Introduktion til Azure Database til PostgreSQL
Azure Database til PostgreSQL er tilgængelig i versioner med flere servere.
Som databaseudvikler med mange års erfaring med at køre og administrere PostgreSQL-installationer i det lokale miljø vil du gerne udforske, hvordan Azure Database til PostgreSQL understøtter og skalerer dens funktioner.
I dette undermodul skal du udforske indstillingerne for prisfastsættelse, versionsstøtte, replikering og skalering af Azure Database til PostgreSQL.
Azure Database for PostgreSQL
Azure Database for PostgreSQL-tjenesten er en implementering af communityversionen af PostgreSQL. Tjenesten leverer de almindelige funktioner, der bruges af typiske PostgreSQL-systemer, herunder geo-spatial support og fuldtekstsøgning.
Microsoft har tilpasset PostgreSQL til Azure-platformen og er tæt integreret med mange Azure-tjenester. Azure Database for PostgreSQL-tjenesten administreres fuldt ud af Microsoft. Microsoft håndterer opdateringer og programrettelser til softwaren og leverer en SLA på 99,99% tilgængelighed. Det betyder, at du kun kan fokusere på de databaser og programmer, der kører, ved hjælp af tjenesten.
Du kan installere flere databaser i hver forekomst af denne tjeneste.
Prisniveauer
Når du opretter en forekomst af Azure Database for PostgreSQL-tjenesten, angiver du de beregnings- og lagerressourcer, du vil tildele, ved at vælge et prisniveau. Et prisniveau kombinerer antallet af virtuelle processorkerner, mængden af tilgængelig lagerplads og forskellige muligheder for sikkerhedskopiering. Jo flere ressourcer du allokerer, jo højere omkostninger.
Azure Database for PostgreSQL-tjenesten bruger lagerplads til at opbevare dine databasefiler, midlertidige filer, transaktionslogge og serverlogge. Du kan eventuelt angive, at det tilgængelige lager skal øges, når du kommer tæt på den aktuelle kapacitet. Hvis du ikke vælger denne indstilling, vil servere, der løber tør for lagerplads, fortsætte med at køre, men fungerer som skrivebeskyttet.
Azure Portal grupperer prisniveauer i tre brede områder:
- Basic, som er velegnet til små systemer og udviklingsmiljøer, men som har variabel I/O-ydeevne.
- Generelle formål, som giver forudsigelig ydeevne, op til 6000 IOPS, afhængigt af antallet af processorkerner og den tilgængelige lagerplads.
- Hukommelse optimeret, som bruger op til 32 hukommelsesoptimerede virtuelle processorkerner, og som også giver en forudsigelig ydeevne på op til 6000 IOPS.
Microsoft har også en store lager mulighed som prøveversion, som kan klargøre op til 16 TB lagerplads og understøtte op til 20.000 IOPS.
Du kan finjustere antallet af processorkerner og det lager, du har brug for. Du kan skalere behandlingsressourcerne op og ned – du kan ikke skalere lager ned, kun op – og skifte mellem prisniveauerne Generelt formål og Hukommelsesoptimeret efter behov, når du har oprettet dine databaser. Du betaler kun for det, du har brug for.

Seddel
Hvis du ændrer antallet af processorkerner, opretter Azure en ny server med denne beregningsallokering. Når serveren kører, skiftes klientforbindelserne til den nye server. Denne kontakt kan tage op til et minut. I løbet af dette interval kan der ikke oprettes nye forbindelser, og alle transaktioner under flyvningen annulleres.
Hvis du kun ændrer lagerstørrelsen for sikkerhedskopieringsindstillinger, er der ingen afbrydelser i tjenesten.
Prisniveauet og de tildelte behandlingsressourcer bestemmer det maksimale antal samtidige forbindelser, som tjenesten understøtter. Hvis du f.eks. vælger prisniveauet Generelt og tildeler 64 virtuelle kerner, understøtter tjenesten 1900 samtidige forbindelser. Det grundlæggende niveau med to virtuelle kerner håndterer op til 100 samtidige forbindelser. Azure selv kræver fem af disse forbindelser for at overvåge serveren. Hvis du overskrider antallet af tilgængelige forbindelser, får klienterne vist fejlen FATAL: Beklager, men der er allerede for mange klienter, der.
