Indfødning af data med Azure Databricks
Før du kan arbejde med data i Azure Databricks, skal du overføre data til platformen. Når den cloudbaserede beregning er på platformen, kan du behandle store datamængder effektivt.
Data i Azure Databricks gemmes ved hjælp af Apache Delta Lake, som er et open source-system til administration af datafiler, som relationstabeller kan defineres og forespørges på. Den faktiske lagringsplacering for delta lake-filerne kan variere. Azure Databricks understøtter oprettelse af forbindelse til clouddatalagringstjenester som Azure Storage og Azure Data Lake. Azure Databricks leverer også Unity Catalog som en styringsløsning til administration og sporing af dataadgang og afstamning på tværs af flere forbundne datalagre.
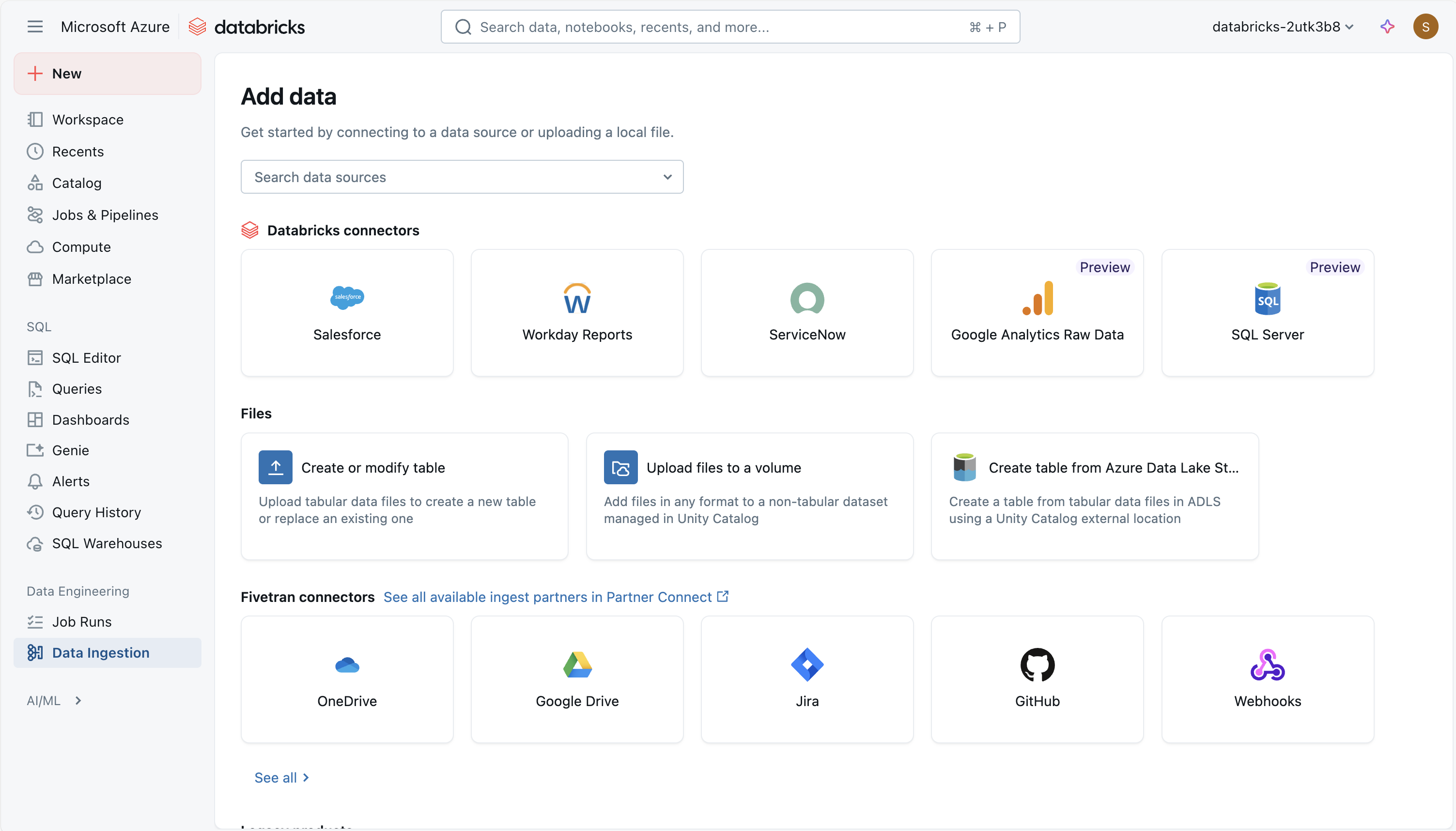
Der er flere måder at indtage data på i Azure Databricks, hvilket gør dem til et alsidigt og effektivt værktøj til dataanalyse, herunder:
Brug af en administreret Databricks-connector i Lakeflow Connect
Azure Databricks Lakeflow Connect indeholder en struktur til indtagelse af data fra SaaS-programmer, databaser og andre kilder i søhuset ved hjælp af administrerede connectorer. Disse connectorer definerer, hvordan godkendelse, pipelines og destinationstabeller konfigureres og vedligeholdes. For SaaS-kilder er de vigtigste dele en forbindelse (til godkendelse), en serveruafhængig indtagelsespipeline og Delta-tabeller , der gemmer de