Forstå datalagre
Et data warehouse er en centraliseret, struktureret butik designet til analytiske forespørgsler og rapportering. I modsætning til operationelle databaser, der håndterer daglige forretningstransaktioner, konsoliderer et data warehouse data fra flere kilder i et format optimeret til analyse.
Opbygning af et moderne data warehouse indebærer typisk:
- Dataindlæsning - Overførsel af data fra kildesystemerne til lageret.
- Data storage - Lagring af data i et format optimeret til analyse.
- Databehandling - Omdanner data til et format, der er klar til forbrug med analytiske værktøjer.
- Dataanalyse og levering – Analyse af data for at opnå indsigt og levere dem til virksomheden.
Design et data warehouse
Data warehouses indeholder tabeller organiseret i et skema optimeret til multidimensionel modellering. I denne tilgang grupperer du numeriske data relateret til begivenheder efter forskellige attributter. Du kan f.eks. analysere det samlede beløb, der er betalt for salgsordrer, der er indtruffet på en bestemt dato eller i en bestemt butik.
Tabeller i et data warehouse
Du organiserer data warehouse-tabeller for at understøtte effektiv analyse af store datamængder. Denne organisering, kendt som dimensionsmodellering, indebærer at strukturere tabeller til faktatabeller og dimensionstabeller.
Faktatabeller indeholder de numeriske data, du ønsker at analysere. Faktatabeller har typisk et stort antal rækker og er den primære datakilde til analyse. En faktatabel kan f.eks. indeholde det samlede beløb, der er betalt for salgsordrer, der indtraf på en bestemt dato eller i en bestemt butik.
Dimensionstabeller indeholder beskrivende information om dataene i faktatabellerne. Dimensionstabeller har typisk nogle få rækker og giver kontekst til dataene i faktatabellerne. En dimensionstabel kan f.eks. indeholde oplysninger om de kunder, der har afgivet salgsordrer.
Ud over attributkolonner indeholder en dimensionstabel en entydig nøglekolonne, der entydigt identificerer hver række i tabellen. Det er faktisk almindeligt, at en dimensionstabel indeholder to nøglekolonner:
- En surrogatnøgle er en unik identifikator for hver række i dimensionstabellen. Det er ofte en heltalsværdi, som databaseadministrationssystemet automatisk genererer, når du indsætter en ny række.
- En alternativ nøgle er ofte en naturlig eller forretningsnøgle, der identificerer en specifik instans af en enhed i det transaktionelle kildesystem – såsom en produktkode eller et kunde-ID.
Du har brug for både surrogat- og alternative nøgler i et data warehouse, fordi de tjener forskellige formål. Surrogatnøgler er specifikke for data warehouse og hjælper med at opretholde konsistens og nøjagtighed. Alternative nøgler er specifikke for kildesystemet og hjælper med at opretholde sporbarhed mellem data warehouse og kildesystemet.
Særlige typer dimensionstabeller
Særlige dimensionstyper giver yderligere kontekst og muliggør mere omfattende dataanalyser.
Tidsdimensioner giver information om den tidsperiode, hvor en begivenhed fandt sted. Denne tabel gør det muligt for dataanalytikere at aggregere data over tidsmæssige intervaller. For eksempel kan en tidsdimension inkludere kolonner for år, kvartal, måned og dag for en salgsordre.
Langsomt skiftende dimensioner følger ændringer i dimensionsattributter over tid, såsom ændringer i en kundes adresse eller et produkts pris. De er vigtige i et data warehouse, fordi de gør det muligt at analysere og forstå ændringer i data over tid. Langsomt skiftende dimensioner sikrer, at data forbliver up-toopdaterede og nøjagtige, hvilket er vigtigt for at træffe gode forretningsbeslutninger.
Data warehouse-skemadesign
I de fleste transaktionsdatabaser, der bruges i forretningsapplikationer, normaliseres dataene for at reducere duplikation. I et data warehouse denormaliseres dimensionsdataene dog for at reducere antallet af joins, der kræves for at forespørge dataene.
Ofte bruger en data warehouse et stjerneskema, hvor en faktatabel relaterer direkte til dimensionstabellerne, som vist i dette eksempel:
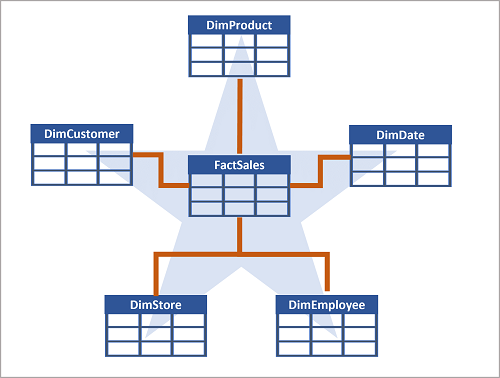
Du kan bruge dimensionsattributter til at gruppere faktatabellens numre på forskellige niveauer. Du kan f.eks. finde den samlede salgsindtægt for et helt område eller kun for én kunde. Du kan gemme informationen for hvert niveau i samme dimensionstabel.
Drikkepenge
Se Hvad er et stjerneskema? for mere information om design af stjerneskemaer til stof.
Hvis der er mange niveauer eller attributter, der deles af forskellige ting, kan det give mening at bruge et snowflake-skema i stedet. Her er et eksempel:
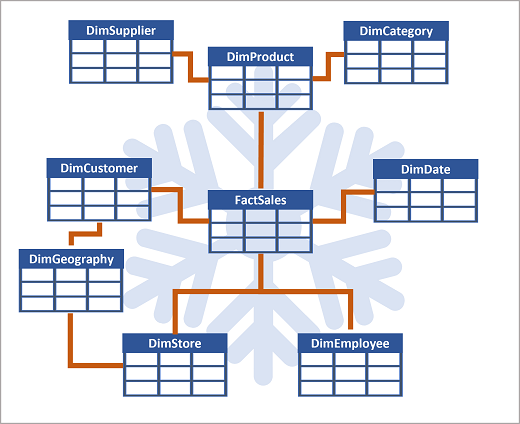
I dette tilfælde opdeles (normaliseres) DimProduct-tabellen i separate dimensionstabeller for produktkategorier og leverandører.
- Hver række i DimProduct-tabellen indeholder nøgleværdier for de tilsvarende rækker i DimCategory - og DimSupplier-tabellerne.
En DimGeography-tabel indeholder information om, hvor kunder og butikker befinder sig.
- Hver række i DimCustomer- og DimStore-tabellerne indeholder en nøgleværdi for den tilsvarende række i DimGeography-tabellen .