Værktøjer til dataudforskning i Azure Databricks
Når du har hentet data fra dine kilder, kan du bruge Azure Databricks-platformen til i fællesskab at udforske og analysere dine data.
Lad os udforske de værktøjer, du bruger, når du arbejder med data i Azure Databricks.
Samarbejd og kør kode med notesbøger
Du kan bruge notesbøger i Azure Databricks til at skrive Python-, SQL-, Scala- eller R-kode for at udforske og visualisere data. Notesbøger understøtter interaktiv dataudforskning og kan deles mellem teammedlemmer. Den understøtter også dataprofileringsfunktioner, så dataforskere kan forstå dataenes form og indhold.

Du kan bruge de indbyggede visualiseringer til hurtigt at forstå datadistributioner, tendenser og mønstre. Ud over de indbyggede funktioner giver Azure Databricks dig mulighed for at integrere med almindeligt anvendte biblioteker med åben kildekode, f.eks. Matplotlib, Seaborn eller D3.js for at få mere komplekse visualiseringer.
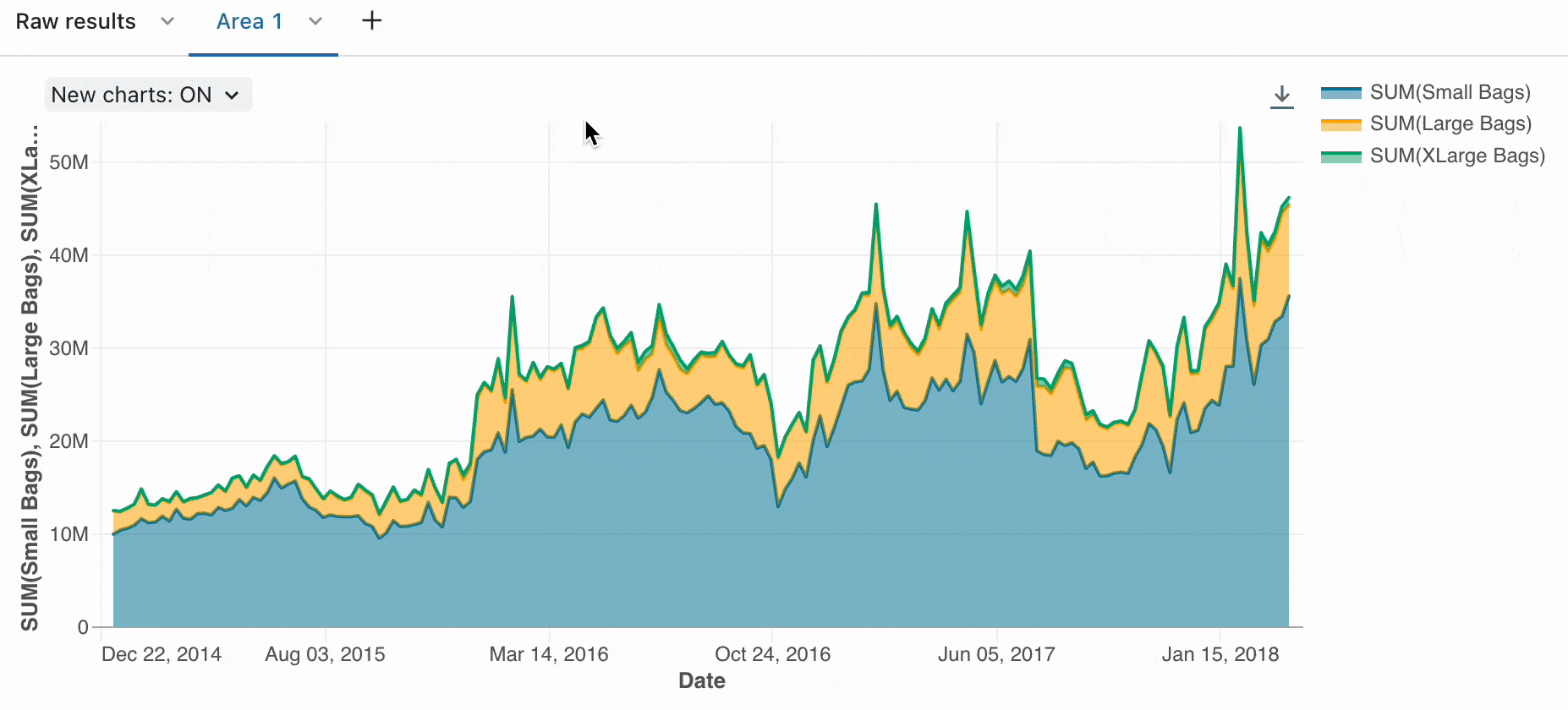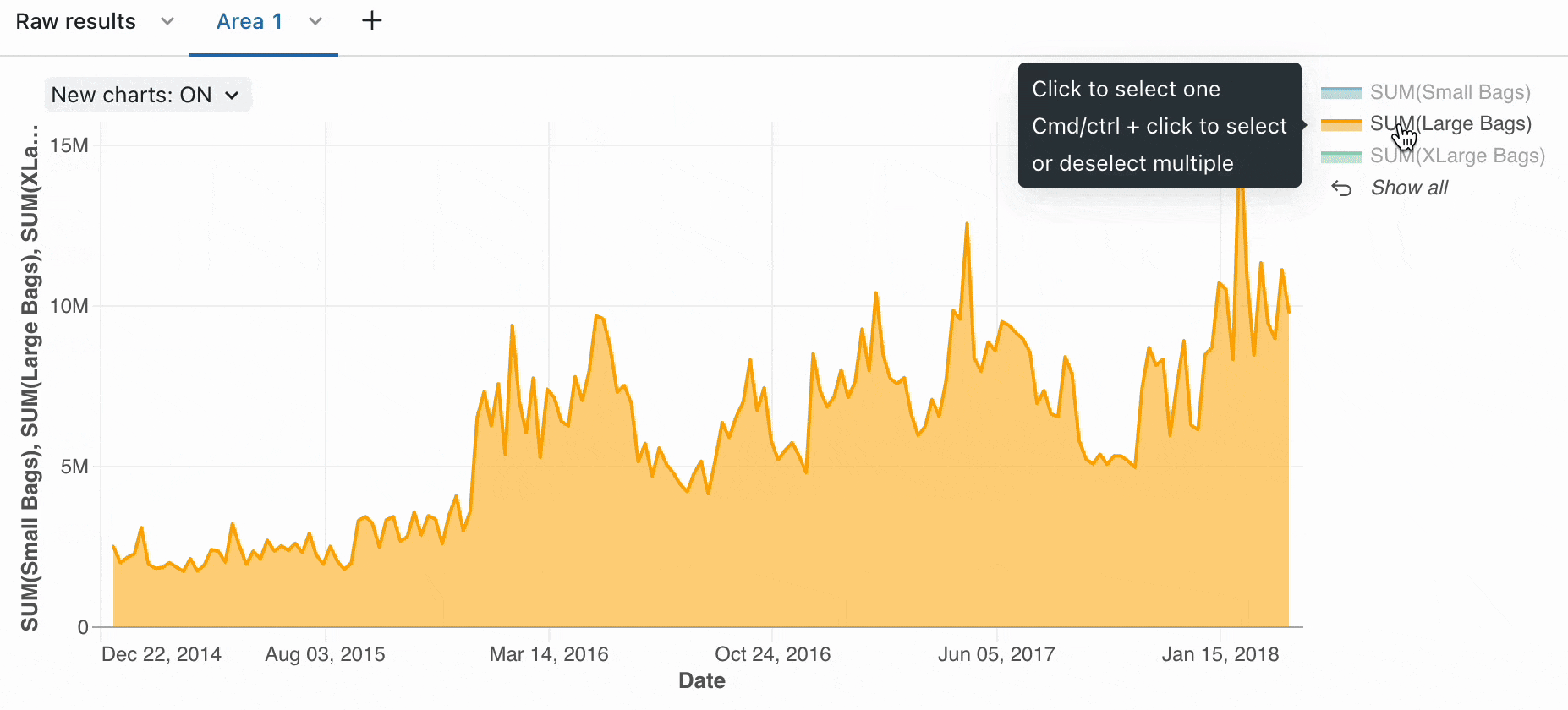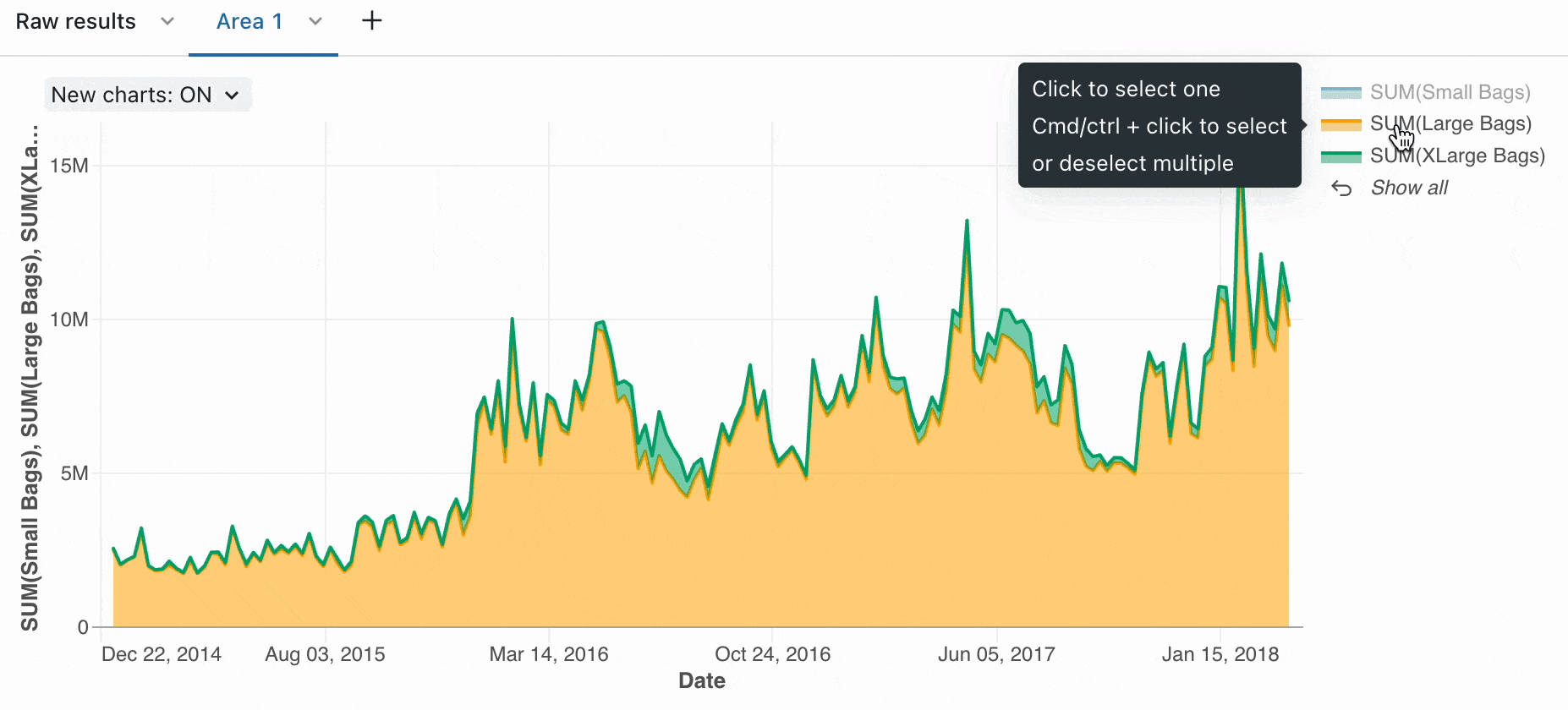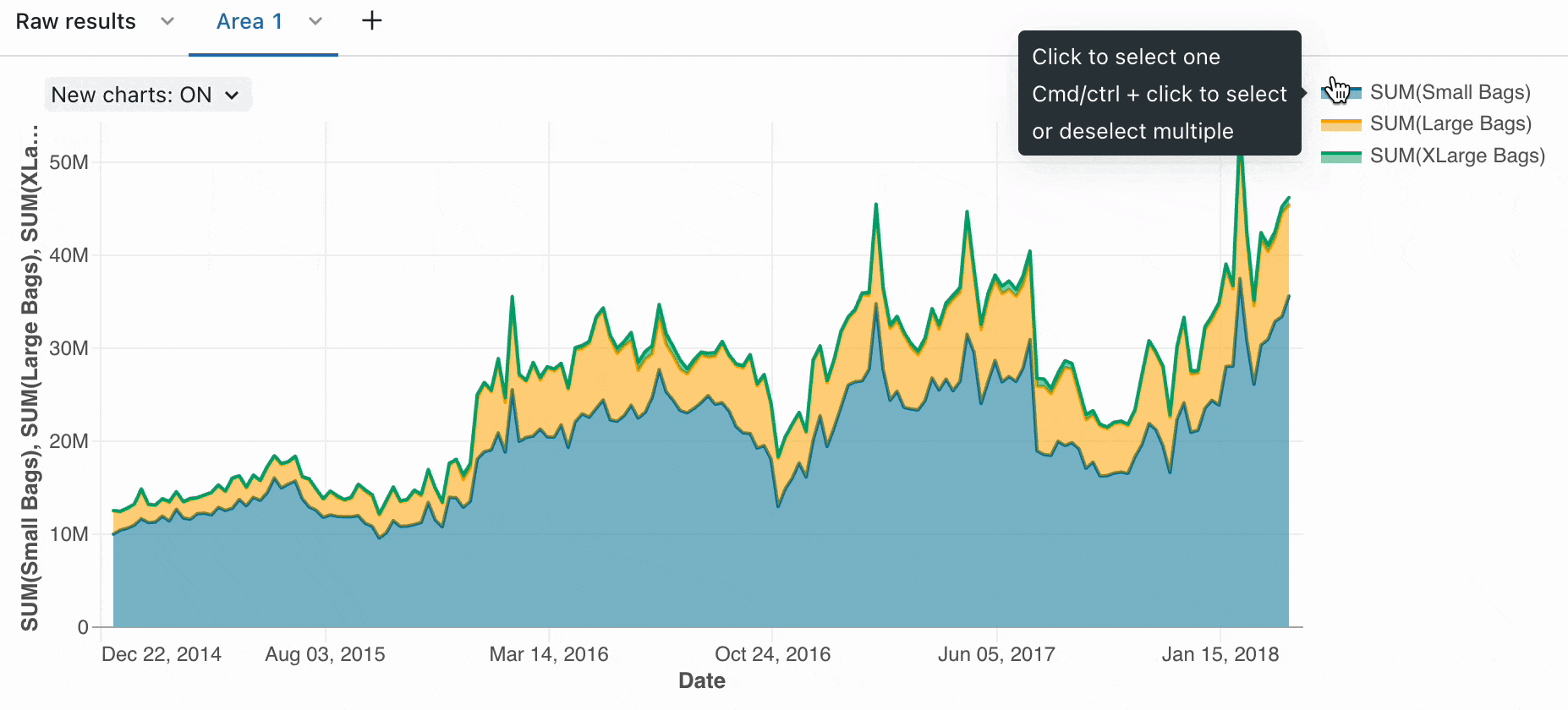
Arbejd med Spark DataFrames
Når du arbejder med data i notesbøger, bruger du Spark DataFrames , der er bygget på Apache Spark. Med DataFrames kan du manipulere store datasæt effektivt.
