Talegenkendelse
Notat
Se fanen Tekst og billeder for flere detaljer!
Talegenkendelse, også kaldet tale-til-tekst, gør det muligt for applikationer at konvertere talt sprog til skrevet tekst. Rejsen fra lydbølge til tekst involverer seks koordinerede faser: optagelse af lyd, forberedelse af funktioner, modellering af akustiske mønstre, anvendelse af sprogregler, afkodning af de mest sandsynlige ord og forfining af det endelige output.
Lydoptagelse: Konverter analog lyd til digital
Talegenkendelse begynder, når en mikrofon konverterer lydbølger til et digitalt signal. Systemet sampler den analoge lyd tusindvis af gange i sekundet – typisk 16.000 samples pr. sekund (16 kHz) til taleapplikationer – og gemmer hver måling som en numerisk værdi.
Notat
Hvorfor samplingsfrekvens er vigtig:
- Højere hastigheder (f.eks. 44,1 kHz for musik) fanger flere detaljer, men kræver mere behandling.
- Talegenkendelse afbalancerer klarhed og effektivitet ved 8 kHz til 16 kHz.
- Baggrundsstøj, mikrofonkvalitet og afstand fra højttaleren påvirker direkte downstream-nøjagtigheden.
Før systemet går videre til næste trin, anvender systemet ofte grundlæggende filtre for at fjerne brummen, klik eller anden baggrundsstøj, der kan forvirre modellen.
Forbehandling: Udtræk meningsfulde funktioner
Rå lydprøver indeholder for meget information til effektiv mønstergenkendelse. Forbehandling omdanner bølgeformen til en kompakt repræsentation, der fremhæver talekarakteristika, mens irrelevante detaljer som absolut lydstyrke kasseres.
Mel-Frequency cepstrale koefficienter (MFCC'er)
MFCC er den mest almindelige funktionsekstraktionsteknik inden for talegenkendelse. Det efterligner, hvordan det menneskelige øre opfatter lyd ved at fremhæve frekvenser, hvor taleenergien koncentreres, og komprimere mindre vigtige områder.
Sådan fungerer MFCC:
- Opdel lyd i rammer: Opdel signalet i overlappende 20-30 millisekunders vinduer.
- Anvend Fourier-transformering: Konverter hvert billede fra tidsdomæne til frekvensdomæne, og afslør, hvilke tonehøjder der er til stede.
- Kort til Mel skala: Juster frekvensbeholdere, så de passer til menneskers hørefølsomhed – vi skelner bedre mellem lave tonehøjder og høje.
- Uddrag koefficienter: Beregn et lille sæt tal (ofte 13 koefficienter), der opsummerer den spektrale form af hvert billede.
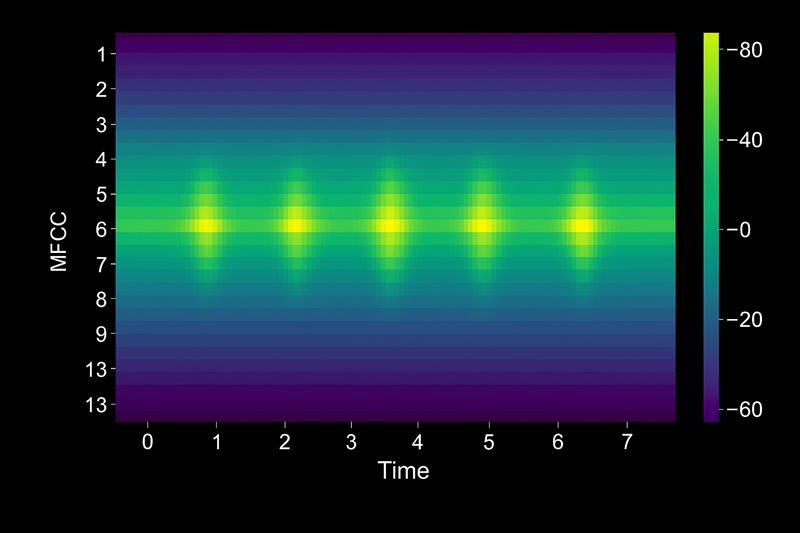
Resultatet er en sekvens af funktionsvektorer – en pr. billede – der fanger, hvordan lyden lyder uden at gemme hver sample. Disse vektorer bliver input til akustisk modellering.
Vektorerne udtrækkes kolonnevis, hvor hver vektor repræsenterer de 13 MFCC-funktionskoefficientværdier for hver tidsramme:
Frame 1: [ -113.2, 45.3, 12.1, -3.4, 7.8, ... ] # 13 coefficients
Frame 2: [ -112.8, 44.7, 11.8, -3.1, 7.5, ... ]
Frame 3: [ -110.5, 43.9, 11.5, -2.9, 7.3, ... ]
Akustisk modellering: Genkend fonemer
Akustiske modeller lærer forholdet mellem lydfunktioner og fonemer – de mindste lydenheder, der adskiller ord. Engelsk bruger omkring 44 fonemer; For eksempel består ordet "kat" af tre fonemer: /k/, /æ/ og /t/.
