Forankr din model med Retrieval Augmented Generation
Prompt engineering hjælper med at styre, hvordan en model reagerer, men den kan ikke give den modelviden, den ikke allerede har. Sprogmodeller trænes på store datasæt, men disse træningsdata har en cutoff-dato og inkluderer ikke din organisations private oplysninger. Når en model mangler relevant kontekst, kan den generere svar, der lyder plausible, men som er faktuelt forkerte.
For at imødekomme denne udfordring kan du forankre modellen ved at give den relevante, faktuelle data til at basere sine svar på. Retrieval Augmented Generation (RAG) er den mest almindelige teknik til at forankre en sprogmodel.
Forstå jordforbindelse
Når du bruger en sprogmodel uden jordforbindelse, kommer den eneste information, den har, fra dens træningsdata. Resultatet kan være grammatisk korrekt og logisk struktureret, men det kan være unøjagtigt eller indeholde fabrikerede detaljer. For eksempel kan et spørgsmål "Hvilke hoteller tilbyder I i Paris?" uden jordingsdata give fiktive hotelnavne.
Når du grounder en prompt, leverer du relevante data fra en betroet kilde sammen med brugerens spørgsmål. Modellen genererer derefter et svar baseret på disse data, hvilket giver mere præcise og kontekstuelt relevante svar.
Overvej forskellen:
- Ujordet: Modellen er kun afhængig af sine træningsdata og kan opfinde hotelnavne eller detaljer.
- Jordet: Modellen modtager dine faktiske hotelkatalogdata som kontekst og svarer med rigtige hotelnavne, priser og tilgængelighed.
Grounding forbedrer den faktiske nøjagtighed af svarene ved at forbinde modellen med information, der er specifik, aktuel og relevant for brugerens behov.
Sådan fungerer RAG
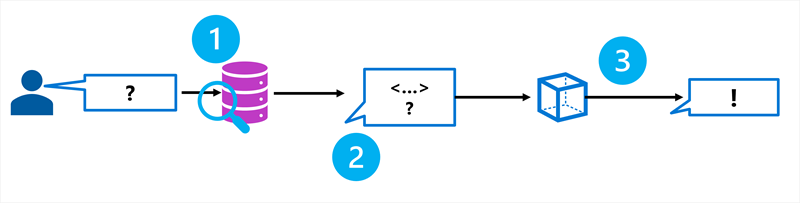
RAG er et mønster, der henter relevant information fra en datakilde og inkluderer det i prompten, før modellen genererer et svar. Processen følger tre trin:
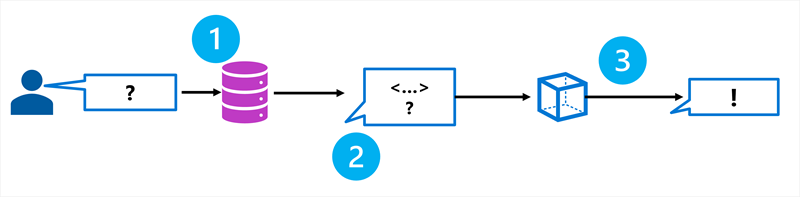
- Hent: Søg i en datakilde efter information, der er relevant for brugerens spørgsmål.
- Augment: Tilføj de hentede oplysninger til prompten som kontekst.
- Generer: Send den udvidede prompt til sprogmodellen for at generere et jordnært svar.
Ved at hente kontekst fra en specificeret datakilde sikrer du, at modellen bruger relevant, up-to-dato information i stedet for udelukkende at stole på træningsdata.
Opret embeddings til søgning
En kritisk komponent i RAG er evnen til effektivt at finde den mest relevante information i din datakilde. Her kommer embeddings og vektorsøgning ind i billedet.
En embedding er en matematisk repræsentation af tekst som en vektor — en liste af flydende kommatal, der fanger betydningen af ord, sætninger eller dokumenter. Du opretter embeddings ved at sende dit indhold til en embedding-model, såsom en Azure OpenAI-embedding-model, der findes i Microsoft Foundry.
For eksempel, forestil dig to dokumenter:
- "Børnene legede med glæde i parken"
- "Børn løb lykkeligt rundt på legepladsen."
Disse sætninger bruger forskellige ord, men har lignende betydninger. Når du skaber indlejringer for hver, ligger deres vektorer tæt sammen i flerdimensionelt rum, hvilket afspejler deres semantiske lighed.