Priserne kan ændre sig. Besøg siden med Azure Database for PostgreSQL-priser for at få de nyeste oplysninger.
Serverparametre
I en installation i det lokale miljø af PostgreSQL angiver du parametre for serverkonfiguration i filen postgresql.conf. Brug Azure Database til PostgreSQL til at ændre konfigurationsparametre via Server-parametrene side. Det er ikke alle parametre for en installation i det lokale miljø af PostgreSQL, der er relevante for Azure Database for PostgreSQL, så siden Serverparametre viser kun de parametre, der er relevante for Azure.

Ændringer af parametre, der er markeret som Dynamisk træde i kraft med det samme. Statiske parametre kræver, at serveren genstartes. Du genstarter serveren ved hjælp af knappen Genstart på siden oversigt over på portalen:

Høj tilgængelighed
Azure Database for PostgreSQL er en tjeneste, der er meget tilgængelig. Den indeholder indbygget fejlregistrering og failovermekanismer. Hvis en behandlingsnode går i stå på grund af et hardware- eller softwareproblem, skiftes der en ny node ind for at erstatte den. Alle forbindelser, der i øjeblikket bruger den pågældende node, fjernes, men åbnes automatisk i forhold til den nye node. Alle transaktioner, der udføres af noden med fejl, annulleres. Derfor skal du altid sikre dig, at klienter er konfigureret til at registrere og forsøge at udføre mislykkede handlinger igen.
Understøttede PostgreSQL-versioner
Azure Database for PostgreSQL-tjenesten understøtter i øjeblikket PostgreSQL version 11, tilbage til version 9.5. Du angiver, hvilken version af PostgreSQL der skal bruges, når du opretter en forekomst af tjenesten. Microsoft tilstræber at opdatere tjenesten, efterhånden som nye versioner af PostgreSQL bliver tilgængelige og bevarer kompatibilitet med de to tidligere overordnede versioner.
Azure administrerer automatisk opgraderinger til dine databaser mellem underordnede versioner af PostgreSQL – men ikke overordnede versioner. Hvis du f.eks. har en database, der bruger PostgreSQL version 10, kan Azure automatisk opgradere databasen til version 10.1. Hvis du vil skifte til version 11, skal du eksportere dine data fra databaserne i den aktuelle tjenesteforekomst, oprette en ny forekomst af Azure Database til PostgreSQL-tjenesten og importere dine data til denne nye forekomst.
Koordinator- og medarbejdernoder
Data fordeles og fordeles mellem arbejdsnoder. Forespørgselsprogrammet i koordinatoren kan parallelisere komplekse forespørgsler og dirigere behandlingen mod de relevante medarbejdernoder. Medarbejdernoder vælges i henhold til, hvilke skår der indeholder de data, der behandles. Koordinatoren akkumulerer derefter resultaterne fra medarbejdernoderne, før de sendes tilbage til klienten. Der kan udføres mere enkle forespørgsler kun ved hjælp af en enkelt arbejdernode. Klienter opretter også forbindelse til koordinatoren og kommunikerer aldrig direkte med en arbejdernode.
Du kan skalere antallet af medarbejdernoder op og ned i tjenesten efter behov.
Distribution af data
Du distribuerer data på tværs af arbejdsnoder ved at oprette distribuerede tabeller. En distribueret tabel opdeles i skår, og hvert skår allokeres til lagring på en arbejdernode. Du angiver, hvordan du opdeler dataene ved at definere en kolonne som den distribution kolonne. Dataene er beskåret på baggrund af værdierne af dataene i denne kolonne. Når du designer en distribueret tabel, er det vigtigt at vælge distributionskolonnen omhyggeligt. Du bør bruge en kolonne med et stort antal entydige værdier, der typisk bruges til at gruppere relaterede rækker. I en tabel for et e-handelssystem, der gemmer oplysninger om kundernes ordrer, kan kunde-id'et f.eks. være en rimelig distributionskolonne. Alle ordrer for en given kunde vil blive holdt i samme skår, men ordrerne for alle kunder fordeles på tværs af skår.
