Feltudtrækning og kortlægning
Notat
Se fanen Tekst og billeder for flere detaljer!
Feltudtrækning er processen med at tage tekstoutput fra OCR og mappe individuelle tekstværdier til specifikke, mærkede datafelter, der svarer til meningsfuld forretningsinformation. Mens OCR fortæller dig, hvilken tekst der findes i et dokument, fortæller feltudvinding dig, hvad teksten betyder , og hvor den hører hjemme i dine forretningssystemer.
Feltudtagningsrørledningen
Feltudtrækning følger en systematisk pipeline, der omdanner OCR-output til strukturerede data.
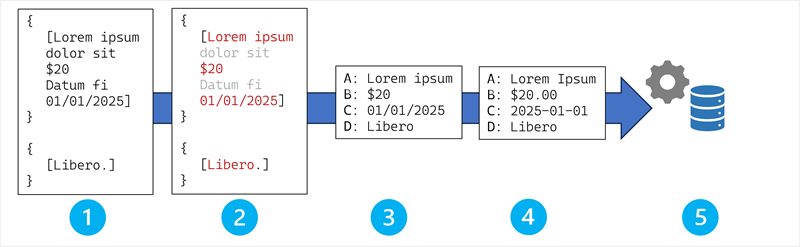
Stadierne i feltudtrækningsprocessen er:
- OCR-outputoptagelse.
- Feltdetektion og kandidatidentifikation.
- Feltkortlægning og association.
- Datanormalisering og standardisering.
- Integration med forretningsprocesser og systemer.
Lad os udforske disse stadier mere detaljeret.
Trin 1: OCR-outputoptagelse
Processen begynder med det strukturerede output fra OCR-pipelinen, som kan omfatte:
- Råtekstindhold: De faktiske tegn og ord, der er udtrukket fra dokumentet
- Positionsmetadata: Koordinater for afgrænsningsbokse, sideplaceringer og læseordensinformation
- Tillidsscore: OCR-motorens konfidensniveauer for hvert tekstelement
- Layoutinformation: Dokumentstruktur, linjeskift, afsnitsgrænser
Notat
I modsætning til simpel tekstbehandling afhænger feltudtrækning i høj grad af , hvor teksten vises i dokumentet, ikke kun hvad der står. Positionen "12345" kan hjælpe med at afgøre, om det er et fakturanummer, kunde-ID eller telefonnummer.
Fase 2: Feltdetektion og kandidatidentifikation
Dette trin identificerer potentiel feltværdi i OCR-outputtet. Der findes flere tilgange, som kan bruges, uafhængigt eller i kombination, til at bestemme de sandsynlige felter i OCR-resultaterne.
Skabelonbaseret detektion
Skabeloner til feltdetektion er baseret på regelbaseret mønstermatchning. Feltidentifikation kan udføres ved hjælp af teknikker såsom:
- Foruddefinerede dokumentlayouts med kendte feltpositioner og ankernøgleord.
- Søger efter label-værdi-par som "Fakturanummer:", "Dato:", "Total:".
- Regulære udtryk og algoritmer for strengmatchning.
Fordele ved en skabelonbaseret tilgang inkluderer høj nøjagtighed for kendte dokumenttyper, hurtig behandling og forklarlige resultater.
Begrænsninger ved tilgangen inkluderer kravet om manuel skabelonoprettelse og kompleksitet forårsaget af layoutvariationer eller uoverensstemmelser i feltnavne.
Maskinlæringsbaseret detektion
I stedet for hardkodet logik til at udtrække felter baseret på kendte navne og placeringer, kan du bruge et korpus af eksempeldokumenter til at træne en maskinlæringsmodel, der udtrækker felterne baseret på lærte relationer. Især transformer-baserede modeller er gode til at anvende kontekstuelle signaler til at identificere mønstre og danner derfor ofte grundlaget for en feltdetektionsløsning.
Træningsmetoder til feltdetektion af maskinlæringsmodeller omfatter:
- Superviseret læring: Trænes på mærkede datasæt med kendte feltplaceringer.
