Modeller til maskinel indlæring
Notat
Se fanen Tekst og billeder for flere detaljer!
Da maskinel indlæring er baseret på matematik og statistik, er det almindeligt at tænke på modeller til maskinel indlæring i matematiske vendinger. Grundlæggende er en model til maskinel indlæring et softwareprogram, der indkapsler en funktion til at beregne en outputværdi baseret på en eller flere inputværdier. Processen med at definere denne funktion kaldes oplæring. Når funktionen er defineret, kan du bruge den til at forudsige nye værdier i en proces, der kaldes inferencing.
Lad os se nærmere på de trin, der er involveret i oplæring og udledning.
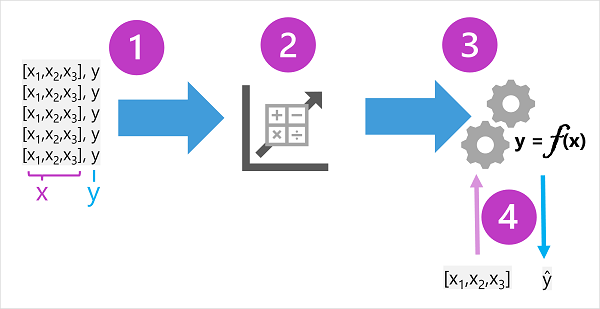
Træningsdataene består af tidligere observationer. I de fleste tilfælde omfatter observationerne de observerede attributter eller funktioner for de ting, der observeres, og den kendte værdi af det, du vil oplære en model til at forudsige (kendt som mærkaten).
I matematiske termer kan du ofte se de funktioner, der refereres til, ved hjælp af det korte variabelnavn x og den mærkat, der kaldes y. Normalt består en observation af flere funktionsværdier, så x er faktisk en vektor (en matrix med flere værdier) som denne: [x1,x2,x3,...].
Lad os se nærmere på de eksempler, der er beskrevet tidligere, for at gøre dette tydeligere:
- I scenariet med salg af is er vores mål at oplære en model, der kan forudsige antallet af issalg baseret på vejret. Vejrmålingerne for dagen (temperatur, nedbør, vindhastighed osv.) ville være funktionerne (x), og antallet af is, der sælges på hver dag, ville være mærkaten (y).
- I det medicinske scenarie er målet at forudsige, om en patient er i risiko for diabetes baseret på deres kliniske målinger eller ej. Patientens målinger (vægt, glukoseniveau osv.) er egenskaberne (x), og sandsynligheden for diabetes (f.eks . 1 for risiko, 0 for ikke-risiko) er etiketten (y).
- I det antarktiske forskningsscenarie ønsker vi at forudsige arten af en pingvin baseret på dens fysiske egenskaber. De vigtigste målinger af pingvinen (længden af dens svømmefødder, bredden af dens regning osv.) er funktionerne (x), og arten (for eksempel 0 for Adelie, 1 for Gentoo eller 2 for Chinstrap) er etiketten (y).
Der anvendes en algoritme på dataene for at forsøge at bestemme en relation mellem funktionerne og etiketten og generalisere relationen som en beregning, der kan udføres på x for at beregne y. Den specifikke algoritme, der bruges, afhænger af den type forudsigende problem, du forsøger at løse (mere om dette senere), men det grundlæggende princip er at forsøge at tilpasse dataene til en funktion, hvor værdierne i funktionerne kan bruges til at beregne mærkaten.
Resultatet af algoritmen er en model , der indkapsler den beregning, der er afledt af algoritmen som en funktion – lad os kalde den f. I matematisk notation:
y = f(x)
Nu, hvor oplæringsfasen er fuldført, kan den oplærte model bruges til at udlede. Modellen er i bund og grund et softwareprogram, der indkapsler den funktion, der produceres af uddannelsesprocessen. Du kan angive et sæt funktionsværdier og som output modtage en forudsigelse af det tilsvarende navn. Da outputtet fra modellen er en forudsigelse, der blev beregnet af funktionen og ikke en observeret værdi, kan du ofte se outputtet fra funktionen vist som ŷ (som er ret dejligt verbaliseret som "y-hat").