Gør programmer skalerbare
- 8 minutter
Nu, hvor du forstår det grundlæggende i at forberede dig på vækst og er opmærksom på faktorer, du skal overveje i kapacitetsplanlægningen, kan du tage udfordringen op med at gøre dine programmer så skalerbare som muligt.
Arkitektoniske anmeldelser
Et vigtigt punkt at huske er, at du skal udføre regelmæssige arkitektoniske anmeldelser af dine systemer.
Du ved, at du kan anvende fremgangsmåder som f.eks. infrastruktur som kode for at forbedre den måde, du udruller dine cloudressourcer på. Du opdaterer og forbedrer din programkode regelmæssigt, og du bør gøre det samme med dine underliggende platformressourcer.
Når du udfører en arkitektonisk gennemgang, kan du identificere de områder, der skal forbedres.
Azure Architecture Center har et væld af ressourcer til at hjælpe dig med at arkitektere dine applikationer i skyen, og der er mange skalerbarhedsanbefalinger, du kan finde i applikationsarkitekturguiden på følgende link:
Scenarie: Tailwind Traders-arkitektur
Et første skridt er at foretage en evaluering af arkitekturen og applikationen – ikke kun for at bestemme, hvor dens svagheder ligger, men også for at genkende dens styrker. Hvad er godt ved det?
Tag endnu et kig på det scenarie, du så i det forrige undermodul. Her er et diagram over organisationens arkitektur igen.
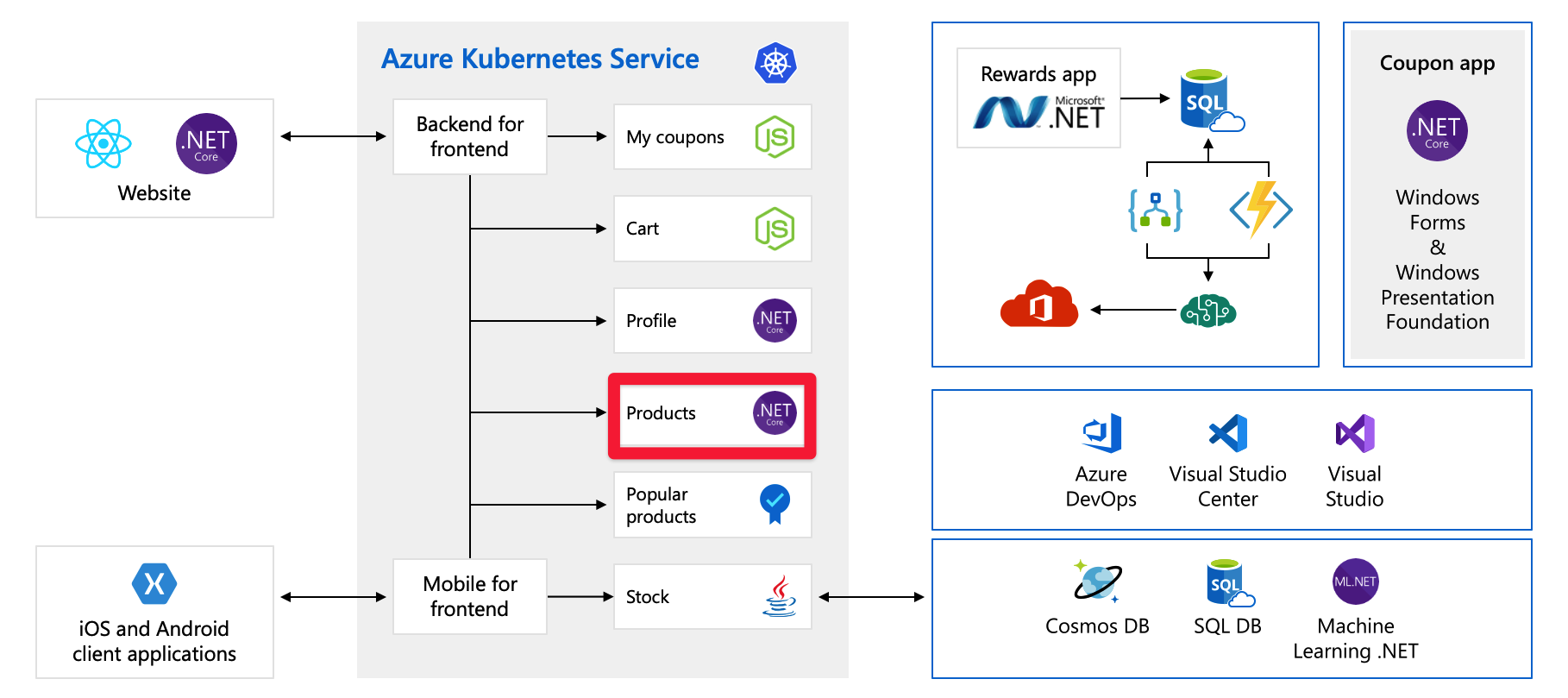
De har opdelt applikationen i mindre mikroservices, og nogle af disse services sidder som containere på Azure Kubernetes Service eller kan køre på VM'er eller App Service. De bruger også nogle iboende skalerbare tjenester som Functions og Logic Apps.