indtagne data. Databaseconnectorer indeholder de samme elementer, men er også afhængige af en indtagelsesgateway , der kører på klassisk beregning, og et midlertidigt lagerområde i Unity Catalog til midlertidigt at opbevare udtrukne data. Orkestrering håndteres via Databricks-job, og adgangskontrol og overvågning administreres via Unity Catalog.
Ved hjælp af administrerede connectorer kan datapipelines planlægges, prøves og skaleres igen uden at skulle skrive brugerdefineret indtagelseskode. Trinvis indtagelse understøttes, hvilket hjælper med at reducere belastningen på kildesystemer, samtidig med at tabellerne holdes opdaterede. Tilgangen lægger vægt på ensartet styring, skemahåndtering og overvågning på tværs af forskellige datakilder.
Følgende administrerede connectorer er tilgængelige:
- Google Analytics
- Salesforce
- Arbejdsdagsrapporter
- SQL Server
- ServiceNow
- SharePoint
Upload filer til Azure Databricks
Du kan importere lokale CSV-, TSV-, JSON-, XML-, AVRO-, PARQUET- eller almindelige tekstfiler til Databricks for at generere en Delta-tabel. Denne fremgangsmåde er beregnet til mindre filer (under 2 GB), der overføres direkte fra computeren. Komprimerede arkiver som ZIP eller TAR understøttes ikke. Under uploadprocessen giver Databricks en forhåndsvisning af op til 50 rækker, og du kan justere formateringsindstillingerne for at sikre, at kolonner og datatyper i CSV- eller JSON-filer genkendes korrekt.