Du kan også oprette reference tabeller. Disse tabeller indeholder opslagsdata, f.eks. navne på byer eller statuskoder. En referencetabel replikeres i sin helhed til alle arbejdsnoder. Dataene i en referencetabel skal være relativt statiske. hver ændring kræver opdatering af hver kopi af tabellen.
Endelig kan du oprette lokale tabeller. En lokal tabel er ikke afskåret, men gemmes på koordinatornoden. Brug lokale tabeller til at holde små tabeller med data, der sandsynligvis ikke er påkrævet af joinforbindelser. Eksempler omfatter navnene på brugerne og deres logonoplysninger.
Repliker data i Azure Database til PostgreSQL
Skrivebeskyttede replikaer er nyttige til håndtering af læsetunge arbejdsbelastninger. Klientforbindelser kan fordeles på tværs af replikaer, hvilket letter byrden for en enkelt forekomst af tjenesten. Hvis dine klienter er placeret i forskellige områder i verden, kan du bruge replikering på tværs af områder til at placere data tæt på hvert sæt klienter og reducere ventetiden.
Du kan også bruge replikaer som en del af en beredskabsplan for it-katastrofeberedskab. Hvis den primære server bliver utilgængelig, kan du måske stadig forbinde til en replika.
Seddel
Hvis den primære mistes eller slettes, bliver alle skrivebeskyttede replikaer i stedet læse-skrive-servere. Disse servere er dog uafhængige af hinanden, så de ændringer, der foretages af dataene på én server, kopieres ikke til de resterende servere.
Oprettelse af en replika
En skrivebeskyttet replika indeholder en kopi af de databaser, der opbevares på den oprindelige server – kaldet primæren. Du bruger Azure-portalen eller CLI til at oprette en replika af en primær.

Når du opretter en skrivebeskyttet replika, opretter Azure en ny instans af Azure Database for PostgreSQL-tjenesten og kopierer derefter databaserne fra den primære server til den nye server. Replikaen kører i skrivebeskyttet tilstand. Ethvert forsøg på at ændre data mislykkes.
Replikaforsinkelse
Replikering er ikke synkron, og eventuelle ændringer i data på den primære server kan tage noget tid at dukke op i replikaerne. Klientprogrammer, der opretter forbindelse til replikaer, skal kunne håndtere dette niveau af ensartethed. Azure Monitor giver dig mulighed for at spore tidsforsinkelsen i replikering ved hjælp af maks. mellemliggende lag på tværs af replikaer og replikaforsinkelse målepunkter.
Administration og overvågning
Du kan bruge velkendte værktøjer som f.eks. pgAdmin- til at oprette forbindelse til Azure Database til PostgreSQL for at administrere og overvåge dine databaser. Nogle serverfokuserede funktioner, f.eks. sikkerhedskopiering og gendannelse af serveren, er dog ikke tilgængelige, fordi serveren administreres og vedligeholdes af Microsoft.

