Identificer nøglekomponenter i LLM-programmer
Store sprogmodellerer som avancerede sprogbehandlingssystemer, der er udviklet til at forstå og generere menneskeligt sprog. Tænk på dem som at have fire vigtige dele, der arbejder sammen, ligesom hvordan en bil har brug for en motor, brændstofsystem, transmission og rat til at fungere korrekt.
- Spørg: Dine instruktioner til modellen. Prompten er den måde, du kommunikerer med LLM på. Det er dit spørgsmål, din anmodning eller din instruktion.
- Tokenizer: Opdeler sproget. Tokenizeren er en sprogoversætter, der konverterer menneskelig tekst til et format, som computeren kan forstå.
- Model: Operationens 'hjerne'. Modellen er den faktiske 'hjerne', der behandler oplysninger og genererer svar. Den er typisk baseret på transformerarkitekturen, bruger selvbevågende mekanismer til at behandle tekst og genererer kontekstafhængigt relevante svar.
- Opgaver: Hvad LLMs kan gøre. Opgaver er de forskellige sprogrelaterede job, som LLMs kan udføre, f.eks. tekstklassificering, oversættelse og generering af dialog.
Disse komponenter opretter et effektivt sprogbehandlingssystem:
- Du angiver en prompt (din instruktion)
- Tokenizeren opdeler den (gør den computerlæsbar)
- Modellen behandler den (ved hjælp af transformerarkitektur og selvbevågenhed)
- Modellen udfører opgaven (genererer det svar, du har brug for)
Dette koordinerede system gør det muligt for CHAT'er at udføre komplekse sprogopgaver med bemærkelsesværdig nøjagtighed og flydende, hvilket gør dem nyttige for alt fra at skrive hjælp til kundeservice til oprettelse af kreativt indhold.
Forstå de opgaver, som LLMs udfører
LLMs er designet til at udføre en lang række sprogrelaterede opgaver. LLMs er ideelle til behandling af naturligt sprog eller NLP (1), opgaver på grund af deres dybe forståelse af tekst og kontekst. NLP (Natural Language Processing) er området for kunstig intelligens, der fokuserer på at gøre det muligt for computere at forstå, fortolke og generere menneskeligt sprog på en måde, der er meningsfuld og nyttig. I forbindelse med LLM-opgaver repræsenterer NLP kategorien af sprogrelaterede funktioner, som LLMs-modeller udmærker sig ved på grund af deres dybe forståelse af tekst og kontekst.
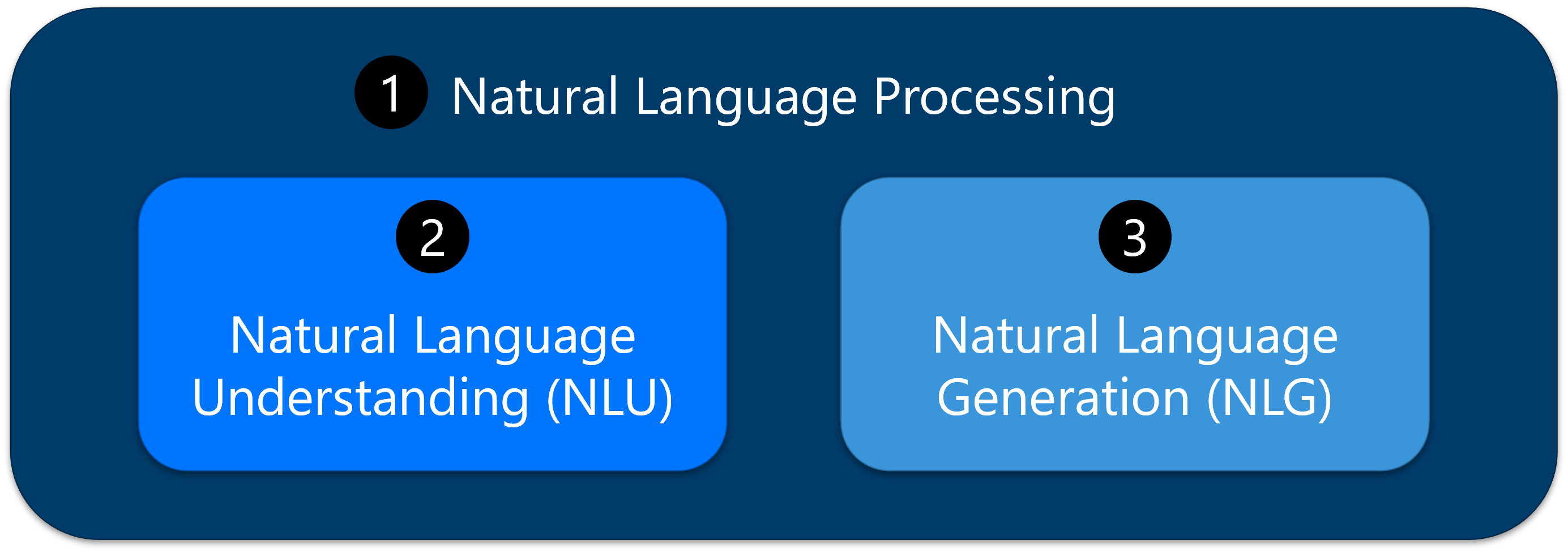
En kategori af NLP-opgaver omfatter forståelse af naturligt sprog eller NLU (2), opgaver som synspunktsanalyse, navngivet enhedsgenkendelse (NER) og tekstklassificering, som involverer udtrækning af betydning og identificering af bestemte elementer i teksten.