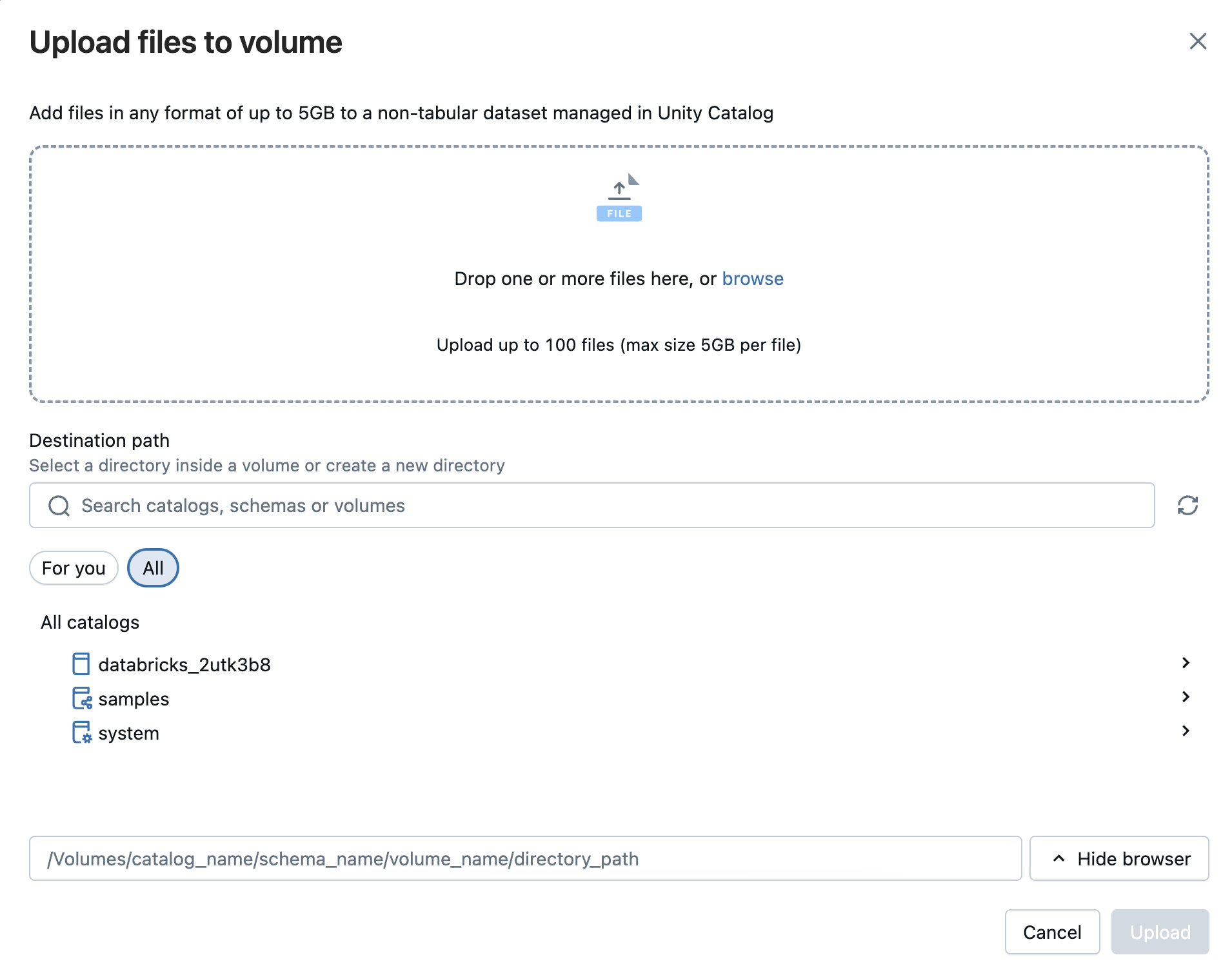
Du kan også overføre filer i et hvilket som helst format – struktureret, delvist struktureret eller ustruktureret – til en diskenhed. En diskenhed er et Unity Catalog-objekt, der giver styring af datasæt, der ikke er tabeldatasæt, og repræsenterer en logisk lagerplads i et cloudobjektlager. Diskenheder giver dig adgang til, gemmer, organiserer og anvender styring på filer. Der er to typer bind:
- Administrerede diskenheder: Databricks-administreret lager til enkle brugssager.
- Eksterne diskenheder: Styring anvendt på eksisterende lagerplaceringer for cloudobjekter.
Notat
Indstillingen DBFS giver dig mulighed for at bruge den ældre Databricks-filsystemfilupload. Dette understøttes ikke længere.
Indtag filer ved hjælp af Apache Spark API
Apache Spark er den oprindelige beregningsplatform til Azure Databricks, og den understøtter API'er til flere programmeringssprog, f.eks. Scala, Java, PySpark (en Spark-optimeret variant af Python) og SQL. Hvis du vil have en enkel dataindtagelse i fjernlageret, kan du skrive kode, der opretter forbindelse til og importerer de påkrævede data.
