den tredje tabel, , er i første normale form, ProductInfofordi hver række refererer til et bestemt produkt, der ikke er gentagne grupper, og vi har kolonnen ProductID, der skal bruges som primær nøgle.
| #B0 ProductID-#C1 | #B0 ProductName-#C1 | Pris | #C1 #B0 ProductionCountry | #B0 ShortLocation-#C1 |
|---|---|---|---|---|
| 1 | Widget | 15.95 | USA | US |
| 2 | Foop | 41.95 | Storbritannien | Storbritannien |
| 3 | Glombit | 49.95 | Storbritannien | Storbritannien |
| 4 | Sorfin | 99.99 | Republikken Filippinerne | RepPhil |
| 5 | Stængel bolt | 29.95 | USA | US |
Anden normalformular
Den anden normale formular har følgende specifikation ud over dem, der kræves i den første normale formular:
- Hvis tabellen har en sammensat nøgle, skal alle attributter afhænge af den komplette nøgle og ikke kun en del af den.
Den anden normale formular er kun relevant for tabeller med sammensatte nøgler, f.eks. i tabellen ProductColor, som er den anden tabel. Overvej det tilfælde, hvor tabellen ProductColor også indeholder produktets pris. Denne tabel har en sammensat nøgle på ProductID og Color, da det kun er ved hjælp af begge kolonneværdier, at vi entydigt kan identificere en række. Hvis et produkts pris ikke ændres med farven, kan vi muligvis se data som vist i denne tabel.
| #B0 ProductID-#C1 | Farve | Pris |
|---|---|---|
| 1 | Rød | 15.95 |
| 1 | Grøn | 15.95 |
| 1 | Gul | 15.95 |
| 2 | Gul | 41.95 |
| 3 | Blå | 49.95 |
| 3 | Rød | 49.95 |
| 4 | Blå | 99.95 |
| 5 | Rød | 29.95 |
Denne tabel er ikke i anden normal form. Prisværdien afhænger af , ProductID men ikke af Color. Der er tre rækker for ProductID 1, så prisen for det pågældende produkt gentages tre gange. Problemet med at overtræde den anden normale formular er, at hvis vi har brug for at opdatere prisen, skal vi sikre, at den opdateres overalt. Hvis vi opdaterer prisen i den første række, men ikke i den anden eller tredje, vil der opstå en opdateringsuregel. Efter opdateringen kan vi ikke bestemme den faktiske pris for ProductID 1. Løsningen er at flytte kolonnen Price til en tabel, der har ProductID som en enkelt kolonnenøgle, fordi det er den eneste kolonne, der Price afhænger af. Vi kan f.eks. bruge Tabel 3 til at gemme Price.
Hvis prisen for et produkt var anderledes baseret på dets farve, ville den fjerde tabel være i den anden normale form, da prisen afhænger af begge dele af nøglen: ProductID og Color.
Tredje normale formular
Tredje normale form er typisk målet for de fleste OLTP-databaser. Den tredje normale formular har følgende specifikation ud over dem, der kræves i den anden normale formular:
- Alle ikke-nøglekolonner er ikke-transitive afhængige af den primære nøgle.
En transitiv relation betyder, at én kolonne i en tabel er relateret til andre kolonner via en anden kolonne. Afhængighed betyder, at en kolonne kan udlede dens værdi fra en anden som et resultat af denne relation. Din alder kan f.eks. bestemmes ud fra din fødselsdato, hvilket gør din alder afhængig af din fødselsdato. Se den tredje tabel, ProductInfo. Denne tabel er i anden normal form, men ikke i tredje. Kolonnen ShortLocation er afhængig af kolonnen ProductionCountry , som ikke er nøglen. Ligesom den anden normale formular kan overtrædelse af tredje normale formular føre til opdatering af uregelmæssigheder. Vi ville ende med inkonsekvente data, hvis vi opdaterede ShortLocation i én række, men ikke opdaterede dem i alle de rækker, hvor placeringen fandt sted. For at forhindre dette kan vi oprette en separat tabel til lagring af lande-/områdenavne og deres forkortede formularer.