Azure-værktøjer til overvågning af Azure Database for PostgreSQL
Azure leverer et omfattende sæt tjenester, som du bruger til at overvåge serverens og databasens ydeevne og foretage fejlfinding af problemer. Disse tjenester giver dig mulighed for at se, hvordan PostgreSQL bruger de Azure-ressourcer, du har allokeret. Du kan bruge disse oplysninger til at vurdere, om du har brug for at skalere dit system, ændre strukturen af tabeller og indekser i dine databaser og visualisere kørselsstatistik og andre hændelser. De tilgængelige tjenester omfatter:
Azure Monitor. Azure Database for PostgreSQL indeholder målepunkter, der gør det muligt for dig at spore elementer, f.eks. CPU- og lagerudnyttelse, I/O-satser, hukommelsesforbrug, antallet af aktive forbindelser og replikeringsforsinkelse:
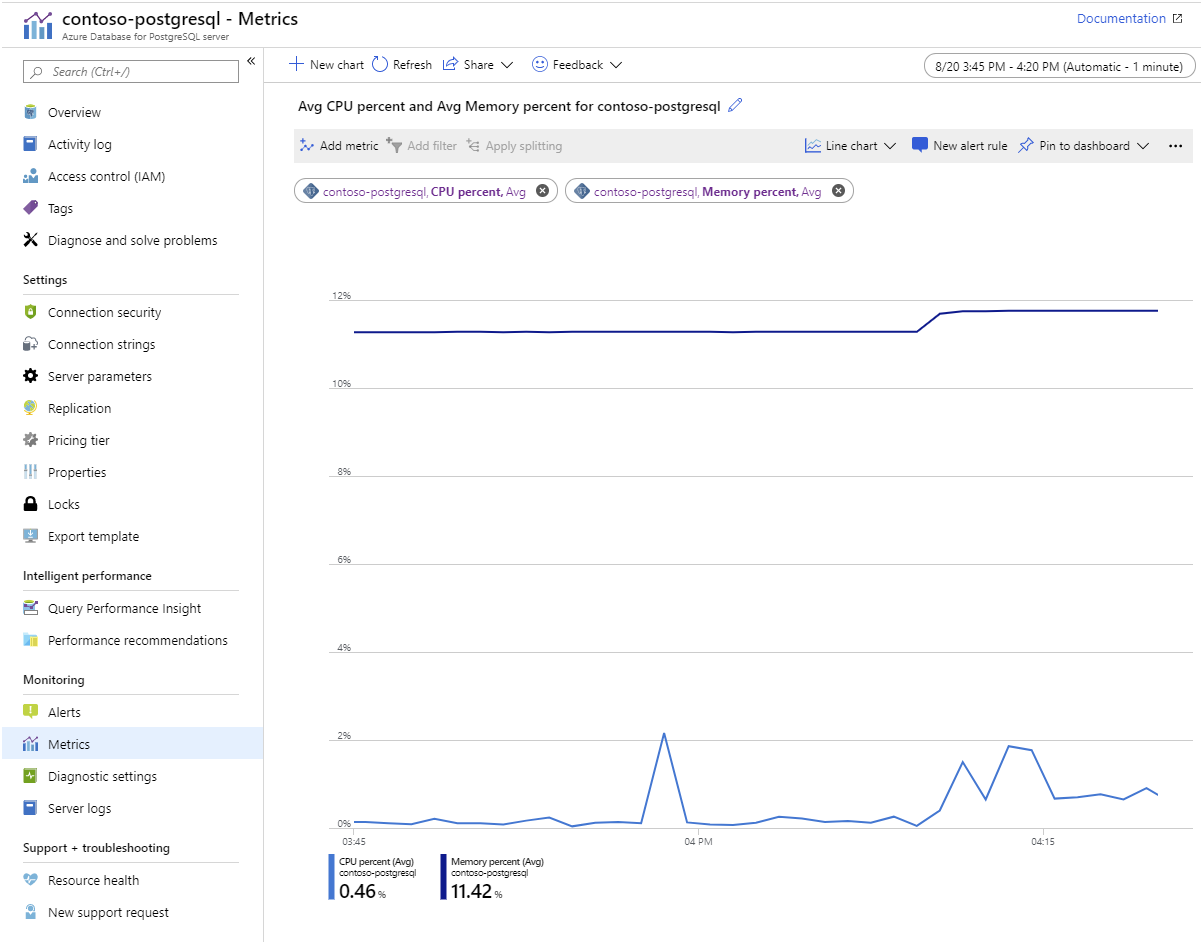
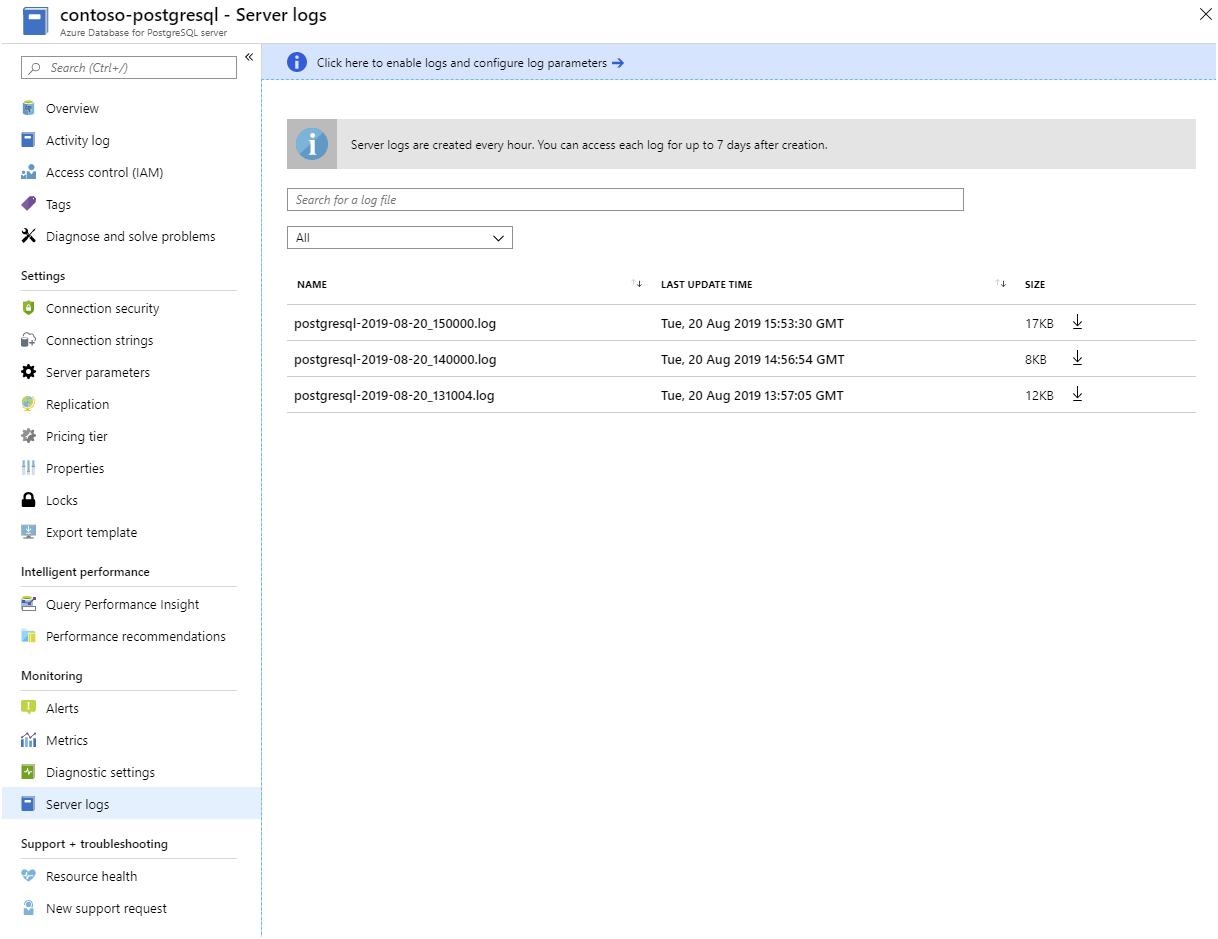
Serverlogge. Azure gør loggene tilgængelige for hver PostgreSQL-server. Du downloader dem fra Azure Portal:
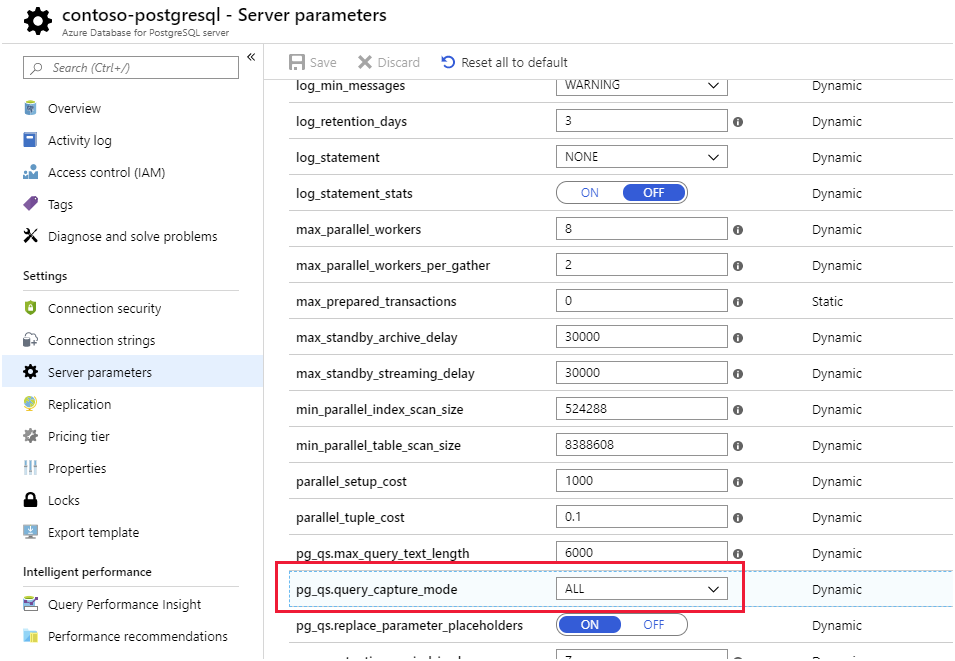
Query Store og Query Performance Insights. Azure Database for PostgreSQL gemmer oplysninger om de forespørgsler, der kører på databaser på serveren, og gemmer dem i en database med navnet azure_sysi skemaet query_store. Du forespørger visningen query_store.qs_view for at få vist disse oplysninger. Azure Database til PostgreSQL henter som standard ingen forespørgselsoplysninger, da det medfører en lille belastning, men du kan aktivere sporing ved at angive serveregenskaben pg_qs.query_capture_mode til at ALLE eller TOP-.
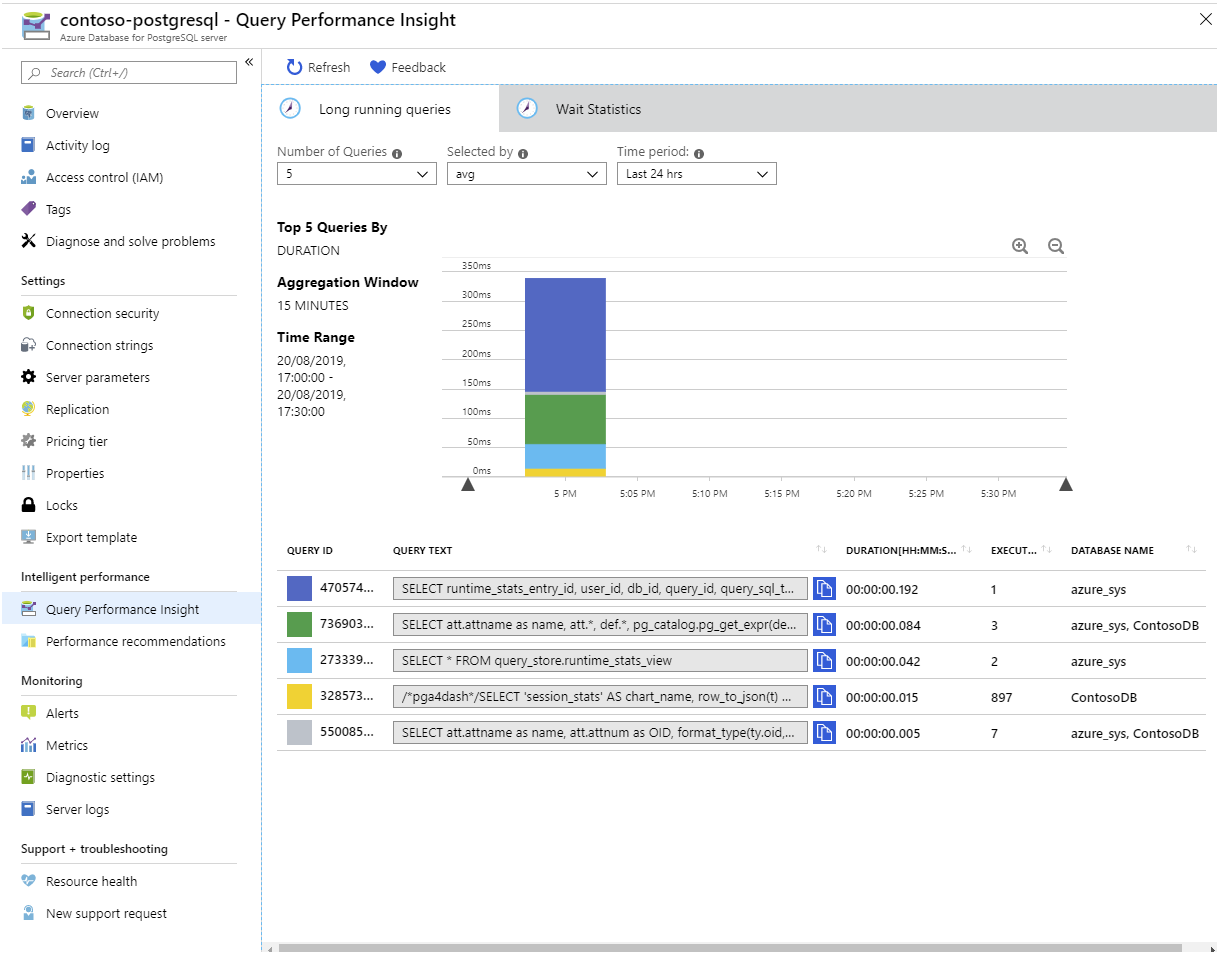