Hvis du f.eks. vil oprette en simpel DataFrame, kan du køre følgende kode:
data = [("Alice", 34), ("Bob", 45), ("Cathy", 29)]
columns = ["Name", "Age"]
df = spark.createDataFrame(data, columns)
DataFrames understøtter handlinger som filtrering, sammenlægning og tilmelding, som er afgørende for dataudforskning.
Du kan f.eks. filtrere en DataFrame:
filtered_df = df.filter(df["Age"] > 30)
Azure Databricks understøtter også SQL ved at gøre det muligt at skifte mellem DataFrame-handlinger og SQL-forespørgsler for at interagere med dataene på en måde, der føles mest naturlig.
Hvis du vil filtrere DataFrame ved hjælp af en SQL-forespørgsel, skal du først oprette en midlertidig visning:
df.createOrReplaceTempView("people")
sql_df = spark.sql("SELECT Name, Age FROM people WHERE Age > 30")
Drikkepenge
Du kan få flere oplysninger om datarammer under Selvstudium: Indlæs og transformér data ved hjælp af Apache Spark DataFrames.
Udforsk data ved hjælp af biblioteker og API'er
Afhængigt af hvad du vil gøre med dine data, skal du bruge bestemte biblioteker og API'er til at give dig funktionaliteten til at udføre de ønskede databehandlingstrin.
