Identificer problematiske forespørgselsplaner
Den typiske fremgangsmåde, som DBAs anvender til fejlfinding af forespørgselsydeevnen, omfatter først at identificere den problematiske forespørgsel, som normalt er den, der bruger flest systemressourcer, og derefter hente dens udførelsesplan. Der er to primære scenarier. Et scenarie er, at forespørgslen konsekvent klarer sig dårligt. Dette kan skyldes forskellige problemer, f.eks. hardwareressourcebegrænsninger (selvom dette normalt ikke påvirker en enkelt forespørgsel, der kører isoleret), en ikke-optimal forespørgselsstruktur, indstillinger for databasekompatibilitet, manglende indekser eller forkerte planvalg fra forespørgselsoptimeringsprogrammet. Det andet scenarie er, at forespørgslen klarer sig godt i nogle udførelser, men dårligt i andre. Denne inkonsistens kan skyldes faktorer som dataforvridende i en parameteriseret forespørgsel, som har en effektiv plan for nogle udførelser og en dårlig for andre. Andre almindelige faktorer omfatter blokering, hvor en forespørgsel venter på, at en anden forespørgsel fuldføres for at få adgang til en tabel eller hardwarestrid.
Lad os udforske hvert af disse scenarier mere detaljeret.
Hardwarebegrænsninger
Hardwarebegrænsninger manifester typisk ikke under udførelse af enkelte forespørgsler, men bliver synlige under produktionsbelastning, når CPU-tråde og hukommelse er begrænset. CPU-strid kan registreres ved at observere ydelsesmålerens tæller '% Processortid', som måler serverens CPU-forbrug. I SQL Server kan SOS_SCHEDULER_YIELD - og CXPACKET-ventetidstyper indikere CPU-tryk. Dårlig ydeevne i lagringssystemet kan gøre selv optimerede udførelser af enkeltforespørgsler langsommere. Lagringsydeevne spores bedst på operativsystemniveau ved hjælp af ydelsesmålertællere Disk Seconds/Read og Disk Seconds/Write, som måler fuldførelsestider for I/O-handlinger. SQL Server logfører dårlig lagerydeevne, hvis en I/O tager mere end 15 sekunder. Høje PAGEIOLATCH_SH ventetider i SQL Server kan indikere problemer med lagringsydeevnen. Hardwareydeevne evalueres typisk tidligt i fejlfindingsprocessen på grund af dens lethed ved vurdering.
De fleste problemer med databasens ydeevne stammer fra ikke-optimale forespørgselsmønstre, hvilket kan lægge unødigt pres på hardwaren. Manglende indeks kan f.eks. medføre cpu-, lager- og hukommelsesforbrug ved at hente flere data end nødvendigt. Det anbefales at håndtere og justere ikke-optimale forespørgsler, før du løser hardwareproblemer. Derefter ser vi på justering af forespørgsler.
Ikke-optimale forespørgselskonstruktioner
Relationsdatabaser fungerer bedst, når der udføres sætbaserede handlinger, som manipulerer data (INSERT, UPDATE, DELETEog SELECT) i sæt, hvilket producerer enten en enkelt værdi eller et resultatsæt. Alternativet er rækkebaseret behandling ved hjælp af markører eller løkker, hvilket øger omkostningerne lineært med antallet af berørte rækker – en problematisk skalering, efterhånden som datamængderne vokser.
Det er vigtigt at registrere suboptimal brug af rækkebaserede handlinger med markører eller WHILE-løkker, men der er andre SQL Server-antimønstre at genkende. Tabelfunktioner (TVF'er), især tv'er med flere udsagn, forårsagede problematiske udførelsesplanmønstre før SQL Server 2017. Udviklere bruger ofte tv-filer med flere udsagn til at udføre flere forespørgsler i en enkelt funktion og samle resultater i en enkelt tabel. Brug af TVF'er kan dog medføre sanktioner for ydeevnen.
