Design indekser
SQL Server indeholder flere indekstyper, der understøtter forskellige arbejdsbelastninger. På et højt niveau kan et indeks opfattes som en diskstruktur, der er knyttet til en tabel eller visning, så SQL Server nemmere kan finde den eller de rækker, der er knyttet til indeksnøglen (som består af en eller flere kolonner i tabellen eller visningen), sammenlignet med scanning af hele tabellen.
Grupperede indeks
Et almindeligt DBA-jobsamtalespørgsmål er at stille kandidaten forskellen mellem et grupperet og ikke-grupperet indeks, da indekser er grundlæggende datalagringsteknologier i SQL Server. Et grupperet indeks er den underliggende tabel, der er gemt i sorteret rækkefølge baseret på nøgleværdien. Der kan kun være ét grupperet indeks i en given tabel, fordi rækkerne kun kan gemmes i én rækkefølge. En tabel uden et grupperet indeks kaldes en heap, og heaps bruges typisk kun som midlertidige tabeller. Et vigtigt princip for ydeevnedesign er at holde din grupperede indeksnøgle så smal som muligt. Når du overvejer en eller flere nøglekolonner til dit grupperede indeks, skal du vælge kolonner, der er entydige eller indeholder mange forskellige værdier. En anden egenskab for en god grupperet indeksnøgle er for poster, der tilgås sekventielt og bruges ofte til at sortere de data, der hentes fra tabellen. Hvis du har det grupperede indeks i den kolonne, der bruges til sortering, kan det forhindre omkostningerne ved sortering, hver gang forespørgslen udføres, fordi dataene allerede gemmes i den ønskede rækkefølge.
Seddel
Når vi siger, at tabellen er 'gemt' i en bestemt rækkefølge, henviser vi til den logiske rækkefølge, ikke den fysiske rækkefølge på disken. Indekser har markørerne mellem sider, og pointerene hjælper med at oprette den logiske rækkefølge. Når du scanner et indeks i rækkefølge, følger SQL Server markøren fra side til side. Umiddelbart efter at du har oprettet et indeks, gemmes det sandsynligvis også i fysisk rækkefølge på disken, men når du er begyndt at foretage ændringer af dataene, og nye sider skal føjes til indekset, giver pegepindene os stadig den korrekte logiske rækkefølge, men de nye sider vil sandsynligvis ikke være i fysisk diskrækkefølge.
Ikke-eksklusive indekser
Ikke-kluderede indeks er separate strukturer fra datarækkerne. Et ikke-eksklusivt indeks indeholder de nøgleværdier, der er defineret for indekset, og en pointer til den datarække, der indeholder nøgleværdien. Du kan føje ekstra ikke-nøglekolonner til bladniveauet i det ikke-inkluderede indeks ved hjælp af funktionen inkluderede kolonner i SQL Server, så du kan dække flere kolonner. Du kan oprette flere ikke-afhængige indeks i en tabel.
I følgende eksempel kan du se, hvornår du har brug for at føje et indeks eller føje kolonner til et eksisterende ikke-gyldigt indeks.

Forespørgselsplanen angiver, at der skal hentes flere data fra det grupperede indeks (selve tabellen) for hver række, der hentes ved hjælp af indekssøgningen. Der er et ikke-inkluderet indeks, men det indeholder kun produktkolonnen. Hvis du føjer de andre kolonner i forespørgslen til et indeks, der ikke er med i listen, kan du se ændringen af udførelsesplanen for at fjerne nøgleopslag.

Det indeks, der er oprettet ovenfor, er et eksempel på et dækker indeks. Ud over nøglekolonnen inkluderer du ekstra kolonner for at dække forespørgslen og fjerne behovet for at få adgang til selve tabellen.
Både ikke-grupperede og grupperede indeks kan defineres som entydige, hvilket betyder, at der ikke kan være duplikering af nøgleværdierne. Entydige indeks oprettes automatisk, når du opretter en PRIMÆR NØGLE eller EN ENTYDIG begrænsning i en tabel.
