GitHub Copilot Store sprogmodeller (LLMs)
GitHub Copilot er drevet af STORE sprogmodeller (LLMs), så du nemt kan skrive kode. I dette undermodul fokuserer vi på at forstå integrationen og virkningen af LLM'er i GitHub Copilot. Lad os gennemgå følgende emner:
- Hvad er LLMs?
- Rolle som LLMs i GitHub Copilot og prompt
- Finjustering af CHAT'er
- Finjustering af LoRA
Hvad er LLMs?
Store sprogmodeller (LLMs) er modeller til kunstig intelligens, der er designet og oplært til at forstå, generere og manipulere menneskeligt sprog. Disse modeller er indgroet med mulighed for at håndtere en lang række opgaver, der involverer tekst, takket være den omfattende mængde tekstdata, de er oplært i. Her er nogle centrale aspekter, du kan bruge til at forstå om CHAT'er:
Mængden af oplæringsdata
LLMs er udsat for store mængder tekst fra forskellige kilder. Denne eksponering udstyrer dem med en bred forståelse af sprog, kontekst og snørklede involveret i forskellige former for kommunikation.
Kontekstafhængig forståelse
De udmærker sig ved at generere kontekstafhængigt relevant og sammenhængende tekst. Deres evne til at forstå kontekst giver dem mulighed for at yde meningsfulde bidrag, uanset om de fuldfører sætninger, afsnit eller endda genererer hele dokumenter, der er passende i kontekst.
Maskinel indlæring og AI-integration
LLMs er baseret på principper for maskinel indlæring og kunstig intelligens. De er neurale netværk med millioner eller endda milliarder af parametre, der er finjusteret under træningsprocessen for at forstå og forudsige tekst effektivt.
Alsidighed
Disse modeller er ikke begrænset til en bestemt type tekst eller sprog. De kan tilpasses og finjusteres til at udføre specialiserede opgaver, hvilket gør dem yderst alsidige og anvendelige på tværs af forskellige domæner og sprog.
Rolle af LLMs i GitHub Copilot og prompting
GitHub Copilot bruger LLMs til at levere kontekstbevidste kodeforslag. LLM overvejer ikke kun den aktuelle fil, men også andre åbne filer og faner i IDE'en for at generere nøjagtige og relevante kodefuldførelser. Denne dynamiske tilgang sikrer skræddersyede forslag og forbedrer din produktivitet.
Finjustering af CHAT'er
Finjustering er en kritisk proces, der giver os mulighed for at skræddersy forudtrænede store sprogmodeller (LLMs) til bestemte opgaver eller domæner. Det omfatter oplæring af modellen i et mindre, opgavespecifikt datasæt, der kaldes måldatasættet, samtidig med at du bruger den viden og de parametre, der opnås fra et stort forududlært datasæt, der kaldes kildemodellen.
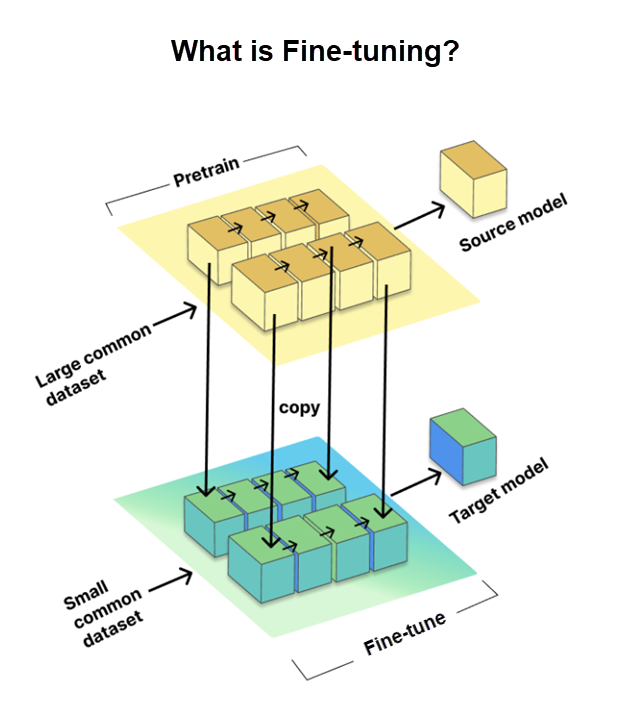
Finjustering er afgørende for at tilpasse VM'er til specifikke opgaver og forbedre deres ydeevne. GitHub tog det dog et skridt videre ved hjælp af Den Finjusteringsmetode i LoRA, som vi diskuterer næste gang.
Finjustering af LoRA
Traditionel fuld finjustering betyder at oplære alle dele af et neuralt netværk, som kan være langsom og stærkt afhængig af ressourcer. Men LoRA (Low-Rank Adaptation) finjustering er et smart alternativ. Den bruges til at få store førskolede sprogmodeller (LLMs) til at fungere bedre i forbindelse med bestemte opgaver uden at gentage al oplæring.
Sådan fungerer LoRA:
- LoRA føjer mindre dele, der kan oplæres, til hvert lag af den forudtrænede model i stedet for at ændre alt.
- Den oprindelige model forbliver den samme, hvilket sparer tid og ressourcer.
Hvad er godt ved LoRA:
- Det slår andre tilpasningsmetoder som adaptere og præfiksjustering.
- Det er som at få gode resultater med færre bevægelige dele.
Kort og godt handler Finjustering i LoRA om at arbejde smartere, ikke sværere, for at gøre VM'er bedre til dine specifikke kodningskrav, når du bruger Copilot.