SQL Server har to typer tv'er: indbygget og multi-sætning. Indbyggede TVF'er behandles som visninger, mens tv'er med flere udsagn behandles som tabeller under behandling af forespørgsler. Da TVF'er er dynamiske og mangler statistikker, bruger SQL Server et fast rækkeantal til at anslå omkostninger til forespørgselsplan. Det kan være fint for små rækkeantal, men ineffektivt for tusindvis eller millioner af rækker.
Et andet antimønster er brugen af skalarfunktioner, som har lignende estimerings- og udførelsesproblemer. Microsoft har foretaget betydelige forbedringer af ydeevnen med Intelligent forespørgselsbehandling under kompatibilitetsniveauer 140 og 150.
SARGability
Udtrykket SARGable i relationsdatabaser refererer til et prædikat (WHERE -delsætning), der er formateret til at bruge et indeks til at fremskynde udførelse af forespørgsler. Prædikater i det korrekte format kaldes 'Søgeargumenter' eller SARG'er. I SQL Server betyder brugen af en SARG, at optimeringsfunktionen evaluerer ved hjælp af et ikke-grupperet indeks for den kolonne, der refereres til i SARG for en SEEK-handling , i stedet for at scanne hele indekset eller tabellen for at hente en værdi.
Tilstedeværelsen af en SARG garanterer ikke brugen af et indeks til en SEEK. Optimeringsalgoritmerne for omkostningsberegning kan stadig fastslå, at indekset er for dyrt, især hvis en SARG refererer til en stor procentdel af rækker i en tabel. Fraværet af en SARG betyder, at optimeringsprogrammet ikke evaluerer en SEEK på et ikke-rodet indeks.
Eksempler på ikke-SARGable-udtryk omfatter udtryk med en LIKE delsætning, der bruger et jokertegn i starten af strengen, f.eks WHERE lastName LIKE '%SMITH%'. . Der forekommer andre prædikater, der ikke er SARGable, når du bruger funktioner i en kolonne, f.eks WHERE CONVERT(CHAR(10), CreateDate,121) = '2020-03-22'. . Disse forespørgsler identificeres typisk ved at undersøge udførelsesplaner for indeks- eller tabelscanninger, hvor søgninger ellers skulle finde sted.
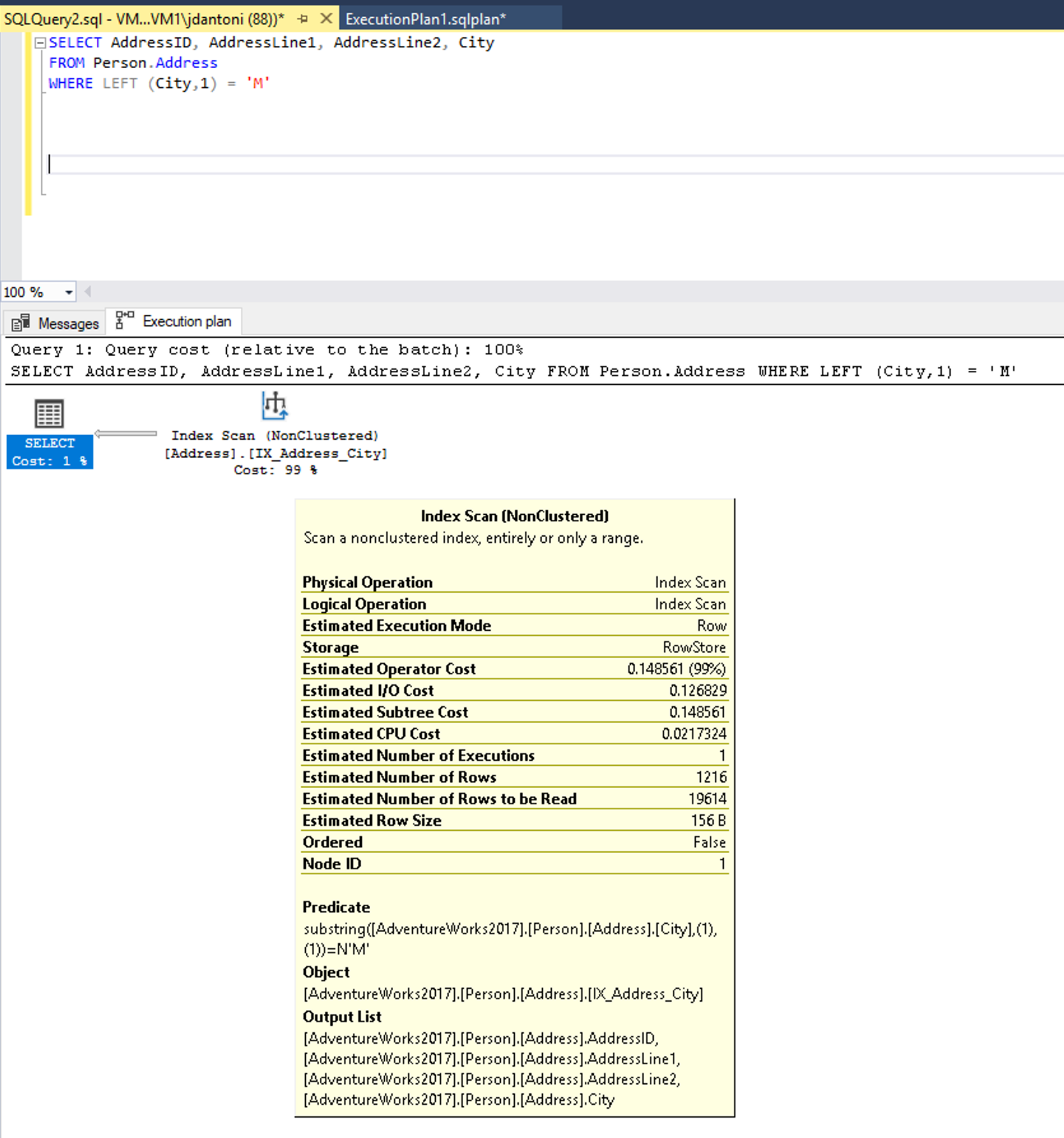
Der er et indeks i kolonnen By , der bruges i WHERE forespørgslens delsætning, og mens det bruges i denne udførelsesplan ovenfor, kan du se, at indekset scannes, hvilket betyder, at hele indekset læses. Funktionen LEFT i prædikatet gør dette udtryk ikke-SARGable. Optimeringsværktøjet evaluerer ikke ved hjælp af en indekssøgning på indekset i kolonnen By .
