Implementer strækklynger
Failoverklynger har traditionelt givet beskyttelse med høj tilgængelighed mod lokaliserede fejl til en eller flere klyngenoder, der er placeret på den samme fysiske placering. Du kan bruge strækklynger, når det er nødvendigt for at levere den tilsvarende funktionalitet på tværs af flere fysiske placeringer.
Hvad er strækklynger?
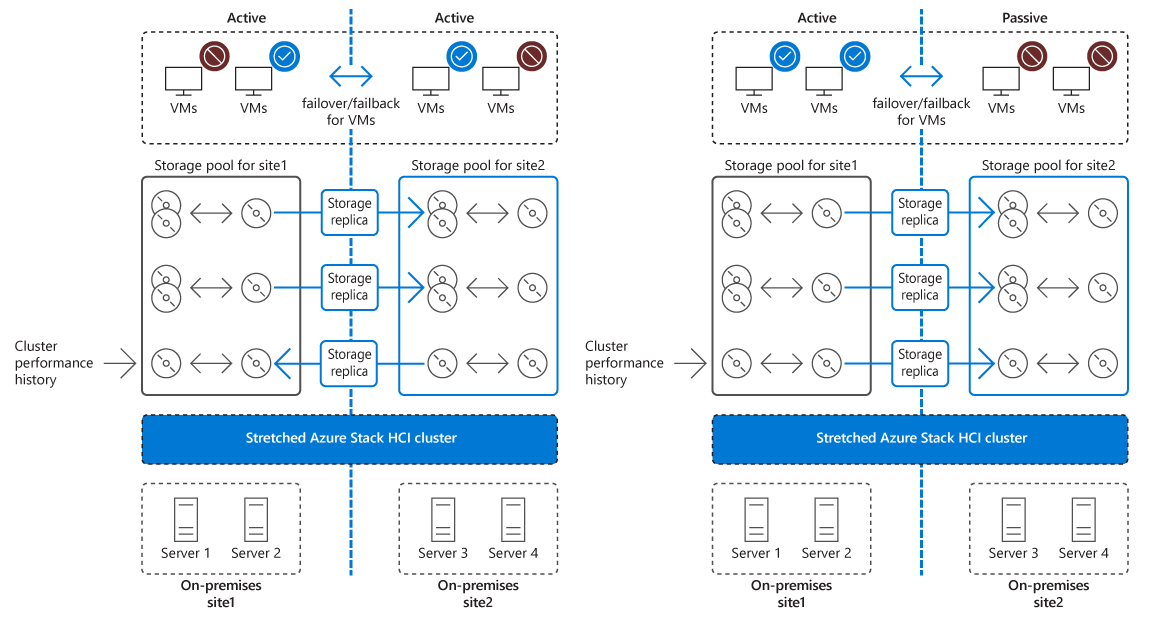
En strækklynge implementerer høj tilgængelighed og it-katastrofeberedskab på tværs af to separate fysiske placeringer. Begge placeringer er vært for et separat lagersystem med envejssynkron replikering fra det primære websted til det sekundære websted. Hvis en fejl påvirker tilgængeligheden af det primære websted for at minimere nedetid, skifter klyngen automatisk arbejdsbelastningerne til noder på det sekundære websted. I forbindelse med planlagte vedligeholdelseshændelser på det primære websted kan du bruge Hyper-V Live Migration til problemfrit at overføre arbejdsbelastninger til det andet websted, hvilket helt undgår nedetid.
Brug af strækklynger giver flere fordele i forhold til manuel vedligeholdelse af et it-katastrofeberedskabswebsted:
- Automatisk replikering og automatisk failover af grupperede arbejdsbelastninger.
- Reducer administrative omkostninger.
- Minimer muligheden for menneskelige fejl, som er indbygget i manuelle processer.
På den anden side er strækklynger mere komplekse at designe og implementere. De kræver typisk også en yderligere investering i lager- og netværksinfrastruktur.