Her er et eksempel, hvor du bruger wget til at trække en fjernfil ind i /tmp/ på drivernoden, bruge Spark til at læse den fra den lokale sti og derefter gemme den som en Delta-tabel i Databricks:
# Step 1: Use wget to download the file (e.g., a CSV from a public URL)
# In Databricks, prefix shell commands with "!"
!wget https://<location>/airtravel.csv -O /tmp/airtravel.csv
# Step 2: Load the downloaded file into a Spark DataFrame
df = spark.read.format("csv") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:/tmp/airtravel.csv")
# Step 3: Preview the data
df.show(5)
# Step 4: Save as a Delta table
df.write.format("delta").mode("overwrite").saveAsTable("default.airtravel")
Indlæs data ved hjælp af COPY INTO med en tjenesteprincipal
Du kan bruge COPY INTO kommandoen til at indlæse data fra en Azure Data Lake Storage-objektbeholder (ADLS) på din Azure-konto i en tabel i Databricks SQL.
COPY INTO my_json_data
FROM 'abfss://container@storageAccount.dfs.core.windows.net/jsonData'
FILEFORMAT = JSON;
Lakeflow deklarative rørledninger
Lakeflow Declarative Pipelines er en deklarativ ramme til udvikling og kørsel af batch- og streamingdatapipelines i SQL og Python. Det understøtter automatiseret orkestrering, genforsøg, fejlisolering, skemaudvikling, trinvis behandling og CDC Change Data Capture type 1 og 2.