I dette afsnit fokuseres der på b-træindekser i SQL Server, også kaldet rækkelagerindekser. Følgende billede repræsenterer den generelle struktur i et b-træ:
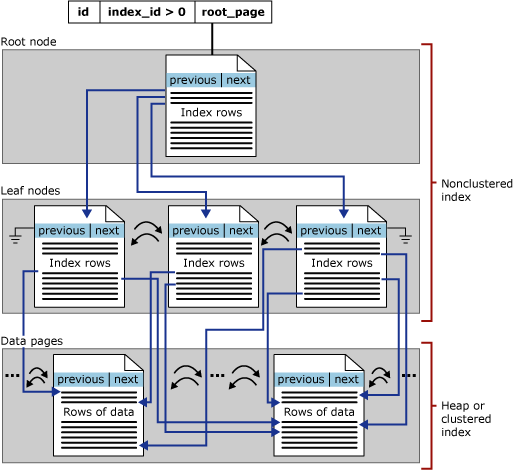
Hver side i et indeks-b-træ kaldes en indeksnode, og den øverste node i b-træet kaldes rodnoden. De nederste noder i et indeks kaldes bladnoder, og samlingen af bladnoder er bladniveauet.
Index design er en blanding af kunst og videnskab. Et smalt indeks med få kolonner i nøglen kræver mindre tid at opdatere og har lavere vedligeholdelsesomkostninger. Det er dog muligvis ikke nyttigt for så mange forespørgsler som et bredere indeks, der indeholder flere kolonner. Du skal muligvis eksperimentere med flere indekseringsmetoder baseret på de kolonner, der er valgt af programmets forespørgsler. Forespørgselsoptimeringsprogrammet vælger generelt, hvad det anser for at være det bedste eksisterende indeks for en forespørgsel. Det betyder dog ikke, at der ikke er et bedre indeks, der kan oprettes.
Korrekt indeksering af en database kan være en kompleks opgave. Når du planlægger dine indeks for en tabel, skal du være opmærksom på nogle grundlæggende principper:
- Forstå systemets arbejdsbelastninger. Tabeller, der primært bruges til indsættelseshandlinger, drager mindre fordel af ekstra indekser sammenlignet med tabeller, der bruges til data warehouse-handlinger med høj læseaktivitet.
- Optimer indekser omkring de oftest kørte forespørgsler.
- Vælg de relevante datatyper til kolonner i dine forespørgsler. Indeks fungerer bedst med heltalsdatatyper, entydige kolonner eller kolonner, der ikke er null.
- Opret ikke-eksklusive indekser for kolonner, der ofte bruges i prædikater og joinforbindelsesklausuler, så de er så smalle som muligt for at minimere spild.
- Overvej datastørrelse/volumen. Tabelscanninger på små tabeller er relativt billige, mens scanninger på store tabeller er dyre.
En anden mulighed, der leveres af SQL Server, er oprettelsen af filtrerede indeks. Filtrerede indeks er ideelle til kolonner i store tabeller, hvor en betydelig procentdel af rækkerne deler den samme værdi i den pågældende kolonne. Følgende eksempel er en medarbejdertabel, der gemmer poster for alle medarbejdere, herunder dem, der har forladt eller pensioneret.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
I denne tabel er der en kolonne med navnet CurrentFlag, som angiver, om en medarbejder er ansat i øjeblikket. I dette eksempel bruges bit datatypen, der repræsenterer to værdier: én for aktuelt ansat og nul for ikke aktuelt ansat. Oprettelse af et filtreret indeks med WHERE CurrentFlag = 1 i kolonnen CurrentFlag giver mulighed for effektive forespørgsler fra aktuelle medarbejdere.
Du kan også oprette indekser for visninger, hvilket kan give betydelige forbedringer af ydeevnen, når visninger indeholder forespørgselselementer, f.eks. sammenlægninger og/eller tabeljoinforbindelser.
