Optisk tegngenkendelse (OCR)
Bemærk
Se fanen Tekst og billeder for flere detaljer!
Optisk tegngenkendelse (OCR) er en teknologi, der automatisk konverterer visuel tekst i billeder – uanset om det er fra scannede dokumenter, fotografier eller digitale filer – til redigerbar, søgbar tekstdata. I stedet for manuelt at transskribere information muliggør OCR automatiseret dataudtrækning fra:
- Scannede fakturaer og kvitteringer
- Digitale fotografier af dokumenter
- PDF-filer med billeder af tekst
- Skærmbilleder og optaget indhold
- Formularer og håndskrevne noter
OCR-pipelinen: En trin-for-trin proces
OCR-pipelinen består af fem væsentlige faser, der arbejder sammen for at omdanne visuel information til tekstdata.
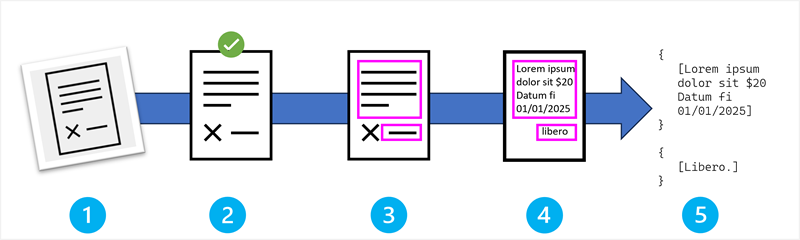
Stadierne i OCR-processen er:
- Billedoptagelse og input.
- Forbehandling og billedforbedring.
- Tekstregionsdetektion.
- Tegngenkendelse og klassificering.
- Outputgenerering og efterbehandling.
Lad os undersøge hvert trin mere i dybden.
Fase 1: Billedoptagelse og input
Pipelinen begynder, når et billede med tekst kommer ind i systemet. Dette kunne være:
- Et fotografi taget med et smartphone-kamera.
- Et scannet dokument fra en fladbed- eller dokumentscanner.
- En ramme udtrukket fra en videostrøm.
- En PDF-side gengivet som et billede.
Tips
Billedkvaliteten på dette stadie har en betydelig indvirkning på den endelige nøjagtighed af tekstudtrækningen.
Fase 2: Forbehandling og billedforbedring
Før tekstdetektion begynder, anvendes følgende teknikker til at optimere billedet for bedre genkendelsesnøjagtighed:
Støjreduktion fjerner visuelle artefakter, støvpletter og scanningsfejl, som kan forstyrre tekstregistrering. De specifikke teknikker, der bruges til at udføre støjreduktion, omfatter:
- Filtrerings- og billedbehandlingsalgoritmer: Gaussiske filtre, medianfiltre og morfologiske operationer.
- Maskinlæringsmodeller: Denoising autoencoders og konvolutionelle neurale netværk (CNN'er), der er trænet specifikt til oprydning af dokumentbilleder.
Kontrastjustering forbedrer forskellen mellem tekst og baggrund for at gøre tegnene mere tydelige. Igen er der flere mulige tilgange:
- Klassiske metoder: Histogramudligning, adaptiv tærskel og gamma-korrektion.
- Maskinlæring: Dyb læringsmodeller, der lærer optimale forbedringsparametre for forskellige dokumenttyper.
Skævhedskorrektion opdager og korrigerer dokumentrotation, så tekstlinjerne er korrekt justeret horisontalt. Teknikker til skævhedskorrektion inkluderer:
- Matematiske teknikker: Hough-transform til linjedetektion, projektionsprofiler og analyse af forbundne komponenter.
- Neurale netværksmodeller: Regressions-CNN'er, der forudsiger rotationsvinkler direkte ud fra billedfunktioner.
Opløsningsoptimering justerer billedopløsningen til det optimale niveau for tegngenkendelsesalgoritmer. Du kan optimere billedopløsningen med:
- Interpolationsmetoder: Bikubiske, bilineære og Lanczos resampling-algoritmer.
- Superopløsningsmodeller: Generative adversarielle netværk (GAN'er) og residualnetværk, der intelligent opskalerer lavopløsnings tekstbilleder.
Fase 3: Tekstregionsdetektion
Systemet analyserer det forbehandlede billede for at identificere områder, der indeholder tekst, ved hjælp af følgende teknikker:
Layoutanalyse skelner mellem tekstområder, billeder, grafik og hvide rumområder. Teknikker til layoutanalyse inkluderer:
- Traditionelle tilgange: Connected component-analyse, run-length encoding og projektionsbaseret segmentering.
- Deep learning-modeller: Semantiske segmenteringsnetværk som U-Net, Mask R-CNN og specialiserede modeller for analyse af dokumentlayout (for eksempel LayoutLM eller PubLayNet-trænede modeller).
Tekstblokidentifikation grupperer individuelle tegn i ord, linjer og afsnit baseret på rumlige relationer. Almindelige tilgange omfatter:
- Klassiske metoder: Afstandsbaseret klyngedannelse, hvidrumsanalyse og morfologiske operationer
- Neurale netværk: Grafbaserede neurale netværk og transformermodeller, der forstår rumlig dokumentstruktur
Bestemmelse af læserækkefølgen fastlægger rækkefølgen, hvori teksten skal læses (fra venstre mod højre, oppefra og ned for engelsk). Den korrekte rækkefølge kan bestemmes ved:
- Regelbaserede systemer: Geometriske algoritmer, der bruger koordinater for afgrænsningsbokse og rumlige heuristikker.
