Lagre og udvikling baseret på stammen
Mange dataeksperter foretrækker at arbejde med Python eller R for at definere arbejdsbelastninger til maskinel indlæring. Du kan have Jupyter-notesbøger eller scripts til at forberede data eller oplære en model.
Det bliver nemmere at arbejde med kodeaktiver, når du bruger versionsstyring. Versionsstyring er den praksis, at administrerer kode og sporer eventuelle ændringer dit team foretager i koden.
Hvis du arbejder med DevOps-værktøjer, f.eks. Azure DevOps eller GitHub-, gemmes koden i et såkaldt lager eller lager.
Repository
Når du konfigurerer MLOps-strukturen, vil en maskinel indlæringstekniker sandsynligvis oprette lageret. Uanset om du vælger at bruge Azure Repos i Azure DevOps eller GitHub-lagre, bruger begge Git-lagre til at gemme din kode.
Der er generelt to måder, lageret kan begrænses på:
- Monorepo-: Hold alle arbejdsbelastninger til maskinel indlæring inden for det samme lager.
- Flere lagre: Opret et separat lager for hvert nye projekt til maskinel indlæring.
Hvilken tilgang dit team foretrækker, afhænger af, hvem der skal have adgang til hvilke aktiver. Hvis du vil sikre hurtig adgang til alle kodeaktiver, kan monorepos passe bedre til dit teams krav. Hvis du kun vil give personer adgang til et projekt, hvis de arbejder aktivt på det, foretrækker dit team muligvis at arbejde med flere lagre. Vær opmærksom på, at administration af adgangskontrol kan medføre flere omkostninger.
Strukturér dit lager
Uanset hvilken fremgangsmåde du bruger, er det bedste praksis at blive enige om standardmappestrukturen på øverste niveau for dine projekter. Du kan f.eks. have følgende mapper i alle dine lagre:
-
.cloud: indeholder cloudspecifik kode, f.eks. skabeloner til oprettelse af et Azure Machine Learning-arbejdsområde. -
.ad/.github: indeholder Azure DevOps- eller GitHub-artefakter som YAML-pipelines for at automatisere arbejdsprocesser. -
src: indeholder enhver kode (Python- eller R-scripts), der bruges til arbejdsbelastninger i maskinel indlæring, f.eks. forbehandling af data eller modeltræning. -
docs: indeholder markdown-filer eller anden dokumentation, der bruges til at beskrive projektet. -
pipelines: indeholder definitioner af Azure Machine Learning-pipelines. -
tests: indeholder enheds- og integrationstest, der bruges til at registrere fejl og problemer i din kode. -
notebooks: indeholder Jupyter-notesbøger, der primært bruges til eksperimenter.
Seddel
Oplæringsdata bør ikke inkluderes i dit lager. Dataene skal gemmes i en database eller datasø. Azure Machine Learning kan have direkte adgang til en database eller en datasø ved at gemme forbindelsesoplysningerne som et datalager.
Ved at have en standardstruktur, som hvert projekt bruger, vil dataforskere og andre samarbejdspartnere finde det nemmere at finde den kode, de skal arbejde med.
Drikkepenge
Find flere bedste praksis for strukturering af datavidenskabelige projekter.
Hvis du vil vide mere om, hvordan du arbejder med lagre som dataforsker, får du mere at vide om trunkbaseret udvikling.
Trunkbaseret udvikling
De fleste softwareudviklingsprojekter bruger Git som et kildekontrolsystem, som bruges af både Azure DevOps og GitHub.
Den største fordel ved at bruge Git er det nemme samarbejde om kode, samtidig med at du holder styr på eventuelle ændringer, der foretages. Derudover kan du tilføje godkendelsesporte for at sikre, at det kun er ændringer, der er blevet gennemgået og accepteret, der foretages i produktionskoden.
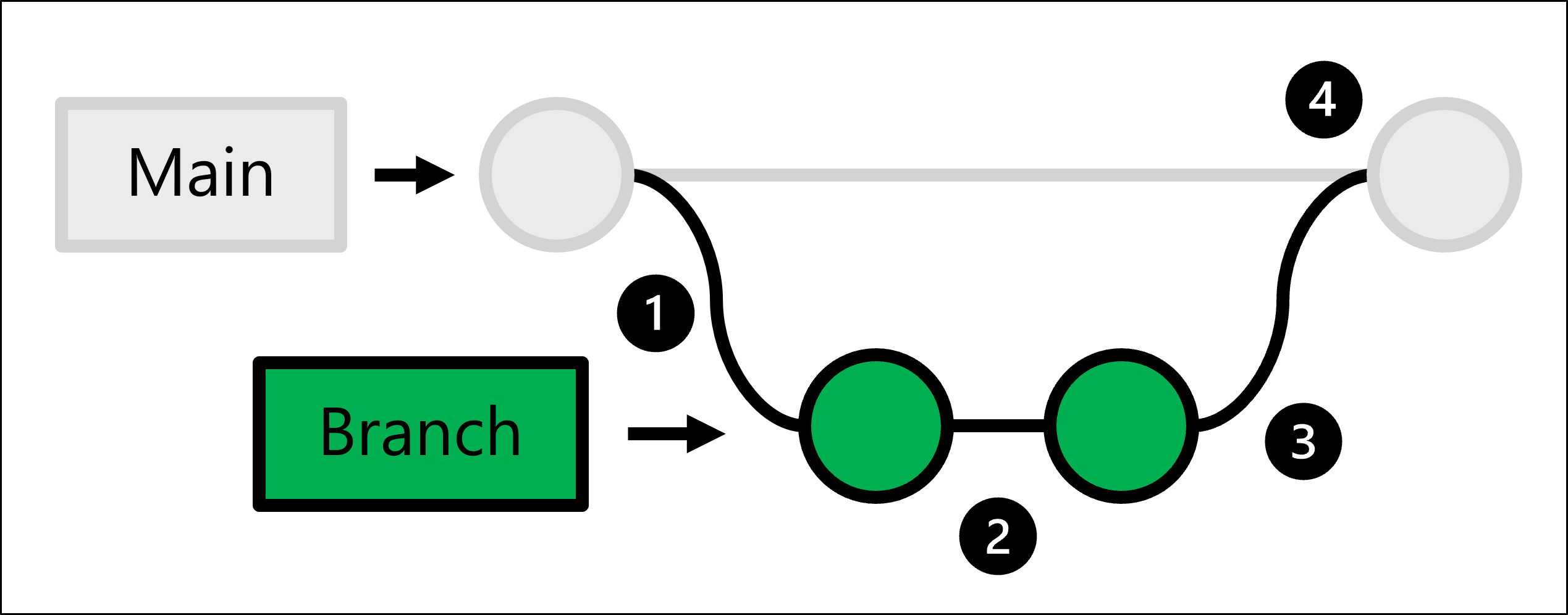
For at opnå ovenstående gør Git brug af trunkbaseret udvikling, som giver dig mulighed for at oprette forgreninger.
Produktionskoden hostes i forgreningen . Når nogen vil foretage en ændring:
- Du kan oprette en komplet kopi af produktionskoden ved at oprette en forgrening.
- I den forgrening, du har oprettet, foretager du eventuelle ændringer og tester dem.
- Når ændringerne i din forgrening er klar, kan du bede nogen om at gennemse ændringerne.
- Hvis ændringerne godkendes, du flette den forgrening, du oprettede med hovedindlægget, og produktionskoden opdateres, så den afspejler dine ændringer.