Et flow er det grundlæggende databehandlingskoncept i Lakeflow Declarative Pipelines, som understøtter både streaming- og batchsemantik. Et flow læser data fra en kilde, anvender brugerdefineret behandlingslogik og skriver resultatet til et mål.
Du kan også administrere datakvaliteten med pipelineforventninger, som giver dig mulighed for at definere valideringsregler, der sikrer, at data opfylder de påkrævede standarder, før de skrives til destinationen.
Her er et eksempel på en deklarativ pipeline:
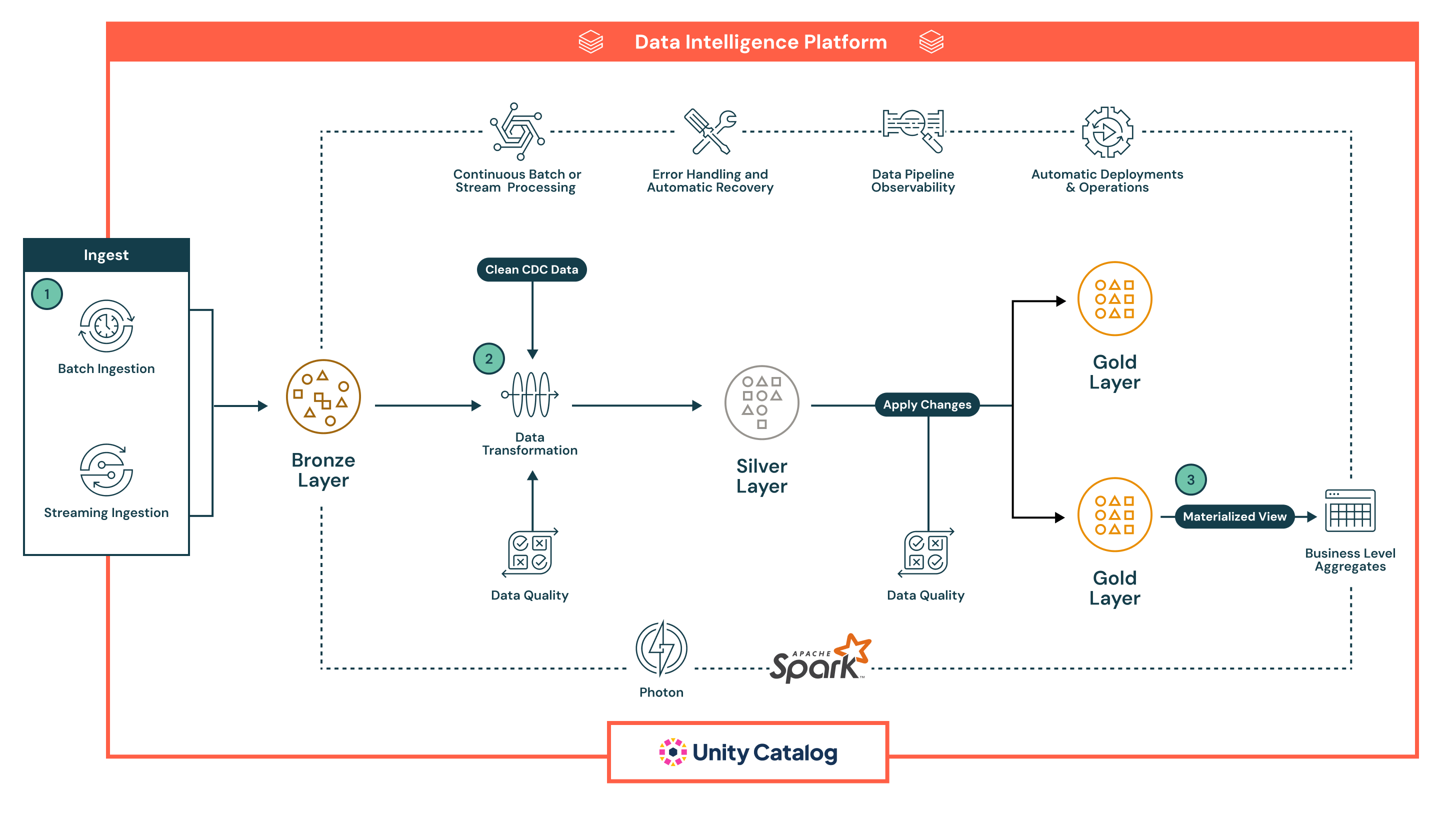
I dette eksempel lander data først i bronzelaget i rå form til afstamning og sikker oparbejdning og fortsætter derefter til sølvlaget , hvor de renses, forbedres, valideres med indbyggede kvalitetskontroller og behandles i stor skala med Spark, før de når guldlaget , som leverer organiserede, forretningsklare datasæt til BI, maskinel indlæring og avancerede use cases som historisk sporing.
Azure Data Factory
Azure Data Factory (ADF) giver dig mulighed for at kopiere data til og fra Azure Databricks Delta Lake ved hjælp af den indbyggede kopiaktivitet. Når ADF fungerer som kilde, kan den udtrække data fra Delta-tabeller i Databricks og flytte dem til understøttede modtagere. når den fungerer som en dræn, kan den indlæse data i Delta Lake-tabeller fra understøttede kilder.
Dataflytningen orkestreres ved at aktivere din Databricks-klynge for at håndtere overførslen, og ADF understøtter både Azure-integrationskørsler og selvhostede integrationskørsler afhængigt af miljøet.