Oversigt over lagerreplika
Stretch clusters udnytter Storage Replica, en Windows Server-funktion, der leverer replikering af diskenheder mellem servere eller klynger til it-katastrofeberedskab. Ved hjælp af Lagerreplika kan strækklynger synkronisere lagermængder, der er knyttet til strækklyngnoder på to separate placeringer.
Lagerreplika understøtter synkron og asynkron replikering:
- Synkron replikering replikerer data via et netværk med lav ventetid inden for millisekunder af returtid, så der ikke mistes data på filsystemets niveau under en failover.
- Asynkron replikering replikerer data over længere afstande, der er underlagt højere ventetider, men uden en garanti for, at begge websteder har identiske kopier af dataene på tidspunktet for en failover.
Vigtig
Strækklynger kræver synkron replikering. Dette krav pålægger grænsen på 5 ms ventetid for rundturnetværk mellem to grupper klyngenoder på de replikerede websteder. Afhængigt af de fysiske netværksforbindelsesegenskaber oversætter denne begrænsning typisk til en afstand på ca. 20-30 miles.
Funktioner til lagringsreplika
Hovedfunktionerne i Lagerreplika er angivet i følgende tabel.
| Funktion | Beskrivelse |
|---|---|
| Replikering på blokniveau | Med replikering på blokniveau er der ingen mulighed for fillåsning. |
| Enkelhed | Du kan stole på, at Windows Administration guider dig gennem processen med at oprette et replikeringspartnerskab mellem to servere. Hvis du vil udrulle en strækklynge, kan du bruge en guide, der er baseret på Failover Cluster Manager. |
| Brug af SMB (Server Message Block) 3.0 | Lagerreplikaen er afhængig af SMB 3.x, der blev introduceret i Windows Server 2012 og markant forbedret i efterfølgende versioner af Windows Server. Alle SMB's avancerede egenskaber, f.eks. SMB Multichannel og SMB Direct, er tilgængelige for Lagerreplika. |
| Sikkerhed | Lagerreplika indeholder en lang række sikkerhedsmekanismer, herunder pakkesignering, fuld datakryptering i AES-128-GCM, understøttelse af krypteringsacceleration fra tredjepart og forebyggelse af integritet inden godkendelse i midten. Lagerreplika er også afhængig af Kerberos AES256 for al godkendelse mellem noder. |
| Netværksbegrænsninger | I tilfælde, hvor der er flere netværksstier mellem replikerede diskenheder, kan du konfigurere Lagerreplikatrafik til at bruge angivne netværkskort. Dette giver dig mulighed for at minimere replikeringstrafikkens potentielle indvirkning på produktionsarbejdsbelastninger. |
| Tynd klargøring | Du har mulighed for at implementere tynd klargøring i Storage Spaces Direct, hvilket minimerer de indledende replikeringstider. |
Forudsætninger for udrulning af strækklynger
Forudsætningerne for implementering af strakt klynger omfatter:
Klyngenoder skal være medlemmer af det samme AD DS-område, der er tillid til.
Hver klyngenode skal have mindst 2 GB RAM og to CPU-kerner pr. server.
Hver klyngenode skal køre Windows Server 2025 Datacenter eller Windows Server 2016 Datacenter edition. Det er muligt at bruge Windows Server 2025 Standard Edition, men en sådan konfiguration understøtter kun replikering af en enkelt diskenhed på op til 2 terabyte (TB).
Hver klyngenode skal have mindst 1 Gigabit Ethernet-adapter til synkron replikering, selvom RDMA (Remote Direct Memory Access) er at foretrække.
To sæt diskenheder (ét for data og et andet for logge) på det primære og det sekundære websted med følgende indstillinger:
Diskene skal initialiseres som GPT (GUID Partition Table) i stedet for MBR (Master Boot Record).
- Diskenheder skal formateres med ReFS eller NTFS.
- Størrelsen på datamængderne og sektorstørrelserne skal stemme overens.
- Størrelsen på logmængderne og sektorstørrelserne skal stemme overens.
- Logenhederne skal bruge hurtigere lager end datamængder.