Fra funktioner til fonemer
Moderne akustiske modeller bruger transformerarkitekturer, en type deep learning-netværk, der udmærker sig ved sekvensopgaver. Transformatoren behandler MFCC-funktionsvektorerne og forudsiger, hvilket fonem der er mest sandsynligt på hvert tidspunkt.
Transformermodeller opnår effektiv fonemforudsigelse gennem:
- Opmærksomhed mekanisme: Modellen undersøger omgivende rammer for at løse tvetydighed. F.eksample, fonemet /t/ lyder anderledes i starten af "top" i forhold til slutningen af "bat".
- Parallel behandling: I modsætning til ældre tilbagevendende modeller analyserer transformere flere billeder samtidigt, hvilket forbedrer hastigheden og nøjagtigheden.
- Kontekstualiserede forudsigelser: Netværket lærer, at visse fonemsekvenser forekommer hyppigt i naturlig tale.
Outputtet af akustisk modellering er en sandsynlighedsfordeling over fonemer for hver lydramme. For eksempel kan ramme 42 vise 80% konfidens for /æ/, 15% for /ɛ/ og 5% for andre fonemer.
Notat
Fonemer er sprogspecifikke. En model, der er trænet på engelske fonemer, kan ikke genkende mandarintoner uden omskoling.
Sprogmodellering: Forudsige ordsekvenser
Fonemforudsigelser alene garanterer ikke nøjagtig transskription. Den akustiske model kan forveksle "deres" og "der", fordi de deler identiske fonemer. Sprogmodeller løser tvetydighed ved at anvende viden om ordforråd, grammatik og almindelige ordmønstre. Nogle måder, hvorpå modellen styrer ordsekvensforudsigelse, omfatter:
- Statistiske mønstre: Modellen ved, at "Vejret er godt" optræder oftere i træningsdata end "Om er godt."
- Kontekst bevidsthed: Efter at have hørt "Jeg er nødt til", forventer modellen verber som "gå" eller "afslut", ikke navneord som "tabel".
- Tilpasning af domænet: Brugerdefinerede sprogmodeller, der er trænet i medicinsk eller juridisk terminologi, forbedrer nøjagtigheden for specialiserede scenarier.
Afkodning: Vælg den bedste teksthypotese
Afkodningsalgoritmer søger gennem millioner af mulige ordsekvenser for at finde den transskription, der bedst matcher både akustiske og sprogmodelforudsigelser. Denne fase balancerer to konkurrerende mål: at forblive tro mod lydsignalet og samtidig producere læsbar, grammatisk korrekt tekst.
Afkodning af strålesøgning:
Den mest almindelige teknik, strålesøgning, opretholder en shortlist ("strålen") over topscorende delvise transskriptioner, når den behandler hver lydramme. Ved hvert trin udvider den hver hypotese med det næstmest sandsynlige ord, beskærer stier med lav score og beholder kun de bedste kandidater.
For en tre-sekunders ytring kan dekoderen evaluere tusindvis af hypoteser, før den vælger "Send venligst rapporten inden fredag" frem for alternativer som "Send venligst rapporten køb fredag."
Advarsel
Afkodning er beregningskrævende. Realtidsapplikationer balancerer nøjagtighed og latenstid ved at begrænse strålebredde og hypotesedybde.
Efterbehandling: Finjuster outputtet
Dekoderen producerer rå tekst, der ofte kræver oprydning før præsentation. Efterbehandling anvender formateringsregler og rettelser for at forbedre læsbarheden og nøjagtigheden.
Almindelige efterbehandlingsopgaver:
- Kapitalisering: Konverter "hej, mit navn er Sam" til "Hej, mit navn er Sam."
- Gendannelse af tegnsætning: Tilføj punktummer, kommaer og spørgsmålstegn baseret på prosodi og grammatik.
- Formatering af tal: Skift "et tusind treogtyve" til "1.023".
- Filtrering af bandeord: Masker eller fjern upassende ord, når det kræves af politikken.
- Omvendt tekstnormalisering: Konverter talte former som "tre ppm " til "3 PM".
- Tillidsscoring: Markér ord med lav tillid til menneskelig gennemgang i kritiske applikationer som medicinsk transskription.
Azure Speech returnerer den endelige transskription sammen med metadata som tidsstempler på ordniveau og tillidsscores, hvilket gør det muligt for din applikation at fremhæve usikre segmenter eller udløse fallback-adfærd.
Sådan fungerer pipelinen sammen
Hver fase bygger på den forrige:
- Lydoptagelse giver det rå signal.
- Forbehandling udtrækker MFCC-funktioner, der fremhæver talemønstre.
- Akustisk modellering forudsiger fonemsandsynligheder ved hjælp af transformatornetværk.
- Sprogmodellering anvender ordforråd og grammatikviden.
- Afkodning søger efter den bedste ordsekvens.
- Efterbehandling formaterer teksten til menneskelige læsere.
Ved at adskille bekymringer opnår moderne talegenkendelsessystemer høj nøjagtighed på tværs af sprog, accenter og akustiske forhold. Når transskriptionskvaliteten er mangelfuld, kan du ofte spore problemet til ét trin – dårlig lydoptagelse, utilstrækkelig træning af sprogmodeller eller alt for aggressiv efterbehandling – og justere i overensstemmelse hermed.