- Selvsuperviseret læring: Forudlært på store dokumentkorpusa for at forstå layoutmønstre.
- Multimodal læring: Kombinerer tekst, visuel og positionsmæssig funktion.
-
Avancerede modelarkitekturer, såsom:
- Grafneurale netværk (GNN'er), der modellerer rumlige relationer mellem tekstelementer som grafforbindelser.
- Opmærksomhedsmekanismer , der fokuserer på relevante dokumentregioner ved forudsigelse af feltværdier.
- Sekvens-til-sekvens-modeller , der omdanner ustrukturerede tekstsekvenser til strukturerede felttildelinger.
Generativ AI til skemabaseret ekstraktion
Nylige fremskridt inden for store sprogmodeller (LLM'er) har ført til fremkomsten af generative AI-baserede feltdetektionsteknikker, som muliggør mere effektiv og virkningsfuld feltdetektion gennem:
- Prompt-baseret udtræk, hvor du giver LLM'en dokumenttekst og en skema-definition, og den matcher teksten med felterne i skemaet.
- Få-shot læring , hvor du kan træne modeller med minimale eksempler til at udtrække brugerdefinerede felter.
- Tankekæderæsonnement, der guider modeller gennem trin-for-trin feltidentifikationslogik.
Fase 3: Feltkortlægning og association
Når kandidatværdier er identificeret, skal de kortlægges til specifikke skemafelter:
Nøgleværdiparringsteknikker
I mange tilfælde er datafelter i et dokument eller formular diskrete værdier, der kan kortlægges til nøgler – for eksempel leverandørens navn, dato og det samlede beløb i en kvittering eller faktura. Almindelige teknikker brugt til nøgle-værdi-parring inkluderer:
Nærhedsanalyse:
- Rumlig klyngedannelse: Gruppere nærliggende tekstelementer ved hjælp af afstandsalgoritmer.
- Analyse af læserækkefølge: Følg naturlig tekstflow for at forbinde etiketter med værdier.
- Geometriske relationer: Brug justerings-, indryknings- og positioneringsmønstre.
Sproglig mønstergenkendelse:
- Navngivet enhedsgenkendelse (NER): Identificer specifikke enhedstyper (datoer, beløb, navne).
- Ordklasse-tagging: Forstå grammatiske relationer mellem etiketter og værdier.
- Afhængighedsparsning: Analyser syntaktiske relationer i tekst.
Tabel- og struktureret indholdsbehandling
Nogle dokumenter indeholder mere komplekse tekststrukturer, såsom tabeller. For eksempel kan en kvittering eller faktura indeholde en tabel over linjeposter med kolonner for varenavn, pris og købt mængde.
Tilstedeværelsen af et bord kan bestemmes ved hjælp af flere teknikker, herunder:
- Specialiserede konvolutionelle neurale netværksarkitekturer (CNN) til genkendelse af tabelstrukturer.
- Objektdetektionsmetoder tilpasset til identifikation af bordceller.
- Grafbaseret parsing nærmer sig, der modellerer tabelstruktur som grafrelationer mellem celler.
For at kortlægge værdierne i cellerne i en tabel til felter kan feltekstraktionsløsningen anvende en eller flere af følgende teknikker:
- Række-kolonne association til at kortlægge tabelceller til specifikke feltskemaer.
- Header-detektion for at identificere kolonneoverskrifter for at forstå feltbetydninger.
- Hierarkisk behandling til håndtering af indlejrede tabelstrukturer og deltotaler.
Tillidsbedømmelse og validering
Nøjagtigheden af feltudtrækning afhænger af mange faktorer, og de algoritmer og modeller, der anvendes til at implementere løsningen, er udsat for potentielle fejl i fejltolkning eller værdifortolkning. For at tage højde for dette anvendes forskellige teknikker til at evaluere nøjagtigheden af de forudsagte feltværdier; herunder:
- OCR-tillid: At arve tillidsscorer fra den underliggende tekstgenkendelse.