Denne ændring er god, men der er nogle forbedringer, der gør programmet mere skalerbart. Fokuser f.eks. nu på tjenesten Products. I diagrammet kører produktservicen i Kubernetes, men vi antager for denne forklaring, at den kører på en VM i Azure. Skaleringskoncepterne, muligvis med en lidt anden implementering, kan anvendes på programmer, uanset om de kører på servere, App Service eller i objektbeholdere.
Produktet kører i øjeblikket på en enkelt VM, forbundet til en enkelt Azure SQL-database. Du skal aktivere denne VM for at skalere ud. Du kan gøre dette ved hjælp af Azure virtual machine scale sets, som lader dig oprette og administrere en gruppe identiske, load balancerede VM'er. Da du nu har mere end én VM, skal du introducere en belastningsjustering for at distribuere trafik på tværs af VM'erne.
Skaleringssæt til virtuelle maskiner
Ved at anvende skaleringssæt for virtuelle maskiner via enkelt-VM'er får du et par fordele:
- Du kan automatisk skalere baseret på værtsmetrik, målepunkter i gæsten, programindsigt eller efter en tidsplan.
- Du kan bruge Tilgængelighedszoner (AZ), som er fysisk separate lokationer inden for en Azure-region, hver bestående af et eller flere datacentre. Med AZ-support kan du sprede dine VM'er over flere AZ'er, hvilket gør din applikation mere pålidelig og beskytter den mod datacenterfejl. Nye forekomster i et skaleringssæt fordeles automatisk jævnt på tværs af AZ'er.
- Det bliver nemmere at tilføje en justering af belastning. Virtual Machine scale sets understøtter brugen af Azure Load Balancer til grundlæggende Layer 4-trafikfordeling. De understøtter også Azure Application Gateway til mere avanceret L7-trafikdistribution og SSL-terminering.
Der er nogle vigtige faktorer, du skal overveje, før du implementerer skalasæt. Nemlig:
- Undgå forekomst stickiness, så ingen klient sidder fast til en bestemt back end.
- Fjern vedvarende data fra VM'en, og gem dem et andet sted, f.eks. i Azure Storage eller i en database.
- Design til scale-in. Det er også vigtigt, at dit program nemt kan skaleres ned igen. Det skal yndefuldt håndtere ikke kun at have flere forekomster føjet til puljen af servere, der håndterer trafikken, men også den bratte afslutning af forekomster, når belastningen falder. Skaleringsaspektet med nedskalering overses ofte.
Afkobling
Du har tilføjet flere VM'er med skaleringssæt. Udskalering er det typiske svar på "vi er nødt til at skalere". Men du kan kun skalere på en enkelt metrikværdi, og dette svar er muligvis ikke relevant for alle opgaver, der udføres af din produkttjeneste.
I vores scenarie har produktservicen en opgave: når et produktbillede uploades, transkoder den billedet og gemmer det i flere forskellige størrelser til miniaturebilleder, billeder i kataloget osv. Billedbehandlingen er CPU-krævende, men den generelle brug er hukommelseskrævende.
Billedbehandling er en asynkron opgave, der kan opdeles i et baggrundsjob. Det kan du gøre ved at afkoble din billedbehandlingstjeneste ved hjælp af en kø. Afkobling giver dig mulighed for at skalere begge tjenester uafhængigt – én på hukommelsen (produkttjenesten) og den anden (billedbehandlingstjenesten) på CPU eller endda kølængde, og har et andet skaleringssæt, der forbruger disse meddelelser og behandler billederne.
Skaler med køer
Azure har to typer køtilbud:
- Azure Service Bus køer Et mere avanceret kø-tilbud, som er en del af det bredere Azure Service Bus-produkt, med pub/sub og mere avancerede integrationsmønstre.
- Azure Storage Køer En simpel REST-baseret køgrænseflade bygget oven på Azure Storage. Det tilbyder pålidelige, vedvarende beskeder.
Dine krav i dette scenarie er simple, så du kan bruge Azure Storage Queues. Dit produktniveau behøver slet ikke at skalere, fordi du har afkoblet denne baggrundsopgave.
Cachelagring i hukommelsen
En anden måde at forbedre ydeevnen for dit program på er ved at implementere en cache i hukommelsen.