Denne forespørgsel kan skrives til at bruge et prædikat, der er SARGable. Optimeringsværktøjet vil derefter evaluere en SEEK på indekset i kolonnen By . En operator til indekssøgning ville i dette tilfælde læse et mindre sæt rækker.
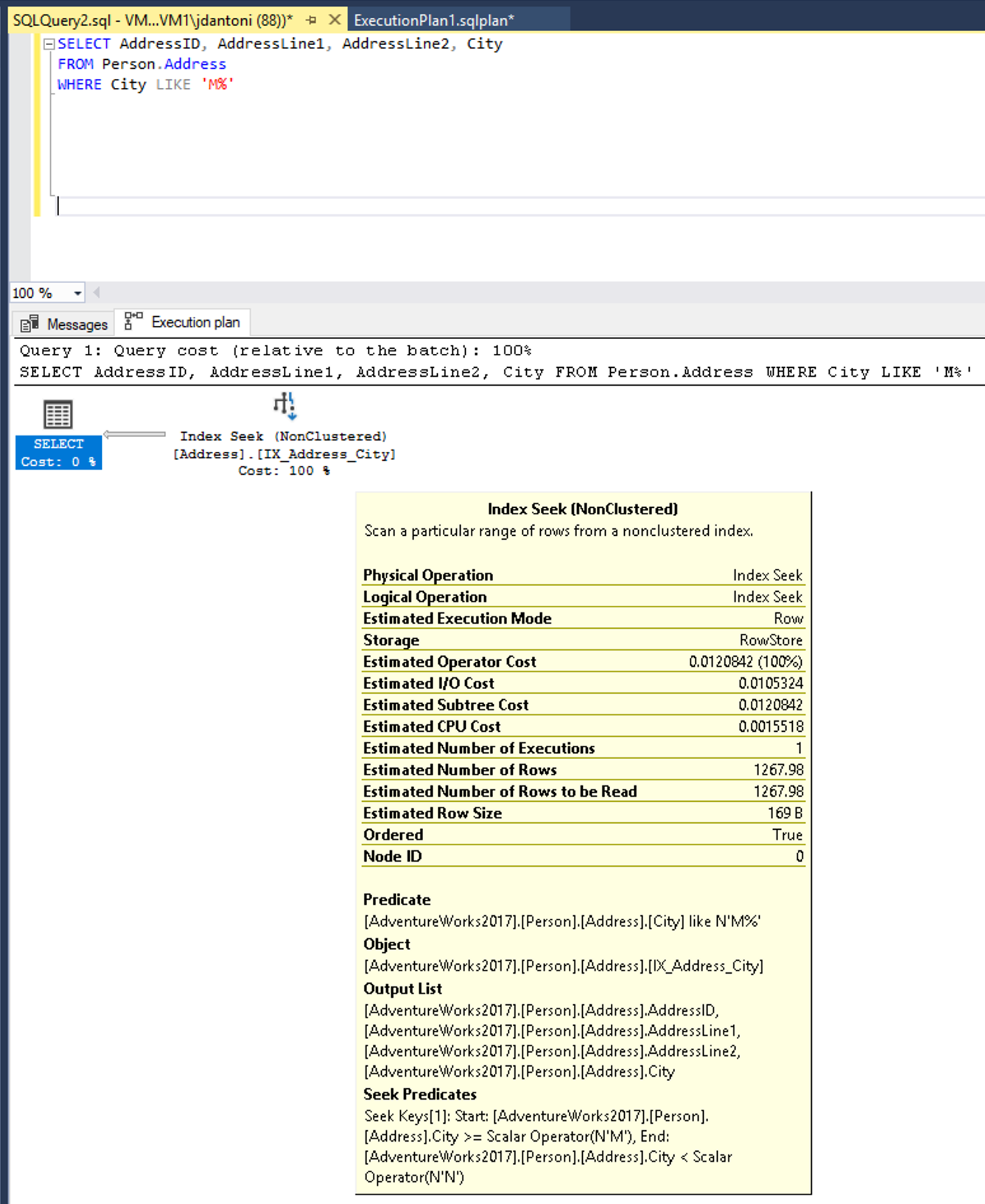
Ændring af LEFT funktion til en LIKE resulterer i en indekssøgning.
Bemærk
Nøgleordet LIKE i dette eksempel har ikke et jokertegn til venstre, så det er på udkig efter byer, der starter med M. Hvis det var "tosidet" eller startet med et jokertegn ('%M%' eller '%M'), ville det være ikke-SARGable. Søgehandlingen anslås at returnere 1.267 rækker eller ca. 15% af estimatet for forespørgslen med prædikatet ikke-SARGable.
Nogle andre antimønstre til databaseudvikling behandler databasen som en tjeneste i stedet for et datalager. Brug af en database til at konvertere data til JSON, manipulere strenge eller udføre komplekse beregninger kan føre til overdreven CPU-brug og øget ventetid. Forespørgsler, der forsøger at hente alle poster og derefter udføre beregninger i databasen, kan føre til overdreven IO- og CPU-forbrug. Ideelt set bør du bruge databasen til dataadgangshandlinger og optimerede databasekonstruktioner, f.eks. sammenlægning.