- Mønstermatchnings-tillid: Scoring baseret på, hvor godt ekstraktionen matcher forventede mønstre.
- Kontekstvalidering: At verificere at feltværdier giver mening i dokumentets kontekst.
- Tværfaglig validering: Kontrol af relationer mellem udtrukne felter (for eksempel at verificere at linjepostens delsummer summeres til det samlede fakturatal).
Fase 4: Datanormalisering og standardisering
Rå udtrukne værdier konverteres generelt til konsistente formater (for eksempel for at sikre, at alle udtrukne datoer udtrykkes i samme datoformat) og kontrolleres for gyldighed.
Formateringsstandardisering
Eksempler på formatstandardisering, der kan implementeres, inkluderer:
Datonormalisering:
- Formatdetektion: Identificer forskellige datoformater (MM/DD/YYYYY, DD-MM-YYYY osv.).
- Parsing algoritmer: Konverter til standardiserede ISO-formater.
- Løsning af tvetydighed: Håndter sager, hvor datoformatet er uklart.
Valuta og numerisk behandling:
- Symbolgenkendelse: Håndter forskellige valutasymboler og tusind-separatorer.
- Decimalnormalisering: Standardiser decimalrepræsentation på tværs af lokaliteter.
- Enhedsomregning: Konverter mellem forskellige måleenheder efter behov.
Tekststandardisering:
- Kasus-normalisering: Anvend ensartede regler for store bogstaver.
- Standardisering af kodning: Håndter forskellige tegnkodninger og specialtegn.
- Forkortelsesudvidelse: Konverter almindelige forkortelser til fulde former.
Datavalidering og kvalitetssikring
Ud over at formatere de udtrukne felter muliggør standardiseringsprocessen yderligere validering af de værdier, der er udtrukket gennem teknikker som:
Regelbaseret validering:
- Formatkontrol: Kontroller de udtrukne værdier matcher forventede mønstre (telefonnumre, e-mailadresser).
- Intervalvalidering: Sørg for, at numeriske værdier ligger inden for rimelige grænser.
- Påkrævet feltkontrol: Bekræft at alle obligatoriske felter er til stede.
Statistisk validering:
- Afvigelsesdetektion: Identificer usædvanligt høje eller lave værdier, der kan indikere ekstraktionsfejl.
- Fordelingsanalyse: Sammenlign udtrukne værdier med historiske mønstre.
- Krydsdokumentvalidering: Tjek konsistens på tværs af relaterede dokumenter.
Fase 5: Integration med forretningsprocesser og systemer
Den sidste fase af processen involverer normalt integration af de udtrukne feltværdier i en forretningsproces eller et system:
Skema-mapping
De udtrukne felter kan have behov for yderligere transformering eller omformatering, så de stemmer overens med applikationsskemaer, der bruges til dataindlæsning i nedstrøms systemer. For eksempel:
- Databaseskemaer: Kortlæg udtrukne felter til specifikke databasekolonner og tabeller.
- API-payloads: Formater data til REST API-forbrug af downstream-systemer.
- Beskedkøer: Forbered strukturerede beskeder til asynkron behandling.
Skema-mapping-processen kan involvere transformationer såsom:
- Omdøbning af felt: Kortlæg udtrukne feltnavne til målsystemkonventioner.
- Datatypekonvertering: Sørg for, at værdierne matcher forventede datatyper i målsystemer.
- Betinget logik: Anvend forretningsregler for felttransformation og udledning.
Kvalitetsmålinger og rapportering
En anden almindelig opgave efter udtræksprocessen er afsluttet, er at evaluere og rapportere om kvaliteten af de udtrukne data. Rapporten kan indeholde oplysninger som:
- Feltniveau-tillidsscorer: Individuelle selvtillidsvurderinger for hvert udtrukket felt.
- Kvalitetsvurdering på dokumentniveau: Overordnede udtrækningssuccesmålinger.
- Fejlkategorisering: Klassificer udtrækningsfejl efter type og årsag.