Nu ved du, at ydeevnen ikke svarer nøjagtigt til skalerbarheden, men ved at forbedre ydeevnen for dit program kan du reducere belastningen af andre ressourcer. Denne forbedring betyder, at du muligvis ikke behøver at skalere så hurtigt.
Azure Managed Redis (tidligere Azure Cache for Redis) er et managed Redis-tilbud. Redis kan bruges til mange mønstre og use cases. For din produkttjeneste i dette scenarie vil du sandsynligvis implementere cacheudtagningsmønsteret. I dette mønster indlæser du elementer fra databasen i cachen efter behov, hvilket gør programmet mere effektiv og reducerer belastningen af databasen.
Redis kan også bruges som en beskedkø, til caching af webindhold eller til caching af brugersessioner. Denne type cachelagring kan være mere velegnet til andre tjenester i systemet, f.eks. indkøbskurvtjenesten, hvor du kan gemme indkøbskurvdata pr. session i Redis i stedet for at bruge en cookie.
Skaler databasen
Nu hvor du har gjort dine beregningsressourcer mere skalerbare, så tag et kig på din database. I dette scenarie bruger du Azure SQL Database, som er et administreret SQL Server-tilbud fra Azure.
Relationsdatabaser er sværere at skalere ud end ikke-relationsdatabaser. Det første, du kan gøre for at skalere databasen, er at skalere databasens størrelse op. Denne størrelsesændring kan nemt udføres med kun et kort øjebliks forbindelsestab, enten ved at bruge et simpelt API-kald i Azure SQL eller ved at bruge en skyder i portalen.
Hvis denne størrelsesopgradering ikke opfylder dine krav, kan det afhængigt af trafikkarakteristika være hensigtsmæssigt at skalere læsningerne ud til databasen, så du kan dirigere læsetrafik til din læsereplika.
Seddel
Med Azure SQL er Read Scale-Out tilgængelig som standard på Premium-, Business Critical- og Hyperscale-niveauerne. For Hyperscale skal mindst én sekundær replika konfigureres. Det kan ikke aktiveres på Basic- eller Standard-niveauerne.
Denne ændring skal implementeres i kode. Du specificerer routing-intentionen ved at sætte attributten ApplicationIntent i din database forbindelsesstreng. Brug ReadOnly den til at forbinde til replikaen eller ReadWrite til at forbinde til primæren.
Den anbefalede tilgang er at bruge administrerede identiteter til autentificering og gemme eventuelle nødvendige konfigurationer i Azure Key Vault:
#Read Replica Connection String (recommended: managed identity)
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadOnly;Authentication=Active Directory Default;Encrypt=True;
#Primary Connection String (recommended: managed identity)
Server=tcp:<server>.database.windows.net;Database=<mydatabase>;ApplicationIntent=ReadWrite;Authentication=Active Directory Default;Encrypt=True;
Vigtigt!
I produktion skal du bruge managed identities til autentificering. For eventuelle yderligere hemmeligheder, som din applikation kræver, gem dem i Azure Key Vault i stedet for i kode eller konfigurationsfiler.
Fordi denne ændring skal implementeres i koden, er det måske ikke en passende løsning for din situation. Hvad nu, hvis hver enkelt produkttjeneste har brug for evnen til at læse og skrive?
I så fald kan du overveje at skalere Azure SQL Database ud ved at bruge sharding.
Databaseharding
Hvis dine databaseressourcer stadig ikke opfylder systemets behov efter skalering eller implementering af læste replikaer, er næste mulighed sharding.
Sharding er en teknik til at distribuere store mængder identisk strukturerede data på tværs af mange uafhængige databaser. Afskrævning kan være påkrævet af mange grunde. For eksempel:
- Den samlede mængde data er for stor til at passe inden for begrænsningerne i en enkelt database.
- Overførselshastigheden for den overordnede arbejdsbelastning overskrider egenskaberne i en individuel database.
- Separate lejere skal være placeret på forskellige fysiske databaser af hensyn til overholdelse af angivne standarder (dette krav handler mindre om skalering, men er en anden situation, hvor der bruges dele).
Din applikation tilføjer de relevante data til den relevante shard og gør dermed dit system skalerbart ud over den enkelte databases begrænsninger.
Azure SQL tilbyder Azure Elastic Database-værktøjerne. Disse værktøjer hjælper dig med at oprette, vedligeholde og forespørge sharded SQL-databaser i Azure ud fra din applikationslogik.
Tjek din viden
Feedback
Var denne side nyttig?
No
Har du brug for hjælp til dette emne?
Vil du prøve at bruge Ask Learn til at tydeliggøre eller guide dig gennem dette emne?