Et andet sæt NLP-opgaver hører under generering af naturligt sprog eller NLG (3), herunder tekstfuldførelse, opsummering, oversættelse og oprettelse af indhold, hvor modellen genererer sammenhængende og kontekstafhængig passende tekst baseret på angivne input.
LLMs bruges også i dialogsystemer og samtaleagenter , hvor de kan deltage i menneskelignende samtaler, hvilket giver relevante og præcise svar på brugerforespørgsler.
Forstå vigtigheden af tokenizeren
Tokenization er et vigtigt forbehandlingstrin i VM'er. Det konverterer menneskelig tekst til et format, som en computer kan forstå. Teksten opdeles i håndterbare enheder kaldet tokens. Disse tokens kan være ord, underord eller endda individuelle tegn, afhængigt af den anvendte tokeniseringsstrategi.
Tokeniseringsprocessen kan opsummeres på følgende måde:
- Opdel tekst i tokens: "Hello world" kan blive ["Hello", "world"] eller endda ["Hel", "lo", "wor", "ld"]
- Håndter forskellige sprog: Behandler engelsk, spansk, kinesisk osv.
- Gør behandlingen effektiv: Mindre stykker er nemmere for modellen at arbejde med
- Konvertér til tal: Computere arbejder med tal, ikke bogstaver, så "Hello" bliver noget i stil med [7592, 1917]
Moderne tokenizere, f.eks. BPE (Byte Pair Encoding) og WordPiece, opdeler sjældne eller ukendte ord i underordsenheder, hvilket gør det muligt for modellen at håndtere ord uden ordforråd mere effektivt.
Overvej f.eks. følgende sætning:
I heard a dog bark loudly at a cat
Hvis du vil tokenisere denne tekst, kan du identificere hvert enkelt diskret ord og tildele token-id'er til dem. Det kan f.eks. være:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- a (3)
- cat (8)
Sætningen kan nu repræsenteres med tokens:
{1 2 3 4 5 6 7 3 8}
Tokenization hjælper modellen med at opretholde en balance mellem ordforrådsstørrelse og repræsentationseffektivitet, hvilket sikrer, at den kan behandle forskellige tekstinput præcist.
Tokenization gør det også muligt for modellen at konvertere tekst til numeriske formater, der kan behandles effektivt under oplæring og slutning.
Forstå den underliggende modelarkitektur
Tænk på en LLM's arkitektur som kursusplanen for et hus - det viser, hvordan alle dele er organiseret og arbejder sammen om at skabe noget funktionelt.
LLMs bygges ved hjælp af noget, der kaldes transformerarkitekturen. Forestil dig, at du læser en bog, og at du skal forstå, hvordan forskellige sætninger er relateret til hinanden. Den traditionelle fremgangsmåde er at læse ord for ord, fra venstre mod højre, som at læse normalt. I transformertilgangen kan du se på hele siden på én gang og straks se, hvordan alle ordene opretter forbindelse til hinanden.
Selvbevågenhed er en vigtig innovation, der bruges i transformerarkitekturen. Det er som at have en supersmart overstregningstusch, der automatisk markerer de vigtigste ord for at forstå hver sætning.
Eksempel: I sætningen "Hunden jagtede bolden, fordi den var begejstret", hjælper selvbevågenhed modellen med at vide, at "den" refererer til "hunden" (ikke bolden), selvom "hund" vises tidligere i sætningen.
Transformere består af lag af kodere og dekodere , der arbejder sammen om at analysere inputtekst og generere output. Selvbevågenhedsmekanismen gør det muligt for modellen at afveje vigtigheden af forskellige ord i en sætning, hvilket gør det muligt at registrere langtrækkende afhængigheder og kontekst effektivt.