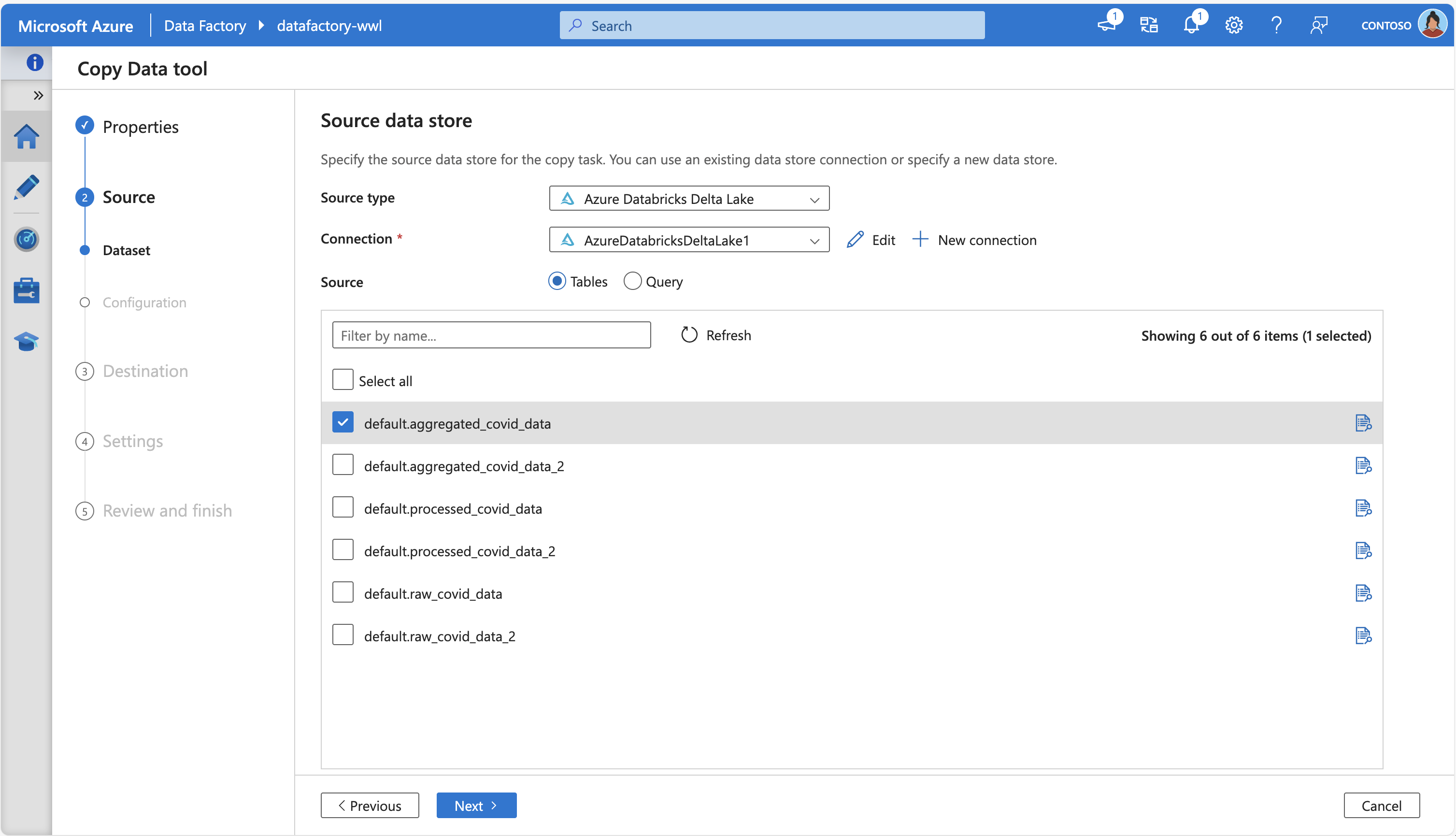
På følgende skærmbillede vises Azure Data Factory Copy Data Tool, der opretter forbindelse til Azure Databricks Delta Lake for at hente nogle kildetabeller:
Derudover tilbyder ADF's tilknytningsdataflow en kodefri ETL-oplevelse: De kan hente fra og modtage data i Delta-format på Azure Storage, hvilket muliggør transformationer uden at skrive kode, der kører på administreret Azure Integration Runtime.
Azure Event Hubs og IoT Hubs
Til dataindtagelse i realtid er Azure Event Hubs og IoT Hubs de bedst egnede valg. De giver dig mulighed for at streame data direkte i Azure Databricks, så du kan behandle og analysere data, når de modtages. Dataindtagelse og -analyse i realtid er nyttig til scenarier som overvågning af livebegivenheder eller sporing af IoT-enhedsdata (Internet of Things).
Azure Event Hubs har et Kafka-kompatibelt slutpunkt, der fungerer sammen med Kafka-connectoren til struktureret streaming i Databricks Runtime. Du kan konfigurere Lakeflow Declarative Pipelines til at oprette forbindelse til en Event Hubs-forekomst og forbruge hændelser fra et emne.