Columnstore-indekser
Columnstore-indekser giver forbedret ydeevne for forespørgsler, der involverer store sammenlægningsarbejdsbelastninger. Columnstore-indekser, der oprindeligt var målrettet til data warehouses, er siden blevet vedtaget for forskellige andre arbejdsbelastninger for at løse problemer med forespørgselsydeevnen i store tabeller. På samme måde som med b-træindeks repræsenterer et grupperet columnstore-indeks selve tabellen, der er gemt på en særlig måde, mens ikke-grupperede columnstore-indeks gemmes uafhængigt af tabellen. Grupperede columnstore-indeks omfatter i sagens natur alle kolonner i en tabel, men sorteres ikke.
Ikke-eksklusive columnstore-indeks bruges typisk i to scenarier. Den første er, når en kolonnes datatype ikke understøttes i et columnstore-indeks (f.eks. XML, CLR, sql_variant, ntext, tekst og billede). Da et grupperet columnstore-indeks altid indeholder alle kolonner i tabellen, er et ikke-grupperet indeks den eneste mulighed. Det andet scenarie omfatter filtrerede indekser, der bruges i HTAP-arkitekturer (Hybrid Transactional Analytic Processing), hvor data indlæses i tabellen, mens rapporter køres samtidigt. Filtrering af indekset (typisk på et datofelt) giver mulighed for effektiv ydeevne af indsættelse og rapportering.
Columnstore-indekser lagrer hver kolonne uafhængigt af hinanden og giver to fordele: reduceret IO ved kun at scanne nødvendige kolonner og større komprimering på grund af lignende data i kolonner. De klarer sig bedst på analyseforespørgsler, der scanner store datasæt, f.eks. faktatabeller i data warehouses. Du kan øge et columnstore-indeks med et ikke-eksklusivt b-træindeks for opslag med singletonværdier.
Disse indeks drager også fordel af batchudførelsestilstanden, hvor rækkesæt (typisk ca. 900) behandles ad gangen i stedet for én efter én. Denne fremgangsmåde reducerer CPU-instruktioner betydeligt.
SELECT SUM(Sales) FROM SalesAmount;
Batchtilstand kan øge ydeevnen i forhold til traditionel rækkebehandling. Selvom batchtilstanden for rowstore ikke har samme niveau af læseydeevne som et columnstore-indeks, kan analyseforespørgsler muligvis se en forbedring af ydeevnen på op til 5x.
En anden fordel ved columnstore-indekser for arbejdsbelastninger i data warehouse er den optimerede indlæsningssti til masseindsætningshandlinger på 102.400 rækker eller mere. Mens 102.400 er den minimumværdi, der skal indlæses direkte i columnstore, kan hver samling af rækker, der kaldes en rækkegruppe, være op til ca. 1.024.000 rækker. Hvis du har færre, men mere komplette rækkegrupper, bliver dine SELECT forespørgsler mere effektive, fordi der skal scannes færre rækkegrupper for at hente de ønskede poster. Disse belastninger forekommer i hukommelsen og indlæses direkte i indekset. For mindre mængder skrives data til en b-træstruktur, der kaldes et deltalager, og som asynkront indlæses i indekset.