- Logmængderne bør ikke bruges til andre arbejdsbelastninger.
Tovejsforbindelse via ICMP (Internet Control Message Protocol), SMB (port 445 plus port 5445 til SMB Direct) og Web Services-Management (WS-MAN) (port 5985) mellem de to websteder.
Et netværk mellem servere med tilstrækkelig båndbredde til at matche I/O-skrivninger af de grupperede arbejdsbelastninger og mindre end 5 ms ventetid for rundtur.
Overvejelser i forbindelse med udrulning af en strækklynge
Strækklynger er ikke egnede til hver arbejdsbelastning og hvert scenarie. Når du designer en strækklyngløsning, skal du tydeligt identificere organisationens krav og forventninger. Derudover skal du huske på, at strækklynger medfører flere administrationsomkostninger end traditionelle klynger, hvor alle noder er placeret på den samme fysiske placering. Du bør også nøje overveje det optimale valg af quorum vidnet for at maksimere dets tilgængelighed i tilfælde af en katastrofe, der påvirker et helt fysisk websted.
Vigtig
Stateful-programmer og -tjenester, f.eks. Microsoft SQL Server, Hyper-V, Microsoft Exchange Server og AD DS, bør bruge deres egne oprindelige robusthedsmekanismer i stedet for at være afhængige af strækklynger for at opnå høj tilgængelighed.
Overvejelser i forbindelse med failover og failback i en strækklynge
Som en del af planlægningen af udrulningen af en stretchklynge skal du definere dens failover- og failbackkonfiguration under hensyntagen til følgende overvejelser:
- Infrastrukturafhængigheder. Du skal klart definere de vigtige tjenester, f.eks. AD DS, DNS og DHCP, som skal forblive tilgængelige efter en failover til det sekundære websted.
- Quorum-model. Det er vigtigt at vælge den quorum-model, der bevarer klyngefunktionaliteten efter en failover.
- Publicering af tjenester og navnefortsættelse. Hvis du har tjenester, der er publiceret til dine interne eller eksterne brugere, f.eks. mail og websider, skal du være opmærksom på, at failover til et andet websted i nogle tilfælde kræver ændringer af navn eller IP-adresse. Hvis det er tilfældet, skal du have en procedure for ændring af DNS-poster i den interne eller offentlige DNS. Hvis du vil reducere nedetiden, anbefaler vi, at du reducerer TTL-værdien (Time to Live) for kritiske DNS-poster.
- Klientforbindelse. I tilfælde af en katastrofe skal en failoverplan imødekomme forbindelse fra klientprogrammer til grupperede arbejdsbelastninger. Dette omfatter både interne og eksterne klienter.
- Failback-proceduren. Du skal planlægge og implementere en failbackproces, der skal udføres, når det primære websted er online igen. Failback er lige så vigtig som en failover, fordi hvis du udfører den forkert, kan du forårsage datatab og nedetid for tjenesten.
Opret en strækklynge
Du kan oprette en strækklynge ved hjælp af Windows Administration, Failover Cluster Manager eller Windows PowerShell. Windows Administration forenkler implementeringen af strækklynger ved at guide dig gennem klargøringsprocessen og automatisere de fleste konfigurationsopgaver. Dette omfatter understøttelse af:
- Hyperkonvergede klynger (Failover Clustering, Hyper-V og Storage Spaces Direct).
- Lagerklynger (Failover Clustering og Storage Spaces Direct).
Seddel
Det er mere komplekst at oprette en strækklynge ved hjælp af Failover Cluster Manager eller Windows PowerShell. Begge metoder kræver, at du udfører hvert af de mellemliggende implementeringstrin. I de enkleste ord starter dette med at oprette en traditionel, ikke-strakt failoverklynge, der består af alle noder på det primære og sekundære websted. Når du har oprettet klyngen og fuldført valideringen af den, opretter du et separat sæt lagermængder på hvert websted. Endelig skal du konfigurere Lagerreplika til at replikere lagermængder mellem de to websteder.