Du kan også konfigurere Forespørgselslager til at hente oplysninger om forespørgsler, der bruger tid på at vente. En forespørgsel skal muligvis vente, mens en anden forespørgsel frigiver en lås på en tabel, eller fordi forespørgslen udfører en masse I/O, eller fordi hukommelsen er ved at løbe tør for hukommelse. Du kan se disse oplysninger i query_store.runtime_stats_view visning.
Hvis du foretrækker at visualisere disse statistikker i stedet for at køre SQL-sætninger, skal du bruge Indsigt i forespørgselsydeevne på Azure Portal:
ydeevneanbefalinger. Værktøjet Ydeevneanbefalinger, der også er tilgængeligt på Azure Portal, undersøger de forespørgsler, dine programmer kører. Den ser også på strukturerne i databasen og anbefaler, hvordan du organiserer dine data– og om du bør overveje at tilføje eller fjerne indekser.




Klientforbindelse
Azure Database for PostgreSQL kører bag en firewall. Hvis du vil have adgang til tjenesten og databasen, skal du tilføje en firewallregel for de IP-adresseområder, som klienterne opretter forbindelse fra. Hvis du har brug for at få adgang til tjenesten fra Azure – f.eks. et program, der kører ved hjælp af Azure App Services – skal du også aktivere adgang til Azure-tjenester.
Konfigurer firewallen
Den nemmeste måde at konfigurere firewallen på er ved at bruge indstillingerne for forbindelsessikkerhed for din tjeneste på Azure Portal. Tilføj en regel for hvert klient-IP-adresseområde. Du kan også bruge denne side til at gennemtvinge SSL-forbindelser til din tjeneste.

Du klikker Tilføj klient-IP- på værktøjslinjen for at tilføje IP-adressen på din stationære computer.