- Maskinlæringsmodeller: Sekvensforudsigelsesmodeller og grafbaserede tilgange, der lærer at læse mønstre fra træningsdata.
Regionsklassificering identificerer forskellige typer tekstområder (overskrifter, brødtekst, billedtekster, tabeller).
- Funktionsbaserede klassifikatorer: Understøtter vektormaskiner (SVM'er), der bruger håndlavede funktioner som skriftstørrelse, position og formatering
- Deep learning-modeller: Konvolutionelle neurale netværk og visionstransformere trænet på mærkede dokumentdatasæt
Fase 4: Karaktergenkendelse og klassificering
Dette er kernen i OCR-processen, hvor individuelle tegn identificeres:
Feature-ekstraktion: Analyserer form, størrelse og karakteristiske karakteristika for hvert tegn eller symbol.
- Traditionelle metoder: Statistiske træk som momenter, Fourier-beskrivelser og strukturelle træk (løkker, endepunkter, krydsninger)
- Deep learning-tilgange: Konvolutionelle neurale netværk, der automatisk lærer diskriminative træk ud fra rå pixeldata
Mønstermatchning: Sammenligner udtrukne funktioner med trænede modeller, der genkender forskellige skrifttyper, størrelser og skrivestile.
- Skabelonmatchning: Direkte sammenligning med lagrede karakterskabeloner ved brug af korrelationsteknikker
- Statistiske klassifikatorer: Skjulte Markov-modeller (HMM'er), Support Vector Machines og k-nærmeste naboer ved brug af featurevektorer
- Neurale netværk: Multi-layer perceptrons, CNN'er og specialiserede arkitekturer som LeNet til ciffergenkendelse
- Avanceret dyb læring: Residual networks (ResNet), DenseNet og EfficientNet-arkitekturer til robust tegnklassifikation
Kontekstanalyse: Bruger omgivende tegn og ord for at forbedre genkendelsesnøjagtigheden gennem ordbogsopslag og sprogmodeller.
- N-gram modeller: Statistiske sprogmodeller, der forudsiger tegnsekvenser baseret på sandsynlighedsfordelinger.
- Ordbogsbaseret korrektion: Leksikonopslag med redigeringsafstandsalgoritmer (såsom Levenshtein distance) til stavekorrektion.
- Neurale sprogmodeller: LSTM- og transformerbaserede modeller (som BERT-varianter), der forstår kontekstuelle relationer.
- Opmærksomhedsmekanismer: Transformer-modeller, der fokuserer på relevante dele af inputtet, når man laver karakterforudsigelser.
Tillidsscore: Tildeler sandsynlighedsscorer til hver genkendt karakter baseret på, hvor sikker systemet er på sin identifikation.
- Bayesianske tilgange: Sandsynlighedsmodeller, der kvantificerer usikkerhed i karakterforudsigelser.
- Softmax-output: Aktiveringer af det neurale netværks sidste lag konverteret til sandsynlighedsfordelinger.
- Ensemble-metoder: Kombinering af forudsigelser fra flere modeller for at forbedre konfidensestimaterne.
Trin 5: Outputgenerering og efterbehandling
Det sidste trin omdanner genkendelsesresultater til brugbare tekstdata:
Tekstkompilering: Samler individuelle tegngenkendelser til komplette ord og sætninger.
- Regelbaseret samling: Deterministiske algoritmer, der kombinerer tegnforudsigelser ved hjælp af rumlig nærhed og konfidenstærskler.
- Sekvensmodeller: Rekurrente neurale netværk (RNN'er) og Long Short-Term Memory (LSTM)-netværk, der modellerer tekst som sekventiel data.
- Opmærksomhedsbaserede modeller: Transformer-arkitekturer, der kan håndtere sekvenser med variabel længde og komplekse tekstlayouts.
Formatbevarelse: Opretholder dokumentstruktur inklusive afsnit, linjeskift og afstand.
- Geometriske algoritmer: Regelbaserede systemer, der bruger koordinater til afgrænsningsbokse og hvidrumsanalyse.
- Layout-forståelsesmodeller: Grafer neurale netværk og dokumenterer AI-modeller, der lærer strukturelle sammenhænge.
- Multimodale transformere: Modeller som LayoutLM, der kombinerer tekst og layoutinformation for strukturbevarelse.
Koordinatkortlægning: Registrerer den præcise position af hvert tekstelement i det oprindelige billede.
- Koordinattransformation: Matematisk kortlægning mellem billedpixels og dokumentkoordinater.
- Rumlig indeksering: Datastrukturer som R-træer og quad-træer til effektive rumlige forespørgsler.
- Regressionsmodeller: Neurale netværk trænet til at forudsige præcise tekstpositioneringskoordinater.
Kvalitetsvalidering: Anvender stave- og grammatikkontroller for at identificere potentielle genkendelsesfejl.
- Ordbogsbaseret validering: Slå op mod omfattende ordlister og specialiserede domæneordforråd.
- Statistiske sprogmodeller: N-grammodeller og probabilistiske parsere til grammatik- og kontekstvalidering.
- Neurale sprogmodeller: Forudtrænede modeller som GPT eller BERT, finjusteret til OCR-fejldetektion og korrektion.
- Ensemblevalidering: Kombinering af flere valideringsmetoder for at forbedre fejlopdagelsesnøjagtigheden.