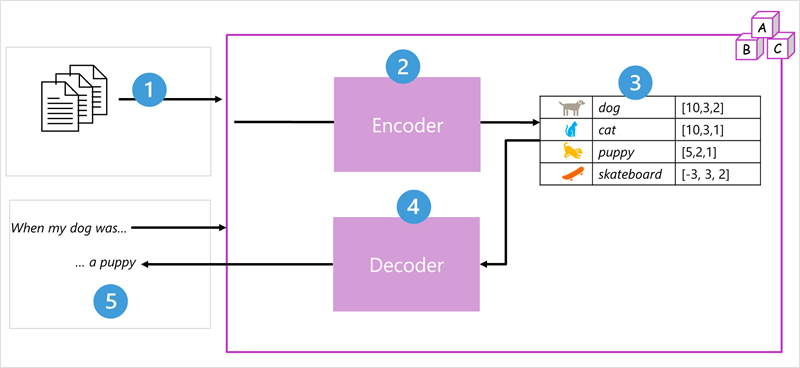
Lad os bruge dette diagram som et eksempel på, hvordan LLM-behandling fungerer.
LLM er oplært i en stor mængde tekst på naturligt sprog.
Trin 1: Input – Træningsdokumenter og en prompt "Da min hund var..." ind i systemet.
Trin 2: Koder (Analysator) – Opdeler tekst i tokens og analyserer dens betydning. Koderblokken behandler tokensekvenser ved hjælp af selvbevågenhed for at bestemme relationerne mellem tokens eller ord.
Trin 3: Integreringer oprettes – Outputtet fra koderen er en samling vektorer (numeriske matrixer med flere værdier), hvor hvert element i vektoren repræsenterer en semantisk attribut for tokens. Disse vektorer kaldes integreringer. De er numeriske repræsentationer, der henter betydning:
- hund [10,3,2] - dyr, kæledyr, emne
- kat [10,3,1] - dyr, kæledyr, forskellige arter
- hvalp [5,2,1] - unge dyr, relateret til hund
- skateboard [-3,3,2] - objekt, ikke relateret til dyr
Trin 4: Dekoder (skriveren) – Dekoderblokken fungerer på en ny sekvens af teksttokens og bruger de integreringer, der genereres af koderen, til at generere et passende naturligt sprogoutput. Den sammenligner indstillingerne og vælger det mest relevante svar.
Trin 5: Output genereret – På grund af en inputsekvens som
When my dog was, kan modellen bruge selvbevågenhedsmekanismen til at analysere inputtokens og semantiske attributter, der er kodet i integreringerne, for at forudsige en passende fuldførelse af sætningen, f.eksa puppy. .
Denne arkitektur er meget parallel, hvilket gør den effektiv til oplæring i store datasæt. Størrelsen af LLM, der ofte defineres af antallet af parametre, bestemmer dens kapacitet til at lagre sproglig viden og udføre komplekse opgaver. Tænk på parametre som millioner eller milliarder af små hukommelsesceller, der gemmer sprogregler og -mønstre. Flere hukommelsesceller betyder, at modellen kan huske mere om sprog og håndtere sværere opgaver. Store modeller, f.eks. GPT-3 og GPT-4, indeholder milliarder af parametre, hvilket giver dem mulighed for at gemme omfattende sprogkendskab.
Forstå vigtigheden af prompten
Prompts er de indledende input, der gives til CHAT'er for at vejlede deres svar. Det er lederen, der får alle fire LLM-komponenter (prompt, tokenizer, model, output) til at arbejde effektivt sammen. Promptens kvalitet og klarhed har stor indflydelse på modellens ydeevne, og en velstruktureret prompt kan føre til mere nøjagtige og relevante svar.
Effektiv udformning af prompts er afgørende for at opnå det ønskede output fra modellen. Prompts kan variere fra enkle instruktioner til komplekse forespørgsler, og modellen genererer tekst baseret på konteksten og oplysningerne i prompten.
En prompt kan f.eks. være:
Translate the following English text to French: "Hello, how are you?"
Ud over standardprompts omfatter teknikker som hurtig engineering finjustering og optimering af prompts for at forbedre modellens output til bestemte opgaver eller programmer.
Et eksempel på prompt engineering, hvor der er angivet mere detaljerede instruktioner:
Generate a creative story about a time-traveling scientist who discovers a new planet. Include elements of adventure and mystery.
Interaktionen mellem opgaver, tokenisering, modellen og prompts er det, der gør VM'er så effektive og alsidige. Modellens evne til at udføre forskellige opgaver forbedres, når du har effektiv tokenisering, hvilket sikrer, at tekstinput behandles præcist. Den transformerbaserede arkitektur gør det muligt for modellen at forstå og generere tekst baseret på de tokens og den kontekst, der leveres af prompterne.