Installér biblioteker med åben kildekode
Som dataanalytiker, datatekniker eller dataspecialist kan du bruge dine foretrukne biblioteker med åben kildekode til at udforske og behandle data. Azure Databricks giver dig mulighed for at installere Python-biblioteker som Pandas, NumPy eller Scikit-learn for at få yderligere dataanalysefunktioner.
Drikkepenge
Du kan få flere oplysninger om at arbejde med biblioteker i Azure Databricks under Biblioteker.
Brug MLlib til arbejdsbelastninger i forbindelse med maskinel indlæring
Du kan oplære modeller til maskinel indlæring for at hjælpe dig med at udforske og behandle dine data. Med Sparks MLlib bruger du de distribuerede beregningsklynger, der er knyttet til dine notesbøger, optimalt. Med MLlib-biblioteket kan du anvende teknikker til maskinel indlæring, f.eks. klyngedannelse, regression og klassificering, hvilket hjælper dig med at afdække skjulte og komplekse mønstre i dine data.
Visualiser data med eksterne visualiseringsværktøjer
Ud over indbyggede diagramindstillinger kan Azure Databricks integreres med eksterne visualiseringsværktøjer som Tableau eller Power BI for at få forbedrede dashboardfunktioner.
Du kan oprette forbindelse mellem Power BI Desktop og Azure Databricks-klynger og Databricks SQL-lagersteder. Du kan også publicere Power BI-rapporter til Power BI-tjeneste og give brugerne adgang til de underliggende Azure Databricks-data ved hjælp af enkeltlogon (SSO) og videregive de samme Microsoft Entra ID-legitimationsoplysninger, som de bruger til at få adgang til rapporten.

Der er flere metoder til at oprette forbindelse mellem Azure Databricks fra Power BI Desktop:
Opret forbindelse til Azure Databricks ved hjælp af Partner Connect: En guidet konfiguration i Databricks, der automatisk konfigurerer Power BI til at oprette forbindelse til dit Databricks SQL-lager med minimale manuelle trin.
Opret forbindelse til Azure Databricks manuelt: En manuel proces, hvor du bruger Power BI Databricks-connectoren, angiver arbejdsområdets SQL-lagerstedsslutpunkt og godkender for at oprette forbindelsen.
Power BI Delta Sharing-connector: En connector, der gør det muligt for Power BI at forespørge på delte Delta-tabeller via Delta-deling uden at kræve direkte adgang til Databricks-arbejdsområdet eller -klyngen.
Udforsk data i SQL-editoren
SQL-editoren i Azure Databricks er et arbejdsområde, hvor du kan skrive og køre SQL-forespørgsler mod dataene i dit søhus. Den understøtter standard SQL-kommandoer og indeholder nyttige funktioner som syntaksfremhævning, autofuldførelse og en historik over dine tidligere forespørgsler. Dette gør det nemmere at afprøve forespørgsler, forfine dem og holde styr på det, du allerede har udforsket.
Hvis du vil begynde at udforske, kan du bruge ruden Katalogoversigt til at se tilgængelige databaser, skemaer og tabeller. Når du vælger en tabel, vises dens kolonner og datatyper, så du kan forstå strukturen, før du kører forespørgsler. Derfra kan du skrive forespørgsler for at få vist eksempelrækker, filtrere resultater eller anvende sammenlægninger for at få en hurtig fornemmelse af dataenes indhold og kvalitet. Resultaterne vises som standard i et tabelformat, men du kan også se dem som simple diagrammer for at få øje på mønstre eller tendenser.

SQL-editoren giver dig også mulighed for at gemme forespørgsler til senere brug og organisere dem til gentagelig udforskning. Du kan tilpasse gemte forespørgsler ved at tilføje parametre eller dele dem med teammedlemmer, der arbejder på de samme data. Hvis du har brug for resultater regelmæssigt, kan du planlægge forespørgsler eller føje dem til dashboards for at få nemmere adgang. Med disse funktioner giver SQL-editoren en praktisk måde at undersøge, forespørge på og analysere dine data på uden at forlade Databricks.
Disse værktøjer gør Azure Databricks til en fleksibel platform til dataudforskning, der håndterer alt fra grundlæggende datarensning til avancerede projekter til maskinel indlæring.