Denormalisering
Selvom den tredje normale form er teoretisk ønskelig, er det ikke altid muligt for alle data. Desuden giver en normaliseret database dig ikke altid den bedste ydeevne. Normaliserede data kræver ofte flere joinhandlinger for at få alle de nødvendige data returneret i en enkelt forespørgsel. Der er en afvej mellem at normalisere data, når antallet af joinforbindelser, der kræves for at returnere forespørgselsresultater, har en høj CPU-udnyttelse, og deormaliserede data, der har færre joinforbindelser og mindre CPU-påkrævet, men åbner op for muligheden for opdatering af uregelmæssigheder.
Deormaliserede data kan være mere effektive at forespørge på, især for læsetunge arbejdsbelastninger som f.eks. et data warehouse. I disse tilfælde kan det give bedre forespørgselsmønstre og/eller mere forenklede forespørgsler at have ekstra kolonner.
Stjerneskema
Selvom de fleste normaliseringer er rettet mod OLTP-arbejdsbelastninger, har data warehouses deres egen udformningsstruktur, som typisk er en denormaliseret model. Dette design bruger faktatabeller til at registrere målinger eller målepunkter for bestemte hændelser, f.eks. salg, og joinforbinder dem til dimensionstabeller. Dimensionstabeller er mindre med hensyn til rækkeantal, men kan have et stort antal kolonner til at beskrive faktadataene. Eksempler på dimensioner omfatter lager, tid og geografi. Dette designmønster gør det nemmere at forespørge på databasen og giver bedre ydeevne for læsearbejdsbelastninger.