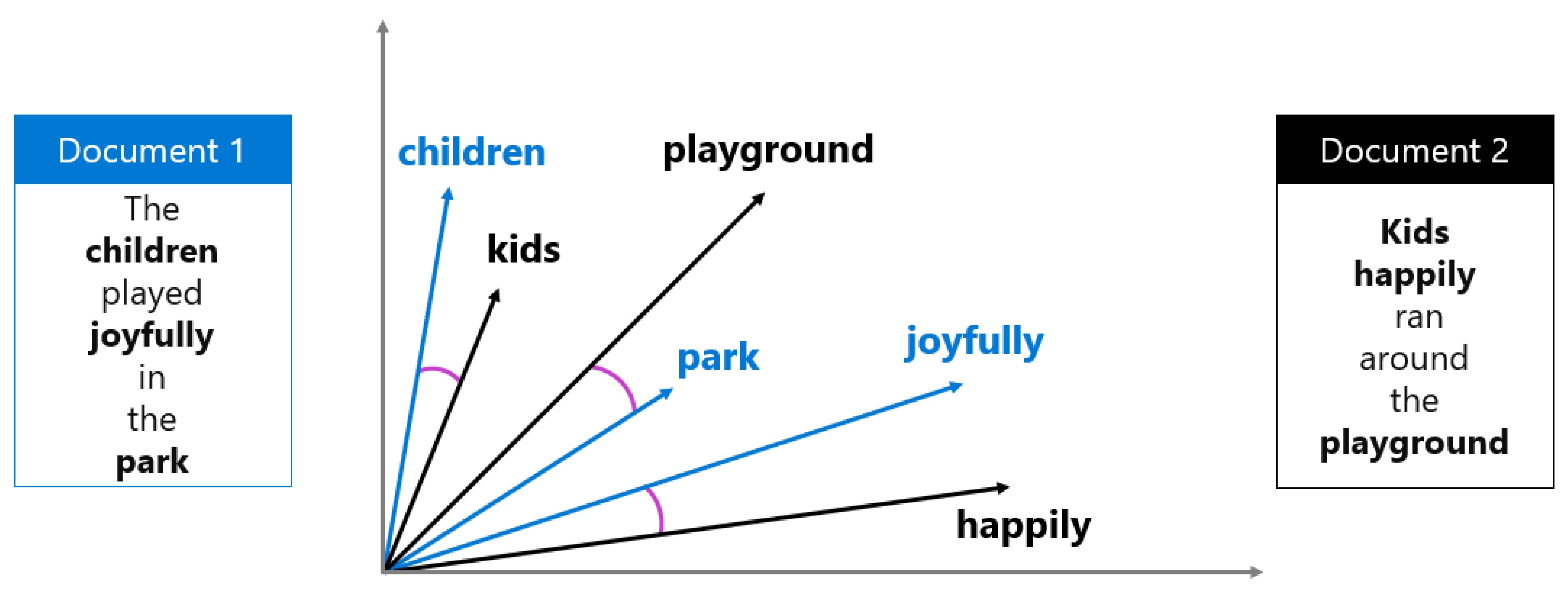
Cosinus-lighed måler, hvor tæt to vektorer er på hinanden ved at beregne vinklen mellem dem. En værdi nær 1 betyder, at vektorerne er meget ens. Denne matematiske tilgang gør det muligt for dig at finde relevante dokumenter, selv når de præcise ord ikke stemmer overens.
Brug Azure AI Search til retrieval
Azure AI Search leverer hentningskomponenten for RAG-løsninger i Microsoft Foundry. Det giver dig mulighed for at bringe dine egne data, oprette et søgbart indeks og forespørge det for at hente relevant information.
For at bruge Azure AI Search med RAG, skal du:
- Tilføj dine data til Microsoft Foundry fra kilder som Azure Blob Storage, Azure Data Lake Storage Gen2 eller Microsoft OneLake. Du kan også uploade filer direkte.
- Opret et indeks ved hjælp af en embedding-model til at generere vektorrepræsentationer af dit indhold. Indekset gemmes i Azure AI Search.
- Forespørg i indekset , når en bruger stiller et spørgsmål. Systemet konverterer spørgsmålet til en embedding, søger efter det mest lignende indhold og returnerer de relevante resultater.
Azure AI Search understøtter flere søgeteknikker:
- Søgeord: Matcher præcise termer i forespørgslen med tekst i indekset.
- Semantisk søgning: Bruger semantiske modeller til at matche betydningen af forespørgslen frem for præcise nøgleord.
- Vektorsøgning: Bruger embeddings til at finde semantisk lignende indhold.
- Hybridsøgning: Kombinerer søgeord, semantik og vektorsøgning for de mest præcise resultater. Hybridsøgning anbefales til generative AI-applikationer.
Implementér RAG med Azure AI Foundry SDK
Efter du har oprettet et Azure AI Search-indeks, kan du forbinde det til en model via dit Microsoft Foundry-projekt. SDK'en azure-ai-projects lader dig få en autentificeret OpenAI-klient og bruge Responses API'en til at generere jordnære svar.
Følgende Python-kode viser en grundlæggende implementering:
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
project = AIProjectClient(
endpoint=os.environ["PROJECT_ENDPOINT"],
credential=DefaultAzureCredential(),
)
client = project.get_openai_client()
response = client.responses.create(
model="gpt-4o",
input=[
{"role": "system", "content": "You are a helpful travel advisor. "
"Use the following hotel data to answer: " + retrieved_context},
{"role": "user", "content": "Which hotels do you offer in Paris?"},
],
)
print(response.output_text)
I dette eksempel repræsenterer retrieved_context de dokumenter, der returneres fra dit Azure AI Search-indeks. Ved at indsætte disse resultater i systembeskeden er modellens svar baseret på dine faktiske data frem for dens generelle træningsviden.
Hvornår skal man bruge RAG
RAG er mest effektivt, når:
- Modellen har brug for domænespecifik viden: Din organisation har private data, som modellen ikke er trænet på, som et produktkatalog, politikdokumenter eller interne knowledge base.
- Oplysninger ændres ofte: Dine data opdateres regelmæssigt, såsom lager, priser eller nyheder. RAG henter aktuelle data ved forespørgselstidspunktet uden gentræning.
- Faktuelle nøjagtigheder er afgørende: Du har brug for svar, der er baseret på reelle data frem for modellens generelle viden.
- Basismodellens træningsdata har en cutoff: Begivenheder eller information, der fandt sted efter modellens træningsafskæringsdato, skal være tilgængelige.
I rejsebureau-scenariet giver RAG kunderne mulighed for at stille spørgsmål om specifikke hoteller, destinationer og bookingpolitikker, alt sammen baseret på bureauets faktiske katalogdata.
Tips
Hvis du bygger agenter, der har brug for jordnær viden uden at administrere din egen søgeinfrastruktur, så overvej Foundry IQ — et managed knowledge store, der forenkler grounding for AI-agenter. For at lære mere, se Byg vidensforbedrede AI-agenter med Foundry IQ.