Hvis du har konfigureret skrivebeskyttede replikaer, skal du føje en firewallregel til hver enkelt for at gøre dem tilgængelige for klienter.
Klientforbindelsesbiblioteker
Hvis du skriver dine egne klientprogrammer, skal du bruge den relevante databasedriver til at oprette forbindelse til en PostgreSQL-database. Mange af disse biblioteker er afhængige af programmeringssprog. De vedligeholdes af uafhængige tredjeparter. Azure Database til PostgreSQL understøtter klientbiblioteker til Python, PHP, Node.js, Java, Ruby, Go, C# (.NET), ODBC, C og C++.
Klientforsøgslogik
Som tidligere nævnt kan nogle hændelser – f.eks. failover under genoprettelse med høj tilgængelighed og opskalering af CPU-ressourcerne – medføre et kort tab af forbindelsen. Alle igangværende transaktioner annulleres. Azure Database til PostgreSQL omdirigerer automatisk en tilsluttet klient til en arbejdsnode, men alle handlinger, der udføres af klienten på det pågældende tidspunkt, returnerer en fejl. Du skal behandle denne forekomst som en forbigående undtagelse. Programkoden skal være forberedt på at fange disse undtagelser og prøve dem igen.
PostgreSQL-funktioner, der understøttes i Azure Database til PostgreSQL
Azure Database til PostgreSQL understøtter de fleste funktioner, der ofte bruges af PostgreSQL-databaser, men der er nogle undtagelser. Hvis du har brug for en funktion, der ikke understøttes, skal du enten omarbejde databasen og programkoden for at fjerne denne afhængighed eller overveje at køre PostgreSQL på en virtuel maskine. I sidstnævnte tilfælde skal du tage ansvar for at administrere og vedligeholde serveren.
Understøttede udvidelser i Azure Database til PostgreSQL
Meget PostgreSQL-funktionalitet er indkapslet i udvidelser. Udvidelser er pakker med SQL-objekter og kode, der er gemt på serveren – de kan indlæses i en database ved hjælp af kommandoen CREATE EXTENSION. Azure Database til PostgreSQL indeholder i øjeblikket mange almindeligt anvendte udvidelser til:
- Datatyper
- Functions
- Fuldtekstsøgning
- Indekser (bloom, btree_gist og btree_gin)
- Plpgsql-sproget
- PostGIS
- Mange administrative funktioner
Du kan bruge dblink- og postgres_fdw pakker til at forbinde én PostgreSQL-server med en anden – dette gør det muligt for kode på én server at få adgang til data, der opbevares på en anden. I Azure Database til PostgreSQL kan du kun oprette forbindelse mellem servere, der er oprettet ved hjælp af Azure Database til PostgreSQL. Du kan ikke oprette udgående forbindelser til PostgreSQL-servere, der hostes et andet sted, f.eks. i det lokale miljø eller på en virtuel maskine.
Seddel
Listen over understøttede udvidelser gennemgås løbende og kan ændres. Du skal generere en liste over de udvidelser, der understøttes med følgende forespørgsel. Bemærk, at du ikke kan oprette dine egne brugerdefinerede udvidelser og uploade dem til Azure Database for PostgreSQL:
SELECT * FROM pg_available_extensions;
Azure Database til PostgreSQL indeholder databasen TimescaleDB som en valgfri udvidelse. Denne database indeholder tidsorienterede analysefunktioner og andre funktioner, der understøtter tidsseriearbejdsbelastninger. Hvis du vil bruge denne database, skal du vælge indstillingen TIMESCALEDB i parameteren shared_preload_libraries server og derefter genstarte serveren.
Sprogunderstøttelse af lagrede procedurer og udløsere
Understøttelse af andre sprog end plpgsql kræver typisk, at du kompilerer din lagrede procedure eller udløserkode separat og uploader det kompilerede bibliotek til serveren. Hovedsageligt af sikkerhedsmæssige årsager kan du ikke gøre dette med Azure Database for PostgreSQL. Hvis du har kode, der er skrevet på andre sprog, skal du overføre den til plpgsql.