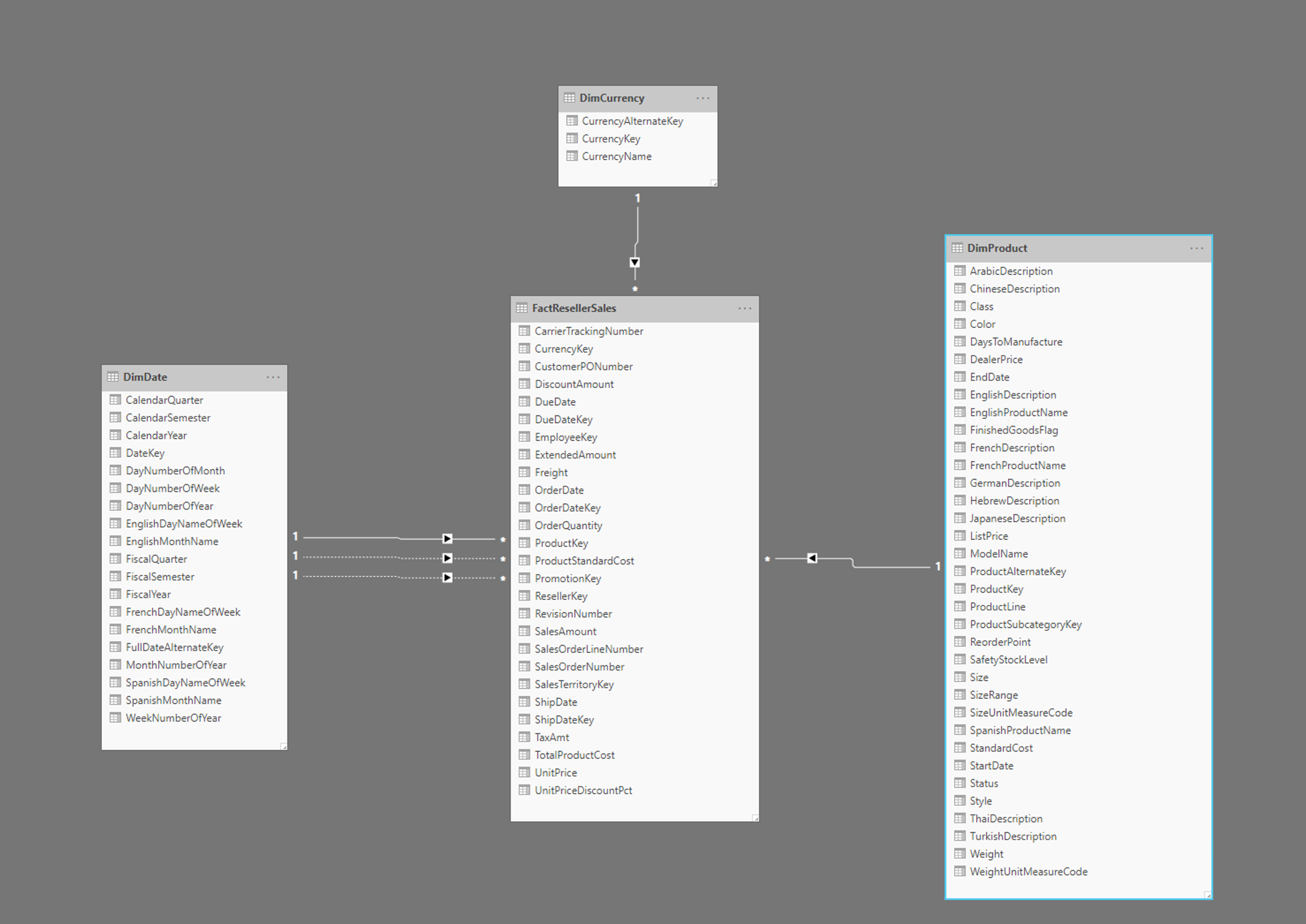
Billedet illustrerer et eksempel på et stjerneskema med en FactResellerSales faktatabel og dimensioner for dato, valuta og produkter. Faktatabellen indeholder data, der er relateret til salgstransaktioner, mens dimensionerne kun indeholder data, der er relateret til bestemte elementer i salgsdataene. Tabellen indeholder f.eks FactResellerSales . kun en ProductKey for at angive, hvilket produkt der blev solgt. Alle detaljer om hvert produkt gemmes i DimProduct tabellen og er relateret tilbage til faktatabellen ved hjælp af kolonnen ProductKey .
Relateret til stjerneskemadesign er snowflake-skemaet, som bruger et sæt mere normaliserede tabeller til en enkelt forretningsenhed. Følgende billede illustrerer et eksempel på en enkelt dimension i et snowflake-skema. Dimensionen Products normaliseres og gemmes på tværs af tre tabeller: DimProductCategory, DimProductSubcategoryog DimProduct.
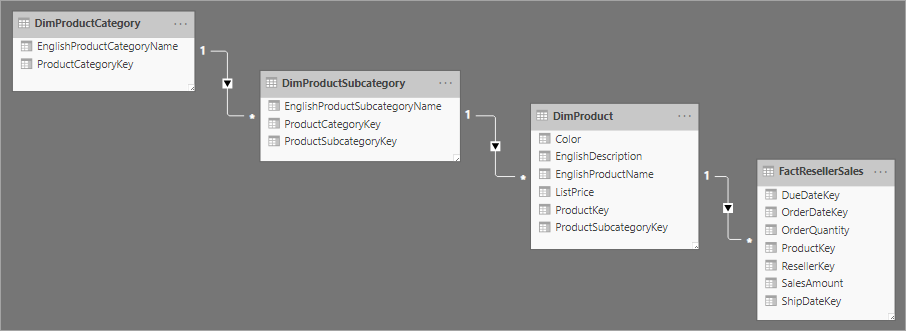
Den primære forskel mellem stjerne- og snowflake-skemaer er, at dimensionerne i et snowflake-skema normaliseres for at reducere redundansen, hvilket sparer lagerplads. Afvejninger er, at dine forespørgsler kræver flere joinforbindelser, hvilket kan øge din kompleksitet og reducere ydeevnen.