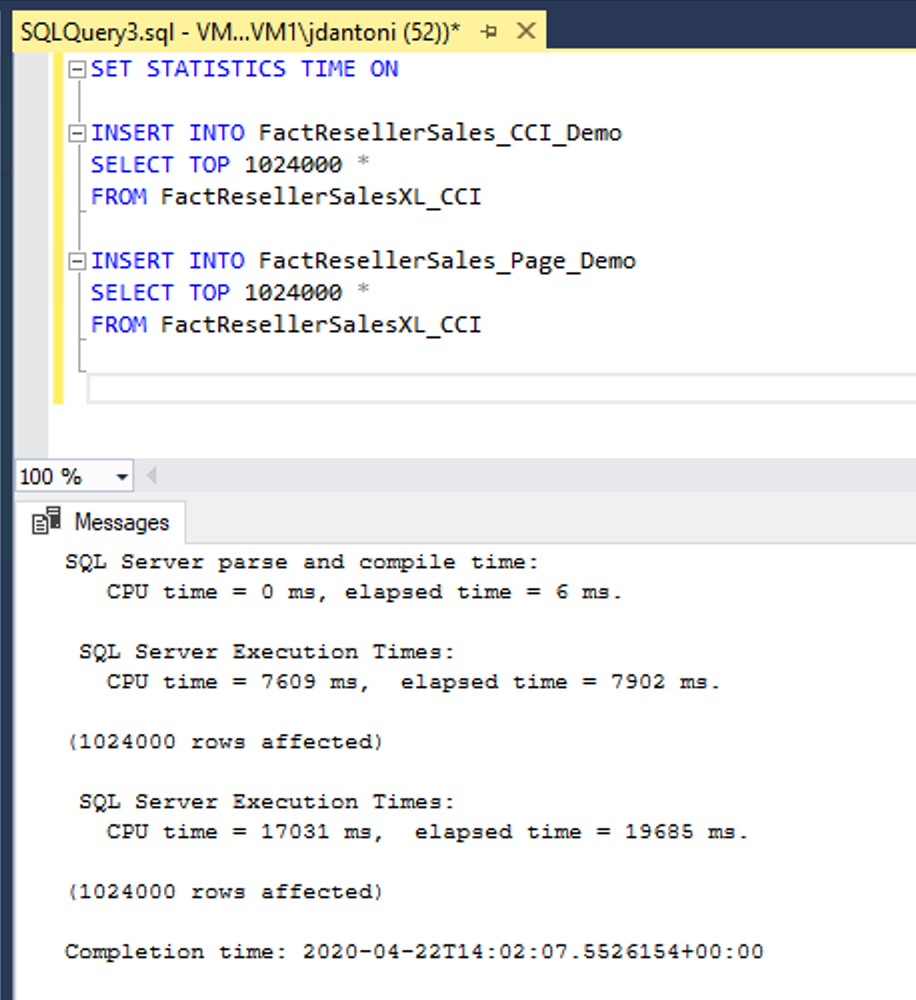
I dette eksempel indlæses de samme data i to tabeller, FactResellerSales_CCI_Demo og FactResellerSales_Page_Demo.
FactResellerSales_CCI_Demo har et grupperet kolonnelagerindeks, og FactResellerSales_Page_Demo har et grupperet b-træindeks med to kolonner og er sidekomprimeret. Som du kan se, indlæser hver tabel 1.024.000 rækker fra den FactResellerSalesXL_CCI tabel. Hvornår SET STATISTICS TIME er ON, holder SQL Server styr på den forløbne tid for udførelsen af forespørgslen. Indlæsning af dataene i tabellen columnstore tog ca. 8 sekunder, hvor indlæsning i den sidekomprimerede tabel tog næsten 20 sekunder. I dette eksempel indlæses alle de rækker, der går ind i columnstore-indekset, i en enkelt rækkegruppe.
Hvis du indlæser mindre end 102.400 rækker med data i et columnstore-indeks i en enkelt handling, indlæses den i en b-træstruktur, der kaldes et deltalager. Databaseprogrammet flytter disse data til columnstore-indekset ved hjælp af en asynkron proces, der kaldes tupel mover. Hvis du har åbne deltalagre, kan det påvirke ydeevnen af dine forespørgsler, fordi læsning af disse poster er mindre effektiv end læsning fra columnstore. Du kan også omorganisere indekset med muligheden COMPRESS_ALL_ROW_GROUPS for at tvinge deltalagrene til at blive tilføjet og komprimeret til kolonnelagerindekserne.