Manglende indekser
De mest almindelige problemer med ydeevnen for databaseadministratorer skyldes manglen på nyttige indeks, hvilket får programmet til at læse flere sider, end det er nødvendigt for at returnere forespørgselsresultater. Mens indeks forbruger ressourcer (der påvirker skriveydeevnen og optager plads), opvejer deres ydeevnegevinster ofte de ekstra ressourceomkostninger. Udførelsesplaner med disse problemer kan identificeres af forespørgselsoperatoren Clustered Index Scan eller kombinationen af Ikke-grupperet indekssøgning og nøgleopslag, hvilket angiver manglende kolonner i et eksisterende indeks.
Databaseprogrammet hjælper ved at rapportere manglende indekser i udførelsesplaner. Navnene på og detaljerne for de anbefalede indeks er tilgængelige via den dynamiske administrationsvisning sys.dm_db_missing_index_details. Andre DMV'er synes godt om sys.dm_db_index_usage_stats og sys.dm_db_index_operational_stats fremhæver udnyttelsen af eksisterende indeks.
Det kan være fornuftigt at droppe et ubrugt indeks. Manglende indeks-DMV'er og planadvarsler skal være startpunkter for justering af forespørgsler. Det er afgørende at forstå vigtige forespørgsler og oprette indekser for at understøtte dem. Det anbefales ikke at oprette alle manglende indeks uden at evaluere dem i kontekst.
Manglende og forældede statistikker
Det er afgørende at forstå vigtigheden af kolonne- og indeksstatistik til forespørgselsoptimering. Det er også vigtigt at genkende betingelser, der kan føre til forældede statistikker, og hvordan dette problem kan manifestere sig i SQL Server. Azure SQL tilbyder som standard, at statistikker for automatiske opdateringer er slået til. Før SQL Server 2016 var standardfunktionsmåden for statistikker for automatiske opdateringer ikke at opdatere statistikker, før antallet af ændringer af kolonner i indekset svarede til ca. 20% af antallet af rækker i en tabel. Denne funktionsmåde kan resultere i betydelige dataændringer, der ændrer forespørgselsydeevnen uden at opdatere statistikkerne, hvilket fører til ikke-optimale planer baseret på forældede statistikker.
Før SQL Server 2016 kunne sporingsflag 2371 bruges til at ændre det påkrævede antal ændringer til en dynamisk værdi, så i takt med at tabellen voksede, faldt den procentdel af rækkeændringer, der var nødvendige for at udløse en statistikopdatering. Nyere versioner af SQL Server, Azure SQL Database og Azure SQL Managed Instance understøtter som standard denne funktionsmåde. Den dynamiske administrationsfunktion sys.dm_db_stats_properties viser, hvornår statistikkerne sidst blev opdateret, og antallet af ændringer siden sidste opdatering, så du hurtigt kan identificere statistikker, der kan kræve manuelle opdateringer.
Dårlige optimeringsmuligheder
Selvom forespørgselsoptimering gør et godt stykke arbejde med at optimere de fleste forespørgsler, er der nogle edge-tilfælde, hvor den omkostningsbaserede optimering kan træffe virkningsfulde beslutninger, der ikke forstås fuldt ud. Der er mange måder at håndtere dette på, herunder ved hjælp af forespørgselstip, sporingsflag, gennemtvingelse af udførelsesplan og andre justeringer for at nå frem til en stabil og optimal forespørgselsplan. Microsoft har et supportteam, der kan hjælpe med fejlfinding af disse scenarier.
I nedenstående eksempel fra AdventureWorks2017-databasen bruges et forespørgselstip til at fortælle databaseoptimeringsværktøjet, at det altid skal bruge et bynavn i Seattle. Dette tip garanterer ikke den bedste udførelsesplan for alle byværdier, men det er forudsigeligt. Værdien af 'Seattle' for @city_name vil kun blive brugt under optimering. Under udførelsen bruges den faktiske angivne værdi (‘Ascheim’) .
DECLARE @city_name nvarchar(30) = 'Ascheim',
@postal_code nvarchar(15) = 86171;
SELECT *
FROM Person.Address
WHERE City = @city_name
AND PostalCode = @postal_code
OPTION (OPTIMIZE FOR (@city_name = 'Seattle');
Som det ses i eksemplet, bruger forespørgslen et tip (#D0-delsætningen) til at bede optimeringsprogrammet om at bruge en bestemt variabelværdi til at oprette udførelsesplanen.
Parametersnøftning
SQL Server cachelagrer planer for udførelse af forespørgsler til fremtidig brug. Da hentningsprocessen for udførelsesplanen er baseret på hashværdien for en forespørgsel, skal forespørgselsteksten være identisk for hver udførelse af forespørgslen for den cachelagrede plan, der skal bruges. For at understøtte flere værdier i den samme forespørgsel bruger mange udviklere parametre, der overføres via lagrede procedurer, som vist i følgende eksempel:
CREATE PROC GetAccountID (@Param INT)
AS
<other statements in procedure>
SELECT accountid FROM CustomerSales WHERE sales > @Param;
<other statements in procedure>
RETURN;
-- Call the procedure:
EXEC GetAccountID 42;
Forespørgsler kan også eksplicit parameteriseres ved hjælp af proceduren sp_executesql. Eksplicit parameterisering af individuelle forespørgsler udføres dog via programmet med en formular (afhængigt af API'en) af PREPARE og EXECUTE. Når databaseprogrammet udfører denne forespørgsel for første gang, optimeres forespørgslen baseret på parameterens startværdi, i dette tilfælde 42. Denne funktionsmåde, der kaldes parametersnifning, gør det muligt at reducere den overordnede arbejdsbelastning for kompilering af forespørgsler på serveren. Men hvis der er dataforvrid, kan ydeevnen af forespørgsler variere meget.
En tabel, der f.eks. havde 10 millioner poster, og 99% af disse poster har et id på 1, og de andre 1% er entydige tal, ydeevnen er baseret på, hvilket id der oprindeligt blev brugt til at optimere forespørgslen. Denne vildt svingende ydeevne er tegn på dataforvrængelse og er ikke et indbygget problem med parametersnifning. Denne funktionsmåde er et ret almindeligt problem med ydeevnen, som du skal være opmærksom på. Du bør forstå mulighederne for at afhjælpe problemet. Der er et par måder at løse dette problem, men de hver især kommer med kompromiser:
- Brug tippet
RECOMPILEi forespørgslen eller udførelsesindstillingenWITH RECOMPILEi dine lagrede procedurer. Dette tip medfører, at forespørgslen eller proceduren genkompileres, hver gang den udføres, hvilket øger CPU-forbruget på serveren, men altid bruger den aktuelle parameterværdi. - Du kan bruge forespørgselstippet
OPTIMIZE FOR UNKNOWN. Dette tip får optimeringsprogrammet til at vælge ikke at snuse parametre og sammenligne værdien med kolonnedata histogrammet. Denne indstilling giver dig ikke den bedst mulige plan, men giver dig mulighed for en konsekvent udførelsesplan. - Omskriv din procedure eller dine forespørgsler ved at føje logik omkring parameterværdier til kun RECOMPILE for kendte problematiske parametre. Hvis parameteren SalesPersonID er NULL i eksemplet nedenfor, udføres forespørgslen med
OPTION (RECOMPILE).
CREATE OR ALTER PROCEDURE GetSalesInfo (@SalesPersonID INT = NULL)
AS
DECLARE @Recompile BIT = 0
, @SQLString NVARCHAR(500)
SELECT @SQLString = N'SELECT SalesOrderId, OrderDate FROM Sales.SalesOrderHeader WHERE SalesPersonID = @SalesPersonID'
IF @SalesPersonID IS NULL
BEGIN
SET @Recompile = 1
END
IF @Recompile = 1
BEGIN
SET @SQLString = @SQLString + N' OPTION(RECOMPILE)'
END
EXEC sp_executesql @SQLString
,N'@SalesPersonID INT'
,@SalesPersonID = @SalesPersonID
GO
Dette eksempel er en god løsning, men det kræver en temmelig stor udviklingsindsats og en solid forståelse af din datadistribution. Det kræver vedligeholdelse